







# !/usr/bin/env Python3
# -*- coding: utf-8 -*-
# @version: v1.0
# @Author : Meng Li
# @contact: 925762221@qq.com
# @FILE : torch_seq2seq.py
# @Time : 2022/6/8 11:11
# @Software : PyCharm
# @site:
# @Description : 将Seq2Seq网络采用编码器和解码器两个类进行融合
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchsummary
from torch.utils.data import Dataset, DataLoader
import numpy as np
import os
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class my_dataset(Dataset):
def __init__(self, enc_input, dec_input, dec_output):
super().__init__()
self.enc_input = enc_input
self.dec_input = dec_input
self.dec_output = dec_output
def __getitem__(self, index):
return self.enc_input[index], self.dec_input[index], self.dec_output[index]
def __len__(self):
return self.enc_input.size(0)
class Encoder(nn.Module):
def __init__(self, in_features, hidden_size):
super().__init__()
self.in_features = in_features
self.hidden_size = hidden_size
self.encoder = nn.LSTM(input_size=in_features, hidden_size=hidden_size, dropout=0.5, num_layers=1) # encoder
def forward(self, enc_input):
seq_len, batch_size, embedding_size = enc_input.size()
h_0 = torch.rand(1, batch_size, self.hidden_size)
c_0 = torch.rand(1, batch_size, self.hidden_size)
# en_ht:[num_layers * num_directions,Batch_size,hidden_size]
encode_output, (encode_ht, decode_ht) = self.encoder(enc_input, (h_0, c_0))
return encode_output, (encode_ht, decode_ht)
class Decoder(nn.Module):
def __init__(self, in_features, hidden_size):
super().__init__()
self.in_features = in_features
self.hidden_size = hidden_size
self.crition = nn.CrossEntropyLoss()
self.fc = nn.Linear(hidden_size, in_features)
self.decoder = nn.LSTM(input_size=in_features, hidden_size=hidden_size, dropout=0.5, num_layers=1) # encoder
def forward(self, enc_output, dec_input):
(h0, c0) = enc_output
# en_ht:[num_layers * num_directions,Batch_size,hidden_size]
de_output, (_, _) = self.decoder(dec_input, (h0, c0))
return de_output
class Seq2seq(nn.Module):
def __init__(self, encoder, decoder, in_features, hidden_size):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.in_features = in_features
self.hidden_size = hidden_size
self.fc = nn.Linear(hidden_size, in_features)
self.crition = nn.CrossEntropyLoss()
def forward(self, enc_input, dec_input, dec_output):
enc_input = enc_input.permute(1, 0, 2) # [seq_len,Batch_size,embedding_size]
dec_input = dec_input.permute(1, 0, 2) # [seq_len,Batch_size,embedding_size]
# output:[seq_len,Batch_size,hidden_size]
_, (ht, ct) = self.encoder(enc_input) # en_ht:[num_layers * num_directions,Batch_size,hidden_size]
de_output = self.decoder((ht, ct), dec_input) # de_output:[seq_len,Batch_size,in_features]
output = self.fc(de_output)
output = output.permute(1, 0, 2)
loss = 0
for i in range(len(output)): # 对seq的每一个输出进行二分类损失计算
loss += self.crition(output[i], dec_output[i])
return output, loss
def make_data(seq_data):
enc_input_all, dec_input_all, dec_output_all = [], [], []
vocab = [i for i in "SE?abcdefghijklmnopqrstuvwxyz上下人低国女孩王男白色高黑"]
word2idx = {j: i for i, j in enumerate(vocab)}
V = np.max([len(j) for i in seq_data for j in i]) # 求最长元素的长度
for seq in seq_data:
for i in range(2):
seq[i] = seq[i] + '?' * (V - len(seq[i])) # 'man??', 'women'
enc_input = [word2idx[n] for n in (seq[0] + 'E')]
dec_input = [word2idx[i] for i in [i for i in len(enc_input) * '?']]
dec_output = [word2idx[n] for n in (seq[1] + 'E')]
enc_input_all.append(np.eye(len(vocab))[enc_input])
dec_input_all.append(np.eye(len(vocab))[dec_input])
dec_output_all.append(dec_output) # not one-hot
# make tensor
return torch.Tensor(enc_input_all), torch.Tensor(dec_input_all), torch.LongTensor(dec_output_all)
def translate(word):
vocab = [i for i in "SE?abcdefghijklmnopqrstuvwxyz上下人低国女孩王男白色高黑"]
idx2word = {i: j for i, j in enumerate(vocab)}
V = 5
x, y, z = make_data([[word, "?" * V]])
if not os.path.exists("translate.pt"):
train()
net = torch.load("translate.pt")
pre, loss = net(x, y, z)
pre = torch.argmax(pre, 2)[0]
pre_word = [idx2word[i] for i in pre.numpy()]
pre_word = "".join([i.replace("?", "") for i in pre_word])
print(word, "-> ", pre_word[:pre_word.index('E')])
def train():
vocab = [i for i in "SE?abcdefghijklmnopqrstuvwxyz上下人低国女孩王男白色高黑"]
word2idx = {j: i for i, j in enumerate(vocab)}
idx2word = {i: j for i, j in enumerate(vocab)}
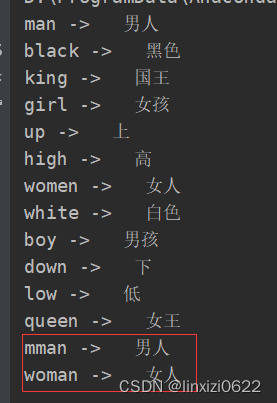
seq_data = [['man', '男人'], ['black', '黑色'], ['king', '国王'], ['girl', '女孩'], ['up', '上'],
['high', '高'], ['women', '女人'], ['white', '白色'], ['boy', '男孩'], ['down', '下'], ['low', '低'],
['queen', '女王']]
enc_input, dec_input, dec_output = make_data(seq_data)
batch_size = 3
in_features = len(vocab)
hidden_size = 128
train_data = my_dataset(enc_input, dec_input, dec_output)
train_iter = DataLoader(train_data, batch_size, shuffle=True)
encoder = Encoder(in_features, hidden_size)
decoder = Decoder(in_features, hidden_size)
net = Seq2seq(encoder, decoder, in_features, hidden_size)
learning_rate = 0.001
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
loss = 0
for i in range(1000):
for en_input, de_input, de_output in train_iter:
output, loss = net(en_input, de_input, de_output)
pre = torch.argmax(output, 2)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print("step {0} loss {1}".format(i, loss))
torch.save(net, "translate.pt")
if __name__ == '__main__':
before_test = ['man', 'black', 'king', 'girl', 'up', 'high', 'women', 'white', 'boy', 'down', 'low', 'queen',
'mman', 'woman']
[translate(i) for i in before_test]
# train()
仍然先上代码,接上一篇文章,这里将Seq2Seq模型个构建采用Encoder类和Decoder类融合起来
主要是为了后面的Attention作铺垫

















 5260
5260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









