







sed - 过滤和转换文本的流编辑器
Sed是一个流编辑器。流编辑器用于在输入流上执行基本的文本转换(从管道中输入或输入)。在某种程度上,类似于编辑器,它允许脚本编辑(例如),sed工作只通过一个传递输入(s),从而更有效率,sed已经有能力在管道中过滤文本。
用法:[sed 选项 地址+命令 文件]
选项:
-n, --quiet, --silent 抑制模式空间的自动打印
-e script, --expression=script 将脚本添加到执行的命令中
-f script-file, --file=script-file 将script文件的内容添加到执行的命令中
--follow-symlinks 在处理的时候遵循symlinks
-i[SUFFIX], --in-place[=SUFFIX] 编辑文件(如果提供后缀),请进行备份
-l N, --line-length=N 为“l”命令指定所需的行包长度,默认长度为70
--posix有GNU扩展:
-E, -r, --regexp-extended 在脚本中使用扩展正则表达式(用于可移植性使用POSIX -E)。
-s, --separate 把文件看成单独的,而不是一个单一的连续长的流。
--sandbox operate in sandbox mode.在沙箱模式下操作。
-u, --unbuffered 从输入文件中加载最小数量的数据,并经常刷新输出缓冲区
-z, --null-data 由NUL字符分隔行
--help 展示这个帮助和退出
--version 输出版本信息和退出
命令:
地址adresses:
Sed命令可以在没有地址的情况下给出,可以对所有输入行执行命令;在一个地址中,有一个地址,在这种情况下,命令只对匹配这个地址的输入行执行;或者使用两个地址,在这种情况下,命令将执行所有的输入行,这些输入行将从第一个地址开始,并继续到第二个地址。关于地址范围的三件事:语法是addr1,addr2(即,地址由逗号分隔;addr1匹配的行将永远被接受,即使addr2选择较前一行;如果addr2是regexp,则不会对addr1匹配的行进行测试。
在地址(或地址范围)之后,在命令之前,a !可以插入,指定当地址(或地址范围)不匹配时,该命令只执行。
支持以下地址类型:数字匹配只匹配指定的行号(如果在命令行上指定-s选项,则在文件上累积累积。
first~step 先匹配每一行开始的第一行。例如,“sed -n 1 ~ 2p”将打印所有内容,输入流中的奇数行,地址2 ~ 5将以每第五行匹配,从第二行开始。
$ 匹配最后一行。
/regexp/ 匹配行匹配正则表达式regexp。
\cregexpc 匹配行匹配正则表达式regexp。c可能是任何字符。
0,addr2 在“匹配的第一地址”状态开始,直到找到addr2。这类似于1,addr2,除了如果addr2匹配输入0的第一行,addr2表单将在它 的范围结束,而1,addr2表单仍将处于其范围的开始。这只适用于addr2是一个正则表达式。
addr1,+N 将匹配addr1和下面addr1的N行。
addr1,~N 将匹配addr1和跟踪addr1的行,直到下一行的输入行号是N的多倍。
正则表达式:类似于grep与awk
| : label | 对b和t命令的标签 |
| #comment | 注释一直延伸到下一个换行(或者是-e脚本片段的末尾) |
| } | { }块的最后括号 |
| = | 打印当前线号 |
| a \ | 文本附加文本,它有每个嵌入的新行,前面是反斜杠 |
| i \ | 文本插入文本,它有每个嵌入的新行前面的反斜杠 |
| q | 立即退出sed脚本,而不处理任何更多的输入 |
| Q | 立即退出sed脚本,而不处理更多的输入 |
| r filename | 将文本从文件名读取 |
| R filename | 将一行从文件名中删除, 命令的每个调用都从文件中读取一行 |
| { } | {开始一个命令块(以}结束) |
| b label | 分支到标签;如果被省略,分支到脚本的末尾 |
| c \ | 文本将选择的行替换为文本,它有每个嵌入的新行,前面有一个反斜杠 |
| d | 删除模式空间。开始下一个循环 |
| D | 如果模式空间不包含新行,则启动一个正常的新周期 info sed |
| h H | 复制/附加模式空间保持空间 |
| g G | 复制/ append存储空间到模式空间。 |
| l | 将当前线列在“视觉上明确”的形式 |
| l width | 在一个“视觉上明确的”形式列出当前线,在宽度字符上打破它 |
| n N | 读取/将下一行输入到模式空间中 |
| p | 打印当前的模式空间 |
| P | 打印到当前模式空间的第一个嵌入式新行 |
| s/xx/yy/ | 尝试将regexp与模式空间相匹配。如果成功,替换与替换匹配的部分 |
| t label | 如果s///已经完成了一个成功的替代,因为最后的输入行被读取,从最后一个t或T命令,然后分支到标签;如果省略了标签,分支到脚本的末尾 |
| T label | 如果没有一个s///已经完成了一个成功的替代,同上。 |
| w filename | 将当前的模式空间写入文件名 |
| W filename | 将当前模式空间的第一行写入文件名 |
| x | 交换保存和模式空间的内容 |
| y/source/dest/ | 在图形空间中删除出现在源上的字符 |
Test-use:
测试文本:1.txt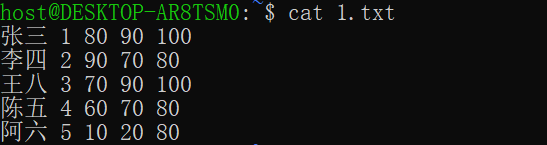
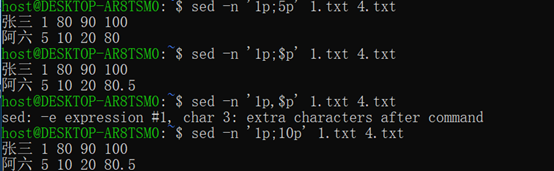
打印:p命令---默认全部打印并在匹配行下再打印一边
抑制自动打印:-n选项---仅选择匹配行打印

删除:d命令---打印缓冲区除了删除的行并不影响原文本

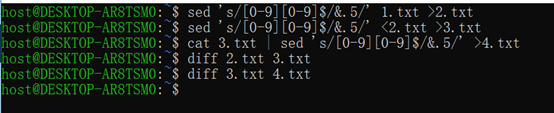
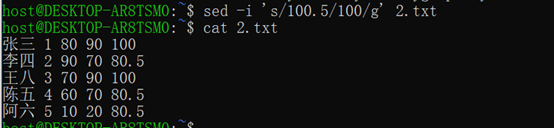
替换:s命令---s/xxx/XXX/g---s*xxx*XXX*/g
---g全部替换否则只替换行第一个
[0-9][0-9]$表示两位数结尾的行,&.5表末尾加小数
/\(7\)0/\1x/表示标记70的7为1存于寄存器中,再通过\1操作去引用

输入输出:结合管道及输出重定向符
e和f选项:
sed --file=xx.sed 1.txt ---- sed --expression=‘1,2d’ 1.txt

i 选项:修改源文件
多文本处理:多个输入文件视为一条漫长的流
Version和help选项:
sed --version sed – help Version显示版本,help显示选项描述

L选项:'-l N' '--line-length=N'
指定“l”命令的默认行包长度。长度为0(0)意味着永远不要结束长线。如果没有指定,它是70。测试不对可能版本问题

返回值:
0成功
1非法操作命令等
2文件不允许操作
4.IO错误—不常见
5.Q或q,终止sed 正常退出
















 1106
1106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









