







Hadoopwith Eclipse on Windows 7. 1
Hadoop with Eclipse on Windows 7
目的:为了更好的理解,调试hadoop,在本地windows 7 上部署hadoop,local运行,伪分布式方式工作。
一、软件下载
(因为本机是64位系统,所以都是下载的64位)
1.jdk-8u25-windows-x64.exe (MapReduce 程序的编写和Hadoop 的编译都依赖于JDK,所以直接安装JDK。JDK安装包括了JRE)。
2.eclipse-java-indigo-SR2-win32-x86_64 (不要用eclipse-java-luna-SR1-win32-x86_64。因为插件兼容有问题。我把hadoop 0.20 contrib里的eclipse hadoop插件复制到eclipse plugings目录下。但是在eclipse里没有找到map/reduce视图。
3.cygwin http://www.cygwin.cn/setup.exe
4. hadoop-0.20.2.tar.gz
Hadoop要求 JDK 必须是1.6 或以上版本。Hadoop和Eclipse3.3.2后面版本可能有插件兼容性问题。
二、软件安装
1. java安装
不建议只安装JRE,而是建议直接安装JDK,因为安装JDK 时,可以同时安装JRE。
MapReduce 程序的编写和Hadoop 的编译都依赖于JDK,光JRE 是不够的。
安装目录最好不要包含空格。以免后续麻烦。比如hadoop的脚本处理空格可能出错。当然有空格也有解决办法。
安装后设置系统环境变量:
增加JAVA_HOME, C:\Java\jdk1.8.0_25
PATH里在开头加入 %Java_Home%\bin;%Java_Home%\jre\bin;
CLASSPATH .;%JAVA_HOME%\bin;%Java_Home%\lib\dt.jar;%Java_Home%\lib\tools.jar
cmd命令行运行 java -version 可以看到版本信息就算安装成功了。
2. Cygwin安装
以管理员身份运行setup.exe。

不建议使用Windows“域用户”配置和运行Cygwin,由于公司防火墙等原因,容易遇
到一些较难解决的问题。另外,如果运行Cygwin 的用户和登录Windows 的用户不同,则需要将Cygwin 安装目录及子目录的拥有者(Owner)。
镜像选用的http://mirrors.163.com/cygwin/ 速度比较快!
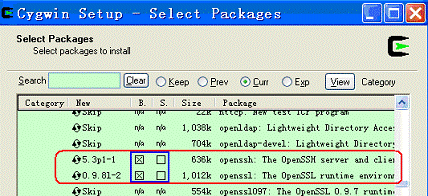
在“SelectPackages”对话框中,必须保证“NetCategory”下的openssh,,openssl被安装:
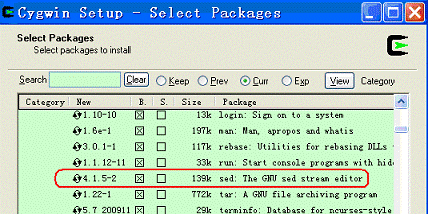
如果还打算在eclipse 上编译Hadoop,则还必须安装“Base Category”下的“sed”:
PATH环境变量添加上C:\cygwin64\bin;C:\cygwin64\usr\bin;
接下来安装ssh。在SYSTEM账户下运行的sshd服务需要有改变user id的特权。hadoop集群的namenode需要免密码登陆datanode。所以
Cygwin在win 7上安装ssh时 注意
1. 要以管理员身份运行cygwin
运行命令ssh-host-config
2. 要注意看提示信息。各个版本可能有些不同。
如果允许免密码登陆,则关闭StrictModes (yes/no) no
*** Query: Do you want to install sshd as aservice?
yes
*** Query: Enter the value of CYGWIN forthe daemon: []ntsec
*** Info: On Windows Server 2003, Windows Vista, and above, the
*** Info: SYSTEM account cannot setuid toother users -- a capability
*** Info: sshd requires. You need to have or to create a privileged
*** Info: account. This script will help you do so.
*** Info: You appear to be running Windows2003 Server or later. On 2003
*** Info: and later systems, it's notpossible to use the LocalSystem
*** Info: account for services that canchange the user id without an
*** Info: explicit password (such aspasswordless logins [e.g. public key
*** Info: authentication] via sshd).
*** Info: If you want to enable thatfunctionality, it's required to create
*** Info: a new account with specialprivileges (unless a similar account
*** Info: already exists). This account isthen used to run these special
*** Info: servers.
*** Info: Note that creating a new userrequires that the current account
*** Info: have Administrator privilegesitself.
*** Info: No privileged account could befound.
*** Info: This script plans to use'cyg_server'.
*** Info: 'cyg_server' will only be used byregistered services.
*** Query: Do you want to use a differentname? (yes/no) no
*** Query: Create new privileged useraccount 'cyg_server'? (yes/no) yes
安装了sshd后,在计算机管理里启动CYGWIN sshd服务。
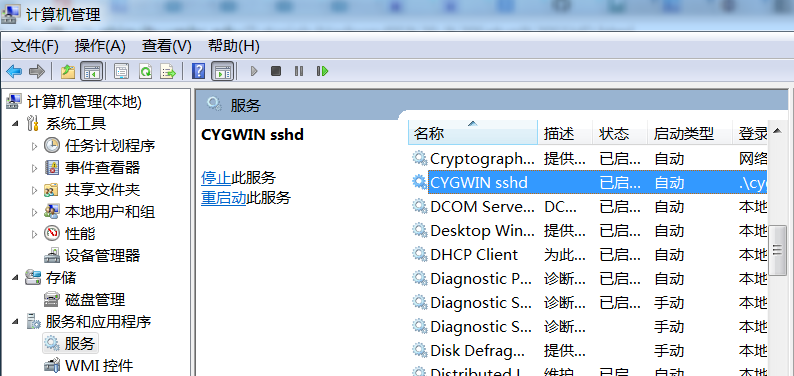
3. 配置ssh免密码登陆 授权
在cygwin窗口运行ssh-keygen生成密钥文件,一路直接回车即可,如果不出错,应当是需要三次按回车键。按如下命令生成authorized_keys 文件:
cd ~/..ssh/
cp id_rsa.pub authorized_keys
完成上述操作后,执行exit命令先退出Cygwin 窗口,如果不执行这一步操作,下面的
操作可能会遇到错误。
接下来,重新运行Cygwin,执行ssh localhost 命令。如果不需要输入密码就登录成功表明配置成功。
3. 安装hadoop
将hadoop 安装包hadoop-0.20.1.tar.gz解压到D:\hadoop\run目录( 可以修改成其它
目录)
修改conf下得配置文件。
l 修改hadoop-env.sh
只需要将JAVA_HOME 修改成JDK 的安装目录即可,需要注意两点:
(1) JDK 必须是1.6 或以上版本;
(2) 设置JDK 的安装目录时,路径不能是windows风格的目录(d:\java\jdk1.6.0_13),
而是LINUX 风格(/cygdrive/c/java/jdk1.8.0_25)。
在hadoop-env.sh中设定JDK 的安装目录:
export JAVA_HOME=/cygdrive/c/java/jdk1.8.0_25
Hadoop-env.sh可能是dos格式的,可能需要转换dos->unix格式 ,vim就可以转换。
vim/cygdrive/d/hadoop/run/conf/hadoop-env.sh (注意是cygdrive不是cygdriver)
:set fileformat=unix
:w
l 修改conf下配置文件
Hadoop会先读取core-default.xml。我们要修改的参数在core-site.xml里重新定义就行。
core-site.xml:
<configuration>
<!--- global properties -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
<description>A base for other temporarydirectories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://yu-PC:9000</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
theFileSystem implementation class. Theuri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
</configuration>
这里最好是用IP地址,但是我的机器每次拨号连接后地址都不同。所以就用hostname yu-PC来代替了localhost.
hdfs-site.xml:( replication默认为3,如果不修改,datanode 少于三台就会报错)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>yu-PC:9001</value>
</property>
</configuration>
三、运行hadoop
进入hadoop bin目录,首先格式化文件系统:
$ hadoop namenode –format
启动Hadoop:
$ start-all.sh
$ jps查看Namenode和jobtracker进程
$ ./hadoop fs -ls /
Found 1 items
drwxr-xr-x - yu-pc\yu supergroup 02014-12-04 11:11 /tmp
说明hadoop成功安装了。。。
查看集群状态:$hadoop dfsadmin -report
Hadoop 的web 方式查看hdfs:http://127.0.0.1:50070
查看job: http://127.0.0.1:50030
运行wordcount.java程序
(1)先在本地磁盘建立两个输入文件file01 和file02:
$ echo “Hello World Bye World” > file01
$ echo “Hello Hadoop Goodbye Hadoop” >file02
(2)在hdfs 中建立一个input 目录:$ hadoop fs –mkdir input
(3)将file01 和file02 拷贝到hdfs 中:
$ hadoop fs –copyFromLocal/home/hexianghui/soft/file0* input
(4)执行wordcount:
$ hadoop jar hadoop-0.20.1-examples.jarwordcount input output
(5)完成之后,查看结果:
$ hadoop fs -cat output/part-r-00000
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
Hadoop fs –rmr output
Hadoop fs –rmr input
删除目录
Hadoop fs –rm /input/local*
删除文件。可以使用通配符。
错误集合
1. ERROR 1: ipc.Client: Retrying connect toserver
bin/start-all.sh启动hadoop成功后,
bin/hadoop fs –ls /查看根目录出错:
INFO ipc.Client: Retrying connect toserver: localhost/127.0.0.1:8888. Already tried 9 time(s).
Bad connection to FS.
hadoop安装完成后,必须要用hadoop namenode -format格式化后,才能使用,如果重启机器,在启动hadoop后,用hadoop fs-ls命令老是报 10/09/2518:35:29 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000.Already tried 0 time(s).的错误,
用jps命令,也看不不到namenode的进程, 必须再用命令hadoop namenode format格式化后,才能再使用
原因是:hadoop默认配置是把一些tmp文件放在/tmp目录下,重启系统后,tmp目录下的东西被清除,所以报错
解决方法:
1)在conf/core-site.xml (0.19.2版本的为conf/hadoop-site.xml)中增加以下内容
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
<description>Abase for other temporary directories</description>
</property>
2) 再用hadoop namenode -format格式化。看到shutdown namenode信息带的ip地址。用这个ip地址修改conf/core-site.xml(0.19.2版本的为conf/hadoop-site.xml)fs.default.name将其中的
<value>hdfs://localhost:8888</value>
改为
<value>hdfs://<你自己的本机IP>:8888</value>
3)再重启下hadoop。
4)用Jps命令可以查看到Namenode和jobtracker进程了。
2. ERROR 2: hadoop fs –put出错could only be replicated to 0 nodes, instead of 1
网上查找原因,有这样的解决办法:
You'll probably find that even though thename node starts, it doesn't have any data nodes and is completely empty.Whenever hadoop creates a new filesystem, it assigns a large random number toit to prevent you from mixing datanodes from different filesystems on accident.When you reformat the name node its FS has one ID, but your data nodes stillhave chunks of the old FS with a different ID and so will refuse to connect tothe namenode. You need to make sure these are cleaned up before reformatting.You can do it just by deleting the data node directory, although there'sprobably a more "official" way to do it.
这个原因是执行如下命令导致的:
$hadoop namenode -format
解决办法是删除掉data.dir目录,我查了一下,删除的是如下这个目录
/${hadoop.tmp.dir}/dfs/data,也就是hdfs-site.xml的dfs.data.dir所配置的目录
然后 reformatnamenode,问题解决。也就是再重新执行$hadoopnamenode -format
但是我发现用hadoopfs –rmr tmp没有删除干净。
所以直接到windows里找到对应的目录删除掉。
然后在cygwin里重新执行
stop-all.sh,
Hadoop namenode –format
Start-all.sh
然后去看看localhost:50070里live nodes不再是0,是不是有一个了?
有人建议把hdfs-site.xml的dfs.data.dir所配置的目录和hadoop.tmp.dir目录分开
hadoop配置的建议
hadoop默认的dfs是放在tmp文件夹下的。网上有建议分开放,这样的话,tmp文件夹删掉时,namenode不需要重新格式化,hdfs的文件信息也保留。
Core-site.xml:
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
</property>
Hdfs-site.xml:
<property>
<name>dfs.name.dir</name>
<value>/var/filesystem/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/var/filesystem//data</value>
</property>















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









