






或为什么我们建立自己的图形数据库
弗朗西斯科·桑托斯和索非亚·戈麦斯
欺诈是一个复杂的话题。它具有多种形状,并且随着时间不断发展。虽然最先进的模型可以在几毫秒内轻松捕获最常见的欺诈模式,但是最复杂的欺诈和反洗钱(AML)方案涉及许多相互交织的攻击和当事方,并且需要补充工具来防御我们的客户。
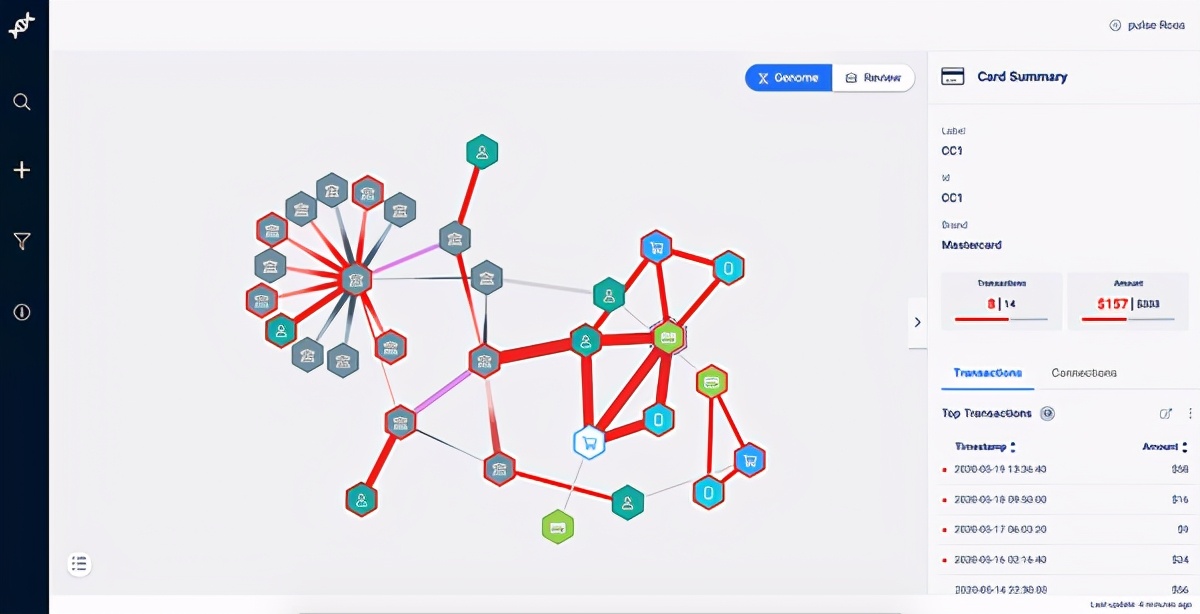
Genome是Feedzai堆栈上可用的此类工具之一。Feedzai Genome是一项创新的新产品,可帮助欺诈分析人员和调查人员使用链接分析来发现和可视化复杂的金融犯罪模式。
我们的客户对基因组的热爱与我们对基因组的热爱一样。我们最近发布了Genome v2,它在Genome v1的基础上进行了重大改进。它的核心改进是新的图形存储系统,在此系统中,我们大大提高了图形查询的性能。
通过彻底的大修,Genome V2专注于通过更大的数据配置文件激活客户的能力,从而实现性能的巨大飞跃并提高可用性。

我们是如何做到的?剧透警报:我们建立了自己的图形数据库!在这篇文章中,我们解释了为什么以及如何做到这一点。
基因组v1
与任何最低可行产品(MVP)一样,为了快速,廉价地构建Genome v1,我们重用了现有Feedzai堆栈的某些组件。结果,Genome v1存储建立在另一个Feedzai的组件数据库系统上。尽管不理想,但这对于展示基因组,展示其价值以及与客户合作以更好地了解我们需要构建的产品是必要的。
Genome v1在检测复杂欺诈模式和发现重要欺诈环方面取得了重大成功。最大的挑战?它无法缩放,而且某些最重要的操作也非常缓慢,即使对于小型图形也是如此。
本机图数据库
从一开始,我们就知道我们需要一个不同的存储系统来支持Genome的前端。在Feedzai,我们始终努力避免重新发明轮子,并以可用的最佳解决方案为基础。
我们意识到,某些最慢的查询是“图形查询”-例如,扩展节点以查找其邻居(可能是某些节点或关系属性的条件)或计算节点的程度。
因此,显而易见的步骤是研究本机Graph数据库(Graph DB)的概况。我们探索了许多解决方案,包括:
Neo4jRedisGraphJanusGraph
为了测试它们,我们首先定义需要支持的最常见的操作和查询。它们包括上述的图查询,还包括其他常规查询,例如查找特定节点(使用ID或其他特定属性)或查找给定节点的所有属性(通过ID)。
接下来,我们使用这些查询来评估系统以及一个小型数据集,该数据集包含约920万个节点,860万个边和1亿个属性。我们感到失望的是,没有一种解决方案适合于我们的预期用例。
Neo4j
Neo4j可能是当今最受欢迎的图形存储系统。它是用Java构建的,并且是开源的。它是成熟的Graph DBMS,支持ACID事务,多个用户的角色,授权策略和强大的查询语言。
当我们探索Neo4j时,它缺乏我们一个非常重要的功能:扩展能力。同时,Neo4j团队已经发布了Neo4j 4.0,它通过支持图形联合来解决此问题。
尽管有此限制,我们仍然决定在单个节点上对其进行测试,但结果令人失望。即使在较小的数据集上,有条件地扩展节点也可能需要大约1.5–3s,而计算节点的度数可能需要超过3s。诸如查询给定类型的节点ID的所有属性之类的图形操作较少,大约需要9s。
RedisGraph
在Neo4j的性能令人失望之后,我们对RedisLabs的模块RedisGraph进行了测试,该模块基于惊人的GraphBlas库,该库将大多数图形操作视为线性代数。我们测试了RedisGraph v1.2,它声称比其他解决方案快600倍。
结果确实比Neo4j好得多。有条件地扩展将花费0.3-1.3s,并计算大约0.6s的节点度。我们的另一个查询,查找给定类型的节点的所有属性现在将花费0.5s。
尽管结果很好,但是RedisGraph有一个主要限制:它不能水平缩放。由于RedisGraph与Redis一样需要将所有数据加载到内存中,因此这是一个严重的问题。即使使用非常高效的内存管理,这也将需要功能强大且昂贵的机器,即使在这些机器上,我们也无法满足多个用例。
最重要的是,由于存在多个问题和不稳定问题,我们认为该解决方案仍然不成熟。同时,RedisGraph启动了v2,它可以解决其中的一些问题并使RedisGraph更快。但是,其核心问题-可伸缩性-尚未解决。
JanusGraph
我们留下了最有希望的解决方案,最后进行测试。JanusGraph是基于Java构建的分布式,开放源图形数据库。在功能方面,它打勾了所有框,因此我们很高兴尝试一下。JanusGraph可以插入多个后端,例如HBase,BigTable或Cassandra。我们使用Cassandra对其进行了测试。
由于我们知道JanusGraph是我们最有前途的选择,因此我们花了数周的时间学习如何针对查询优化JanusGraph。JanusGraph在其中几个方面的性能优于RedisGraph v1.2。有条件地扩展节点需要20到50毫秒,找到一个节点的程度约为7毫秒。
但是,我们发现其他类似图形的操作(例如简单搜索)妨碍了我们的性能,并经常导致超时。对于我们而言,搜索是一笔不小的交易,因为这是欺诈分析师开始Genome会话的主要方式。我们试图克服这一问题,但是最好的解决方案要求我们使用其他组件,这使得我们的解决方案的维护和开发成本非常高。
重新评估我们的选择
在这个阶段,我们对如何前进感到困惑。我们不能接受没有可供我们使用的图存储解决方案。因此,我们着手研究其他公司如何解决这个问题。这是我们发现的:
如您所见,所有这些公司都使用知名技术开发了自己的Graph DB解决方案。每家公司内外都知道自己的用例,因此有意义的是,每个人都可以为自己开发一个出色的Graph DB。这种观察将我们带入了下一步的旅程:构建自己的Graph DB解决方案。

基因组图数据库
为了构建Graph数据库,我们研究了Genome的两种操作。首先是搜索特定的节点和边。第二个是用于条件扩展和节点度计算的图形操作。欺诈分析师通常会通过搜索开始Genome会话,然后使用图操作继续进行探索。
结果,我们定义了针对这两个操作优化的数据模型。一方面,它可以回答有关节点(我们的实体和属性)和边缘(节点之间的相互关系及其属性)的查询。另一方面,这种具有边和节点的数据模型使我们能够非常快速地执行图操作(例如展开)。
与LinkedIn,Twitter或Facebook相似,我们选择了RDBMS作为Graph DB的基础引擎。在我们的例子中,我们使用PostgreSQL,因为它已在Feedzai堆栈中使用。我们还探索了Cassandra作为可能的替代方法,但是它为一般搜索查询提供了更少的灵活性,并且由于我们的图形操作还需要其他查询来检索属性,因此大多数图形操作的性能通常较差。
我们在PostgreSQL中的解决方案-Genome V2-获取原始数据并将其转换为聚合数据,存储到包含节点和边的多个表中。此外,我们按类型划分节点和边,以支持数据分片和可伸缩性。
总之,在所有类别中,Genome V2均比Genome V1快。就搜索操作而言,它比Genome V1快37倍,就图形操作而言,它比Genome V1快131倍。
总结
本机图数据库是不错的通用解决方案,在过去几年中已经获得了很大的普及。尽管这些解决方案已经发生了巨大的发展,但它们仍然缺乏大型数据集的成熟度和性能,这迫使我们构建自己的图存储,专门针对应用程序的需求量身定制。
随着新图形数据库的开发,这种情况将来可能会进一步发展。无论使用哪种工具,我们都将继续开发Genome之类的产品,并尽最大努力为客户提供最佳性能和功能。
从角度来看,在Genome V1中,对于一个标准银行,我们只能处理1周的数据,而现在,我们可以轻松处理6个月以上的数据,以及数十亿个节点和边缘。这为基因组创造了一个新的世界,使我们的客户能够探索和了解更好的欺诈模式,而这些模式以前是不可见的。















 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









