









一、目的及意义
- 学会搭建伪分布式集群环境,以便于理解MapReduce及HDFS;
- 学会使用eclipse直接与伪分布式集群进行连接,以便于直接向集群提交作业;
现在网络上的文章多是介绍上述两点中的一点,例如:
a、如何搭建伪分布式集群;
b、如何在eclipse中连接已建立好的伪分布式集群;
c、大部分介绍都是基于hadoop1.x系列。本文内容
a、较详细列出在CentOS中搭建伪分布式集群
b、详细给出Windows中的Eclipse与伪分布式集群的连接过程;
c、采用hadoop2.x系列。
二、软件列表
| 序号 | 软件名称 | 功能 |
|---|---|---|
| 1 | hadoop-2.6.0-x64.tar.gz | 实现分布式计算,下载 |
| 2 | eclipse kepler | 集成开发平台,下载 |
| 3 | hadoop-eclipse-kepler-plugin-2.4.1 | 用于连接eclipse与hadoop,下载 |
| 4 | jdk1.7.0_79 | 解释器,windows版64位,Linux版 |
三、安装步骤
1、Windows下Hadoop开发环境的安装及配置
Java安装及环境变量配置
Windows下与linux下都需要安装Java,配置java环境变量。参考: windows以及Linux下java1.7.x的安装与配置
CentOS下安装JDK的三种方法
eclipse及hadoop-eclipse-kepler-plugin插件安装
eclipse是绿色版的,下载后解压即可使用,然后将hadoop-eclipse-kepler-plugin插件拷贝到eclipse文件夹下的plugins文件夹下即可。
a、Windows下设置hadoop环境变量
变量名称:HADOOP_HOME
变量内容:hadoop的解压后的文件夹,如:D:\hadoop-2.6.0
b、运行eclipse文件
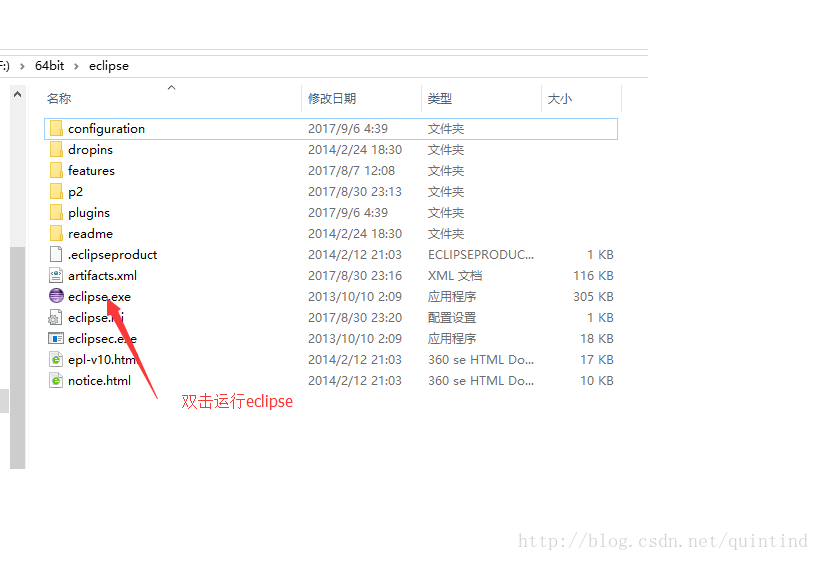
c、指定hadoop的路径
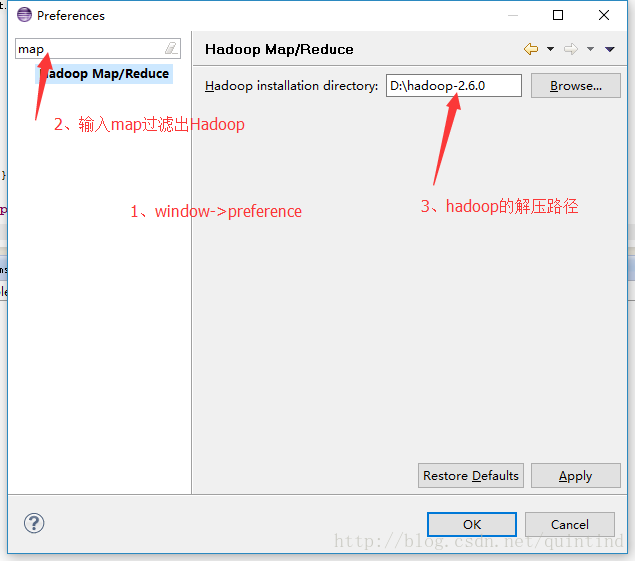
d、若preference中没有发现hadoop Map/Reduce选项,说明插件没有被eclipse发现并加载到eclipse环境中,可参考如下步骤解决:
- 创建一个 Eclipse 快捷启动方式,右键单击快捷方式->选属性->在目标栏中加入一个“ -clean ”参数(前面有个空格),如果启动 eclipse 后找到你所安装的新插件后,在下次启动之前把参数 clean 去掉就可以了。
- 把eclipse安装目录下的configuration/org.eclipse.update和runtime的目录整个删除,重启eclipse。(org.eclipse.update 文件夹下记录了插件的历史更新情况,它只记忆了以前的插件更新情况,而新安装的插件它并不记录,所以删除掉这个文件夹就可以解决这个问题了,不过删除掉这个文件夹后, eclipse 会重新扫描所有的插件,此时再重新启动 eclipse 时可能会比刚才稍微慢点)
- 如果 Eclipse 启动还是找不到插件的话,在 eclipse/configuration 目录下的 config.ini 文件中加入一行 : osgi.checkConfiguration=true 这样它就会寻找并安装插件。注意找到插件后可以把该行注释掉 ( 去掉 ), 这样以后每次启动就不会因为寻找插件而显得慢了。
本地开发环境配置
a、File->New Project->Map/Reduce Project
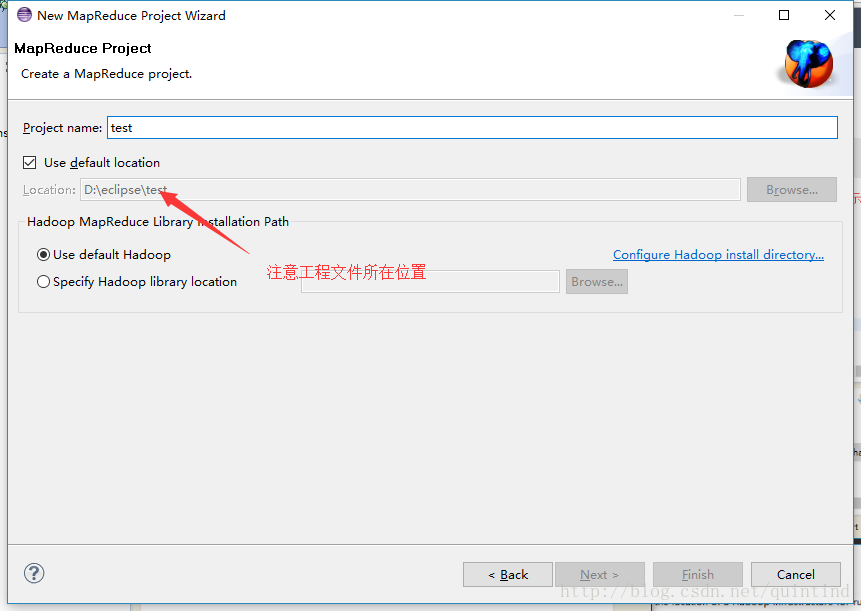
b、导入运行MapReduce所需的外部jar包
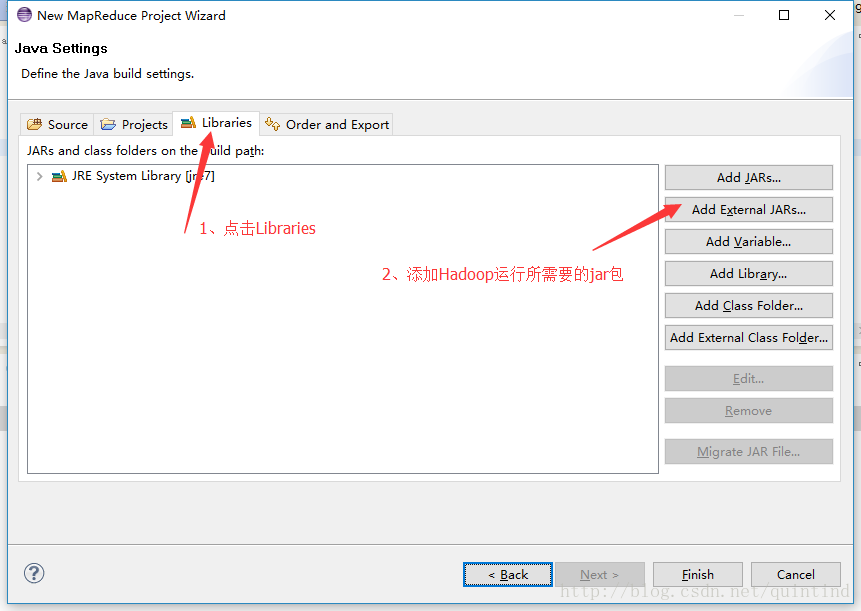
分别导入以下文件夹下的包:
- hadoop-2.6.0/share/hadoop/mapreduce下的所有jar包(子文件夹下的jar包不用)
- hadoop-2.6.0/share/hadoop/common下的hadoop-common-2.6.0.jar
- hadoop-2.6.0/share/hadoop/common/lib下的所有包
- hadoop-2.6.0/share/hadoop/yarn下的所有包(子文件夹下的jar包不用)
- hadoop-2.6.0/share/hadoop/hdfs下的hadoop-hdfs-2.6.0.jar
- 注意:上述文件夹下有些包用不着,初学者不好区分,所以都加载进来。
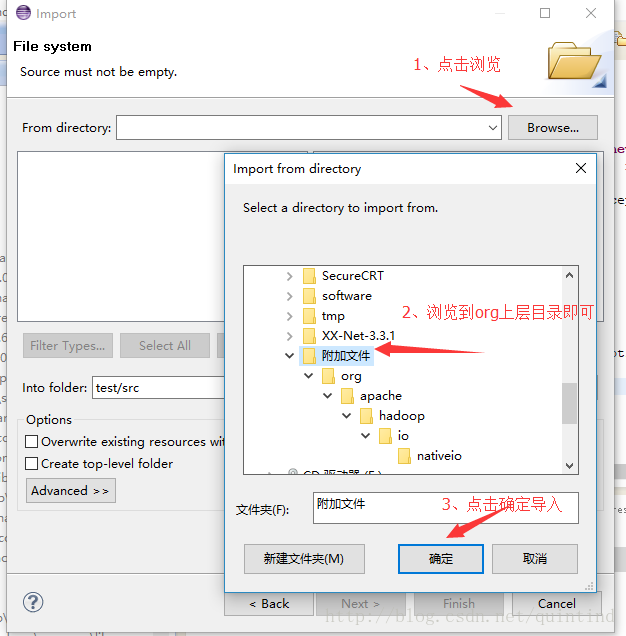
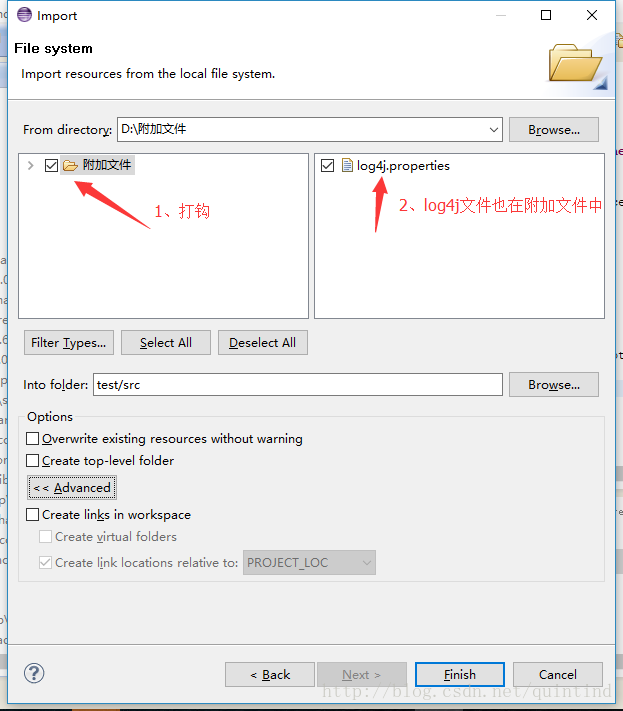
c、导入两个外部文件到项目src文件夹中。
假设org文件夹以及log4j.properties文件存在于一个“附加文件”中。
右键单击src->import->File system->附加文件
d、下载压缩文件hadoop-common-2.2.0-bin解压后将winutils.exe文件加入到目录hadoop-2.6.0/bin下,将hadoop.dll文件加入到Windows下目录C:\Windows\System32,重启计算机后生效。hadoop-common-2.2.0-bin该文件对应的是64位版的Hadoop,若Hadoop是32位版的,请自行下载相应的32位版的文件。
2、Linux中安装伪分布式集群
a、通过winscp将hadoop2.6.0.tar.gz拷贝到Linux文件目录/opt;
b、解压“tar -zxvf hadoop-2.6.0-x64.tar.gz”;
c、进入到目录/opt/hadoop-2.6.0/etc/hadoop下,按如下要求修改下列文件。
- hadoop-env.sh文件中配置Java环境变量,假设Java的安装路径为/usr/lib/jvm/jdk1.7.0_79
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_79- 将mapred-site.xml.template更名为mapred-site.xml
更改文件中内容,指定mapreduce的调度器为yarn。
<configuration>
<!-- mapred-site.xml -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
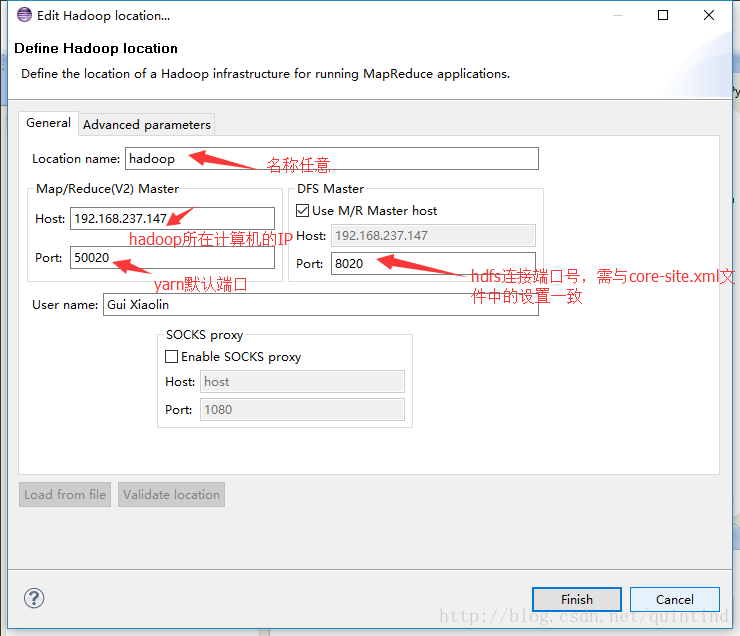
</configuration>- 在core-site.xml文件中增加如下内容,指定hdfs文件系统所在位置。
<!-- core-site.xml -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.237.147:8020</value>
<!-- 此IP地址是自己系统环境的IP -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop-tmp</value>
<!-- 设置一个不会被linux定期删除的文件夹,默认情况下namenode和datanode的文件都会存在这个目录下 -->
</property>
</configuration>- 在yarn-site.xml文件中增加如下内容
<configuration>
<!-- yarn-site.xml -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<!-- yarn的shuffle -->
</property>
</configuration>- hdfs-site.xml文件中增加如下内容,指定hdfs中文件备份数量。
<configuration>
<!-- hdfs-site.xml -->
<property>
<name>dfs.replication</name>
<value>1</value>
<!-- 默认情况下,hdfs数据块的副本数是3,在集群规模小于3的集群中,默认参数会导致错误,所以调整为1 -->
</property>
</configuration>d、修改/etc/hosts文件,使得localhost对应于当前主机IP地址
192.168.237.147 localhoste、 修改/opt/hadoop2.6.0/etc/hadoop/slaves文件,文件内容如下:
192.168.237.147f、设置ssh免密码登陆(ssh软件连接远程计算机时无需输入密码)
生成免密码公密钥对,然后把公钥加入自己的授权文件中,完成本机对本机的免密码登录。(你要信任哪台计算机,就将这台计算机的公钥放入本机的信任列表中,Windows也类似的设置)
root用户环境下输入ssh-keygen -t rsa ,连续回车三次(会产生相应的目录和文件),然后做如下操作。
cd ~/.ssh/
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keysg、在root用户账号输入如下命令关闭防火墙
临时关闭(重启系统会打开):
service iptables stop 永久关闭(重启系统不会打开):
systemctl stop firewalldh、格式化hdfs,在该目录opt/hadoop-2.6.0输入如下命令
./bin/hadoop namenode -format倒数第四行出现 INFO util.ExitUtil: Exiting with status 0 ->说明格式化成功。
i、启动hdfs
./sbin/start-dfs.shj、启动yarn
./sbin/start-yarn.sh若一切正常,输入jps命令会看到如6项输出
[root@master hadoop-2.6.0]# jps
4722 NameNode
5208 NodeManager
4980 SecondaryNameNode
9553 Jps
3062 ResourceManager
4837 DataNode
[root@master hadoop-2.6.0]# 测试Hadoop自带的例子
[root@master hadoop-2.6.0]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB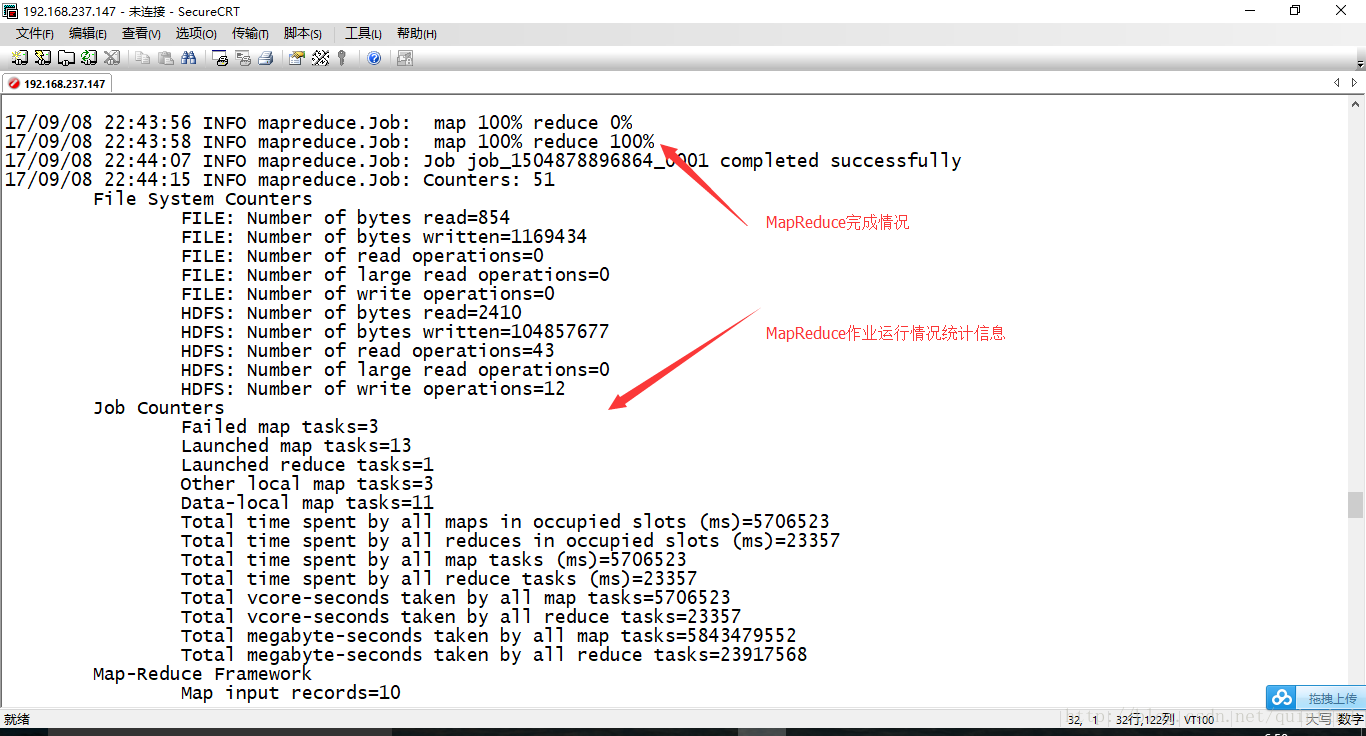
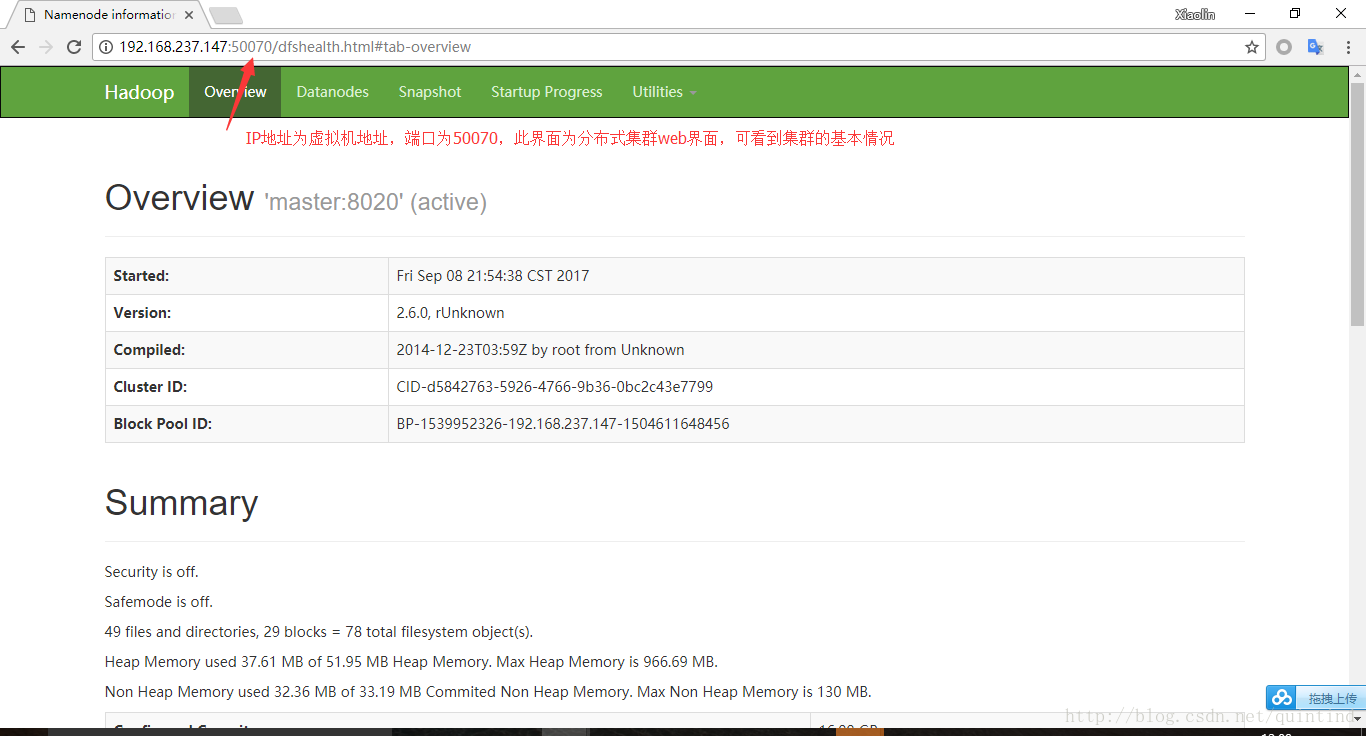
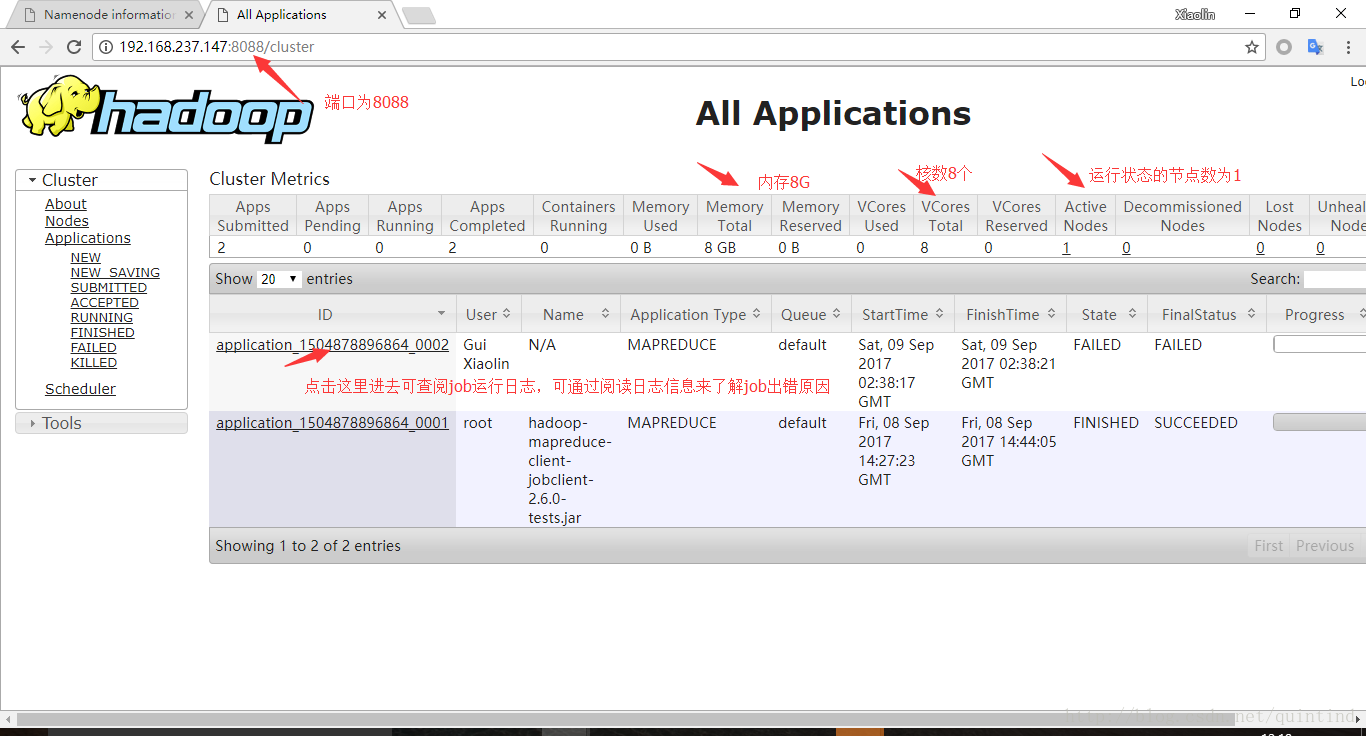
k、通过Windows的浏览器可查看集群基本状况,图像分别如下所示。
- http://192.168.237.147:50070 集群总体状况
- http://192.168.237.147:8088 集群作业监控web界面
l、设置Linux下hadoop的环境变量,以便快捷输入hadoop相关命令。
打开/etc/profile文件,在文件末尾增加如下内容
export PATH=$PATH:/opt/hadoop-2.6.0/bin:/opt/hadoop-2.6.0/sbin例如:没有设置上述环境变量之前,查看hadoop的hdfs文件系统需要输入以下命令
/opt/hadoop-2.6.0/bin/hadoop fs -ls /设置好环境变量之后,只需要输入
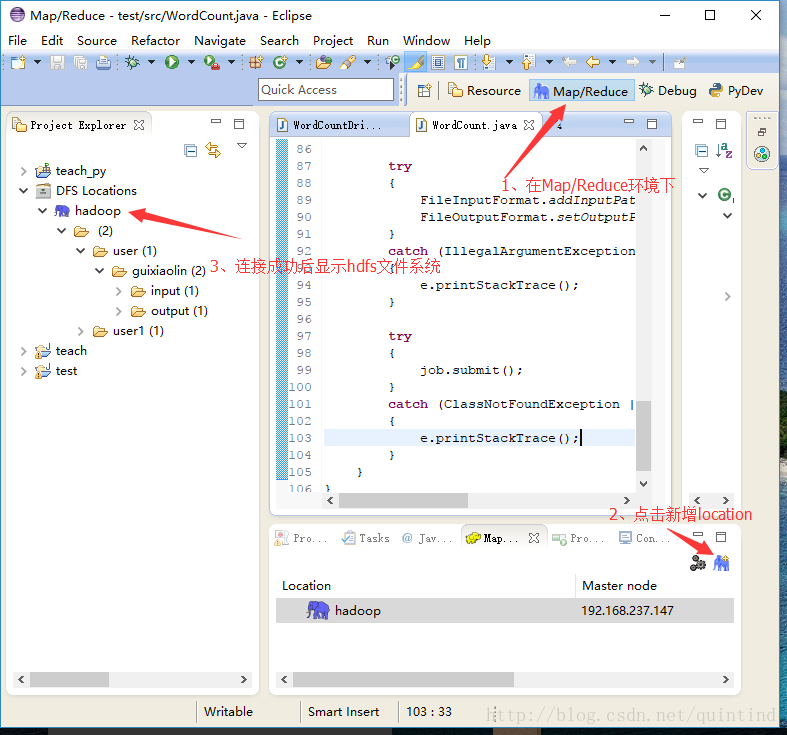
hadoop fs -ls /3、eclipse与伪分布式集群的连接
a、点击window->Perspective->Map/Reduce
4、 WordCount运行
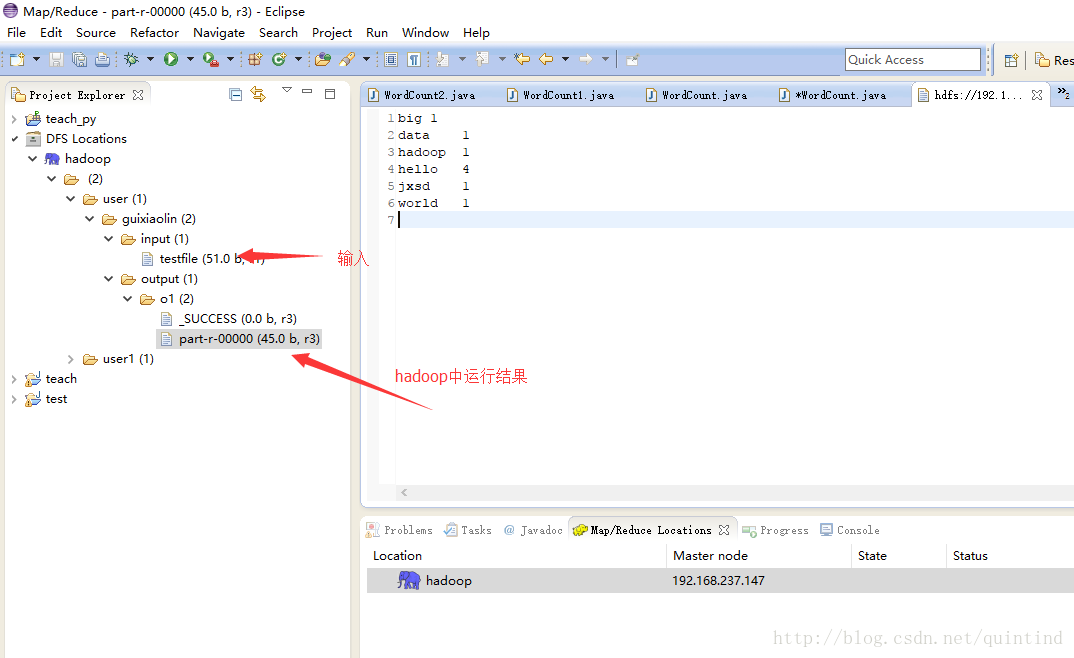
a、新建一个class命名为WordCount,假设WordCount的内容如下所示。
b、本地运行,点击run->run as Java Application
集群运行,点击run->run on hadoop,注意变换输入输出。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount
{
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
{
StringTokenizer tokenizer = new StringTokenizer(value.toString());
while (tokenizer.hasMoreTokens())
{
word.set(tokenizer.nextToken());
try
{
context.write(word, one);
}
catch (IOException | InterruptedException e)
{
e.printStackTrace();
}
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
try
{
context.write(key, result);
}
catch (IOException | InterruptedException e)
{
e.printStackTrace();
}
}
}
public static void main(String[] args)
{
Configuration conf = new Configuration();
Job job = null;
try
{
job = Job.getInstance(conf);
}
catch (IOException e)
{
e.printStackTrace();
}
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
try
{
FileInputFormat.addInputPath(job, new Path("F:/data/input/input.txt"));//输入在本地
FileOutputFormat.setOutputPath(job, new Path("F:/data/output/o1"));//输出在本地
// FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.237.147:8020/user/guixiaolin/input/testfile"));
// FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.237.147:8020/user/guixiaolin/output/o1"));
//输入输出在hdfs中
// FileInputFormat.addInputPath(job, new Path("F:/data/input/input.txt"));//输入在本地
// FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.237.147:8020/user/guixiaolin/output/o1"));//输出在hdfs
}
catch (IllegalArgumentException | IOException e)
{
e.printStackTrace();
}
try
{
job.submit();
}
catch (ClassNotFoundException | IOException | InterruptedException e)
{
e.printStackTrace();
}
}
}
注意事项
- Windows环境下eclipse与hadoop之间的关联需要一个插件,根据各自的环境不同,此插件可能还需要编译,详见插件编译;
- Windows环境下也需hadoop安装包,以便于开发;伪分布式环境下hadoop安装好后需要启动;且两个系统环境下的hadoop版本相同;
- 两个系统的Java版本需相同
参考资料:
Hadoop 2.0安装以及不停集群加datanode
hadoop自带例子wordcount的具体运行步骤
hadoop-2.6.0基准测试














 1189
1189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









