







- 先贴效果图片
适合学过php基础和微信开发的朋友共同学习



第1步.微信配置接口url
<?php
//必须写这一句 token可以任意,但必需和微信那里填写的token一致
define("TOKEN","weixin");
if(isset($_GET['echostr'])){
$echoStr = $_GET["echostr"];
if(checkSignature()){
echo $echoStr;
//成功则返回
exit;
}
}
function checkSignature()
{
$signature = $_GET["signature"];
$timestamp = $_GET["timestamp"];
$nonce = $_GET["nonce"];
$token = "weixin";
$tmpArr = array($token, $timestamp, $nonce);
sort($tmpArr, SORT_STRING);
$tmpStr = implode( $tmpArr );
$tmpStr = sha1( $tmpStr );
if( $tmpStr == $signature ){
return true;
echo "成功";
}else{
return false;
echo "失败";
}
}
checkSignature();
?>第二步:开始写爬虫代码爬数据啦
先看一下,我们要爬的界面是长这个样子的
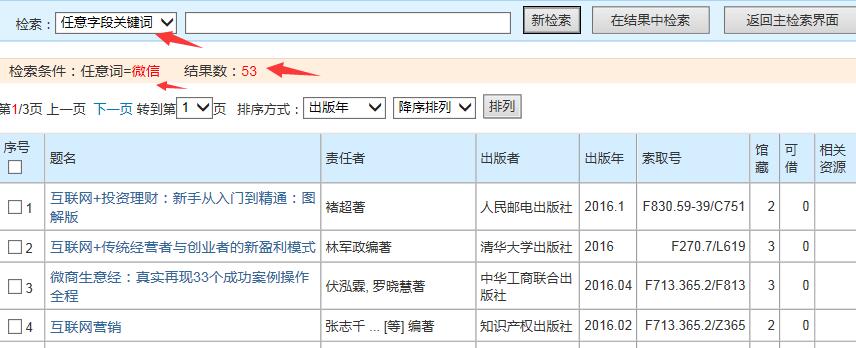
输入的关键字是微信:
拦截到的查询图书的请求长这样:
http://.../searchresult.aspx?anywords=%ce%a2%d0%c5&ecx=1&efz=0&dt=ALL&cl=ALL&dp=20&sf=M_PUB_YEAR&ob=DESC&sm=table&dept=ALL&code=gb2312
可以看到anywords 后面的不是中文的微信,而是gbk编码的文字再经过urlencode编码后得到的
直接贴爬虫代码:
//获取书列表------------------------------------------------------------------
header("Content-type: text/html; charset=utf-8");
//根据搜索关键字和页码返回图书数据----------------------------------------
function all($key,$page){
$key = iconv("utf-8","gb2312",$key);
$key = urlencode($key);
$url = "http://***.**.**.**/searchresult.aspx?anywords=$key&page=$page&dp=4";
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
"Accept-Language: zh-CN,zh",
));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
$con = curl_exec($ch);
结果如下:

接着是用正则表达式匹配出图书的id,图书名称,图书名,图书责任者,图书出版者,图书出版年,图书索取号,图书馆藏,图书可借
f12查看源代码:

消除换行后:

正则匹配开始~:
$str1=preg_replace("/\s+/", "", $con); //过滤多余回车
//这个正则有点长。。。。
$preg = "/ctrlno=(.*)\"target=\"_blank\">(.*)<\/a><\/span><\/td><td>([^<input].*)<\/td><td>(.*)<\/td><td>(.*)<\/td><tdclass=\"tbr\">(.*)<\/td><tdclass=\"tbr\">(.*)<\/td><tdclass=\"tbr\">(.*)<\/td>/U";结果图如下:



接下来计算总页数
//获取图书结果数计算出页数-------------------------------------------------------
//这里看源代码里显示的是总记录数
$preg = "/<fontcolor=\"Red\">(.*)<\/font>/U";
preg_match($preg,$str1,$num);
//根据总记录数/页面条数 然后向上取整 就得到总页数啦
$num = ceil($num[1]/4);
//另外判断如果用户输入的页数大于总页数,则返回空数组
if($page>$num){
$arr = array();
return $arr;
}接下来将获得的数据拼接成一本书一本书的数据(不知道怎么说,就大白话说啦)
//用数组拼接数据---------------------------------------------------------------
$arr = array();
//遍历四次,将数据装入四个数组里面,一个大数组装四本书的小数组
for($i=0;$i<4;$i++){
//获取图书的馆藏地,因为图书室通过索取号拼的链接另外拿的,不清楚的看下面的方法getAddress
$bookAddr=getAddress($mesArr[1][$i]);
//0=>书名 1=>出版社 2=>馆藏 3=>可借 4=>作者 5=>出版年 6=>索取号
$arr[$i] = array("0"=>$mesArr[2][$i],"1"=>$mesArr[4][$i],"2"=>$mesArr[7][$i],"3"=>$mesArr[8][$i],"4"=>$mesArr[3][$i],"5"=>$mesArr[5][$i],"6"=>$mesArr[6][$i],"7"=>$bookAddr);
}
结果图:吼吼~ 出现啦:

//根据书ctrlno获取藏书点-------------------------------------------------------
function getAddress($id){
//这个ctrlno就是在匹配图书的详情链接时就有匹配到
$url = "http://***.**.**.**/bookinfo.aspx?ctrlno=$id";
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
"Accept-Language: zh-CN,zh",
));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
$con = curl_exec($ch);
//echo $con;
$preg = "/onclick='showLibInfo\(\"[0-9]+\"\)'>(.*)<\/a>/";
preg_match_all($preg,$con,$a);
//return $a[1];
$str = "";
//将匹配到的数组生成一个字符串
for($i=0;$i<count($a[1]);$i++){
$str.=$a[1][$i]."-";
}
$str = substr($str,0,strlen($str)-1);
//$str = str_replace("-", "\n",$str );
return $str;
}馆藏地结果图如下:

接下来是细活啦:拼接返回微信的图文里的图书标题,考虑到标题太长不美观,所以只拼接书名,出版社,馆藏还有可借
还是直接贴代码:
//将大数组中的每一个图书小数组转成字符串-------------------------------------------
function makeMess($arr,$i,$str){
$str = "";
$key = "";
for($j=0;$j<4;$j++){
switch($j){
case 0:
$key = "书名";
break;
case 1:
$key = "\n"."出版社";
break;
case 2:
$key = "\n"."馆藏";
break;
case 3:
$key = " 可借";
break;
}
$str.= $key.":".$arr[$i][$j];
}
return $str;
}另外,点击多图文里的每一个小图文时,要跳到详情页显示所有图书信息给用户看,但如果再用正则匹配一遍明显很费时,所以我决定用url后带参数的方法提交过去,很懒的做法有木有,所以接下来是拼接多图文里面图文的超链接啦,将第一次查询图书时匹配到的图书信息拼在url后面带过去给详情页
一言不合又是贴代码:
//拼接每本书的详情页url---------------------------------------------------------
function makeUrl($arr,$i,$str){
//这个是我自己做的简单响应式页面,跳转到这里显示图书详细信息啦
$url = "http://www.kimtaeyoen.com/library/bookDetail.php?";
$str = "";
$key = "";
for($j=0;$j<8;$j++){
switch($j){
case 0:
$key = "书名";
break;
case 1:
$key = "&出版社";
break;
case 2:
$key = "&馆藏";
break;
case 3:
$key = "&可借";
break;
case 4:
$key = "&责任者";
break;
case 5:
$key = "&出版年";
break;
case 6:
$key = "&索取号";
break;
case 7:
$key = "&馆藏地";
break;
}
$str.= $key."=".$arr[$i][$j];
}
return $url.$str;
} 最后返回微信客户端那边的格式大概是这样的:

没错,不是json格式。。。没打算做成接口,没打算考虑扩展。。
原理如下:
当用户第一次关注时,将用户的openid存入数据表book(字段:openid[与当前公众号联系的唯一标示],book[搜索关键字])中,为什么要存,因为当用户选择页数时候,我们可以通过用户的openid在book表中查出刚才他查的是什么书,当用户输入另外的关键字时,则更新book表里用户对应的book字段为用户当前输入的关键字
工具类tool.php的代码如下:
//当用户关注公众号时插入book表openid
function insertuser($openid){
//连接数据库
$link = mysql_connect("localhost","root","123");
//选择数据库
mysql_select_db("weixin");
$sql = "insert into book(openid) values ('$openid')";
mysql_query($sql);
}
//当用户非第一次输入搜索关键字时更新book表的book属性
function updateSerch($openid,$book){
//连接数据库
$link = mysql_connect("localhost","root","123");
//选择数据库
mysql_select_db("weixin");
$sql = "update book set book='$book' where openid='$openid'";
mysql_query($sql);
}
//当用户选择页数时查出用户之前输入的查询关键字book
function findSerch($openid){
//连接数据库
$link = mysql_connect("localhost","root","123");
//选择数据库
mysql_select_db("weixin");
$sql = "select book from book where openid='$openid'";
$result = mysql_query($sql);
if($mess = mysql_fetch_assoc($result)){
return $mess['book'];
}
}接下来是写微信的接口页面,这个比较简单,
<?php
$wechatObj = new Wechat();
//如果没有通过GET收到echostr字符串, 说明不是再使用token验证
if (!isset($_GET['echostr'])) {
//调用wecat对象中的方法响应用户消息
$wechatObj->responseMsg();
}else{
//调用valid()方法,进行token验证
if($wechatObj->valid()){
echo $echoStr;
exit;
}
}
//声明一个Wechat的类, 处理接收消息, 接收事件, 响应各种消息, 以及token验证
class Wechat {
//相应消息处理
public function responseMsg(){
//接收微信传过来的xml消息数据
$postStr = $GLOBALS["HTTP_RAW_POST_DATA"];
//如果接收到了就处理并回复
if(!empty($postStr)){
//将接收到德xml字符串写入日志,用R标记表示接收到消息
$this->logger("R \n".$postStr);
//将接收到的消息处理返回一个对象
$postObj = simplexml_load_string($postStr,'SimpleXMLElement',LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$keyword = trim($postObj->Content);
$time = time();
$RX_TYPE = trim($postObj->MsgType);
//消息类型分离,通过RX_TYPE类型作为判断,每个方法都需要将对象$postObj传入
switch($RX_TYPE){
case "event":
$this->receiveEvent($postObj);
break;
case "text":
$this->receiveText($keyword, $fromUsername, $toUsername, $time);
break;
default:
break;
}
}
}
//接收事件消息
private function receiveEvent($object){
//临时定义一个变量, 不同的事件发生时, 给用户反馈不同的内容
$content = "";
//通过用户发过来的不同事件做处理
switch ($object->Event)
{
//用户一关注 触发的事件
case "subscribe":
include "tool.php";
insertuser($object->FromUserName);
$content = "欢迎关注图书馆图书查询!";
break;
//取消关注时触发的事件
case "unsubscribe":
$content = "取消关注";
break;
}
$result = $this->transmitText($object, $content);
echo $result;
}
//整理好回复图书多图文的回复格式
private function getBook($keyword, $fromUsername, $toUsername, $time,$pagesize){
// 回复图文的模板
$textTpl = "<xml>
<ToUserName><![CDATA[%s]]></ToUserName>
<FromUserName><![CDATA[%s]]></FromUserName>
<CreateTime>%s</CreateTime>
<MsgType><![CDATA[news]]></MsgType>
<ArticleCount>5</ArticleCount>
<Articles>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[4]]></Description>
<PicUrl><![CDATA[http://img3.imgtn.bdimg.com/it/u=3937886759,1529255090&fm=21&gp=0.jpg]]></PicUrl>
<Url><![CDATA[%s]]></Url>
</item>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[2]]></Description>
<PicUrl><![CDATA[]]></PicUrl>
<Url><![CDATA[%s]]></Url>
</item>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[3]]></Description>
<PicUrl><![CDATA[]]></PicUrl>
<Url><![CDATA[%s]]></Url>
</item>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[4]]></Description>
<PicUrl><![CDATA[]]></PicUrl>
<Url><![CDATA[%s]]></Url>
</item>
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[5]]></Description>
<PicUrl><![CDATA[]]></PicUrl>
<Url><![CDATA[%s]]></Url>
</item>
</Articles>
<FuncFlag>1</FuncFlag>
</xml>";
include "WelibrarySUC.php";
$arr = all($keyword,$pagesize);
$point = ($arr==null)? "当前页已经没有图书啦~ 点图有放送~" : "第$pagesize/{$arr[0][4]}页 回复数字选页 点图有放送~";
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time,$point,"http://bd.kuwo.cn/yinyue/6421359?from=baidu",$arr[0][0],$arr[1][0],$arr[0][1],$arr[1][1],$arr[0][2],$arr[1][2],$arr[0][3],$arr[1][3]);
return $resultStr;
}
//接收文本消息并准备文本信息
private function receiveText($keyword, $fromUsername, $toUsername, $time){
include "tool.php";
//从接收到德消息中获取用户输入的文本内容,作为一个查询的关键字,使用trim()函数去掉两边的空格
$keyword = trim($keyword);
if(is_numeric($keyword)){
$book = findSerch($fromUsername);
echo $this->getBook($book, $fromUsername, $toUsername, $time,$keyword);
}else{
updateSerch($fromUsername,$keyword);
echo $this->getBook($keyword, $fromUsername, $toUsername, $time,1);
}
}
//整理好回复文本的回复格式
private function transmitText($object,$content){
$xmlTpl = "
<xml>
<ToUserName><![CDATA[%s]]></ToUserName>
<FromUserName><![CDATA[%s]]></FromUserName>
<CreateTime>%s</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[%s]]></Content>
</xml>
";
$result = sprintf($xmlTpl,$object->FromUserName,$object->ToUserName,time(),$content);
return $result;
}
}接下来就是那个所谓的图书详情页了:
<?php
error_reporting(E_ALL^E_NOTICE^E_WARNING);
$b_name = $_GET["书名"];
$b_publish = $_GET["出版社"];
$b_holding = $_GET["馆藏"];
$b_borrow = $_GET["可借"];
$b_author = $_GET["责任者"];
$b_published = $_GET["出版年"];
$b_number = $_GET["索取号"];
$b_address = $_GET["馆藏地"];
$b_address = str_replace("-", "<br/>",$b_address);
//echo $b_name;
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>图书详情页</title>
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<link href="css/bootstrap.min.css" rel="stylesheet" type="text/css"/>
<style type="text/css">
body{ align:center;margin:0;}
</style>
</head>
<body background="13.jpg">
<!--用户列表-->
<div class="container" id="user_list">
<h2 align=center>图书详情</h2>
<div class="table-responsive">
<table class="table table-bordered ">
<tbody id="user_list_tbody">
<tr><td>书 名</td><td><?php echo $b_name?></td></tr>
<tr><td>责任者</td><td><?php echo $b_author?></td></tr>
<tr><td>出版者</td><td><?php echo $b_publish?></td></tr>
<tr><td>出版年</td><td><?php echo $b_published?></td></tr>
<tr><td>索取号</td><td><?php echo $b_number?></td></tr>
<tr><td>馆 藏</td><td><?php echo $b_holding?></td></tr>
<tr><td>可 借</td><td><?php echo $b_borrow?></td></tr>
<tr><td>馆藏地</td><td><?php echo $b_address?></td></tr>
</tbody>
</table>
</div>
</div>
<script src='js/jquery.min.js'></script>
<script src='js/bootstrap.min.js'></script>
<script src="js/common.js"></script>
<!-- <script src="js/userList.js" type="text/javascript" charset="utf-8"></script> -->
</body>
</html>结束、效果图如顶图所示~ 好了,菜鸟一枚,各位道友不喜勿喷,















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









