







Post pruning decision trees with cost complexity pruning
背景
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
决策树作为树模型中最经典的算法,根据训练数据生长并分裂叶子结点,容易过拟合。所以一般来说会考虑生长停止后进行剪枝,把一些不必要的叶子结点去掉(让其父结点作为叶子结点),这样或许对其泛化能力有积极作用。
在scikit-learn的决策树模块里,默认是不剪枝的,因为ccp_alpha参数被默认置为0.0。
它使用的剪枝算法为Minimal Cost-Complexity Pruning,即最小化
R
α
(
T
)
=
R
(
T
)
+
α
∣
T
∣
R_\alpha(T)=R(T)+\alpha|T|
Rα(T)=R(T)+α∣T∣。
这个式子解释了一颗给定树T的综合代价,由两部分组成:
- R(T)为树T的错误成本Cost,具体实现为该树的加权熵。
scikit-learn uses the total sample weighted impurity of the terminal nodes for R(T)
impurity可以理解为熵。
- |T|是树的叶子结点个数,同时也是Complexity, α \alpha α 为系数,也就是本文的焦点ccp_alpha参数。该值越大,树应该越小。
这个式子的两部分会因为树的复杂度或者说叶子结点的个数发生相反方向的变化
-
第一部分 Cost
如果不进行剪枝,那么生长结束的树拥有最小的R(T),因为它把能分裂的尽量分裂,不同标签的样本尽可能分进了不同的叶子结点,使得每个叶子结点的impurity最小。一旦剪枝,那么R(T)开始变大,因为叶子结点的impurity开始变大。所以树因为剪枝变小的过程,Cost由小变大。 -
第二部分 Complexity
剪枝使得树变小,也就是叶子结点(|T|)变少。所以树因为剪枝变小的过程,Complexity由大变小。
one more step 假设现在是两颗树进行比较。一个树只有一个结点,也就是它的根节点t,我们记为数 T root only T_\text{root only} Troot only;另外一棵树是这个根节点加上分裂出来的叶子结点,我们记为树 T with leafs T_\text{with leafs} Twith leafs。
这两棵树分别写一下综合代价应该如何表示呢?
R
α
(
T
root only
)
=
R
(
T
root only
)
+
α
R_\alpha(T_\text{root only})=R(T_\text{root only})+\alpha
Rα(Troot only)=R(Troot only)+α
R
α
(
T
with leafs
)
=
R
(
T
with leafs
)
+
α
∣
T
with leafs
∣
R_\alpha(T_\text{with leafs})=R(T_\text{with leafs})+\alpha|T_\text{with leafs}|
Rα(Twith leafs)=R(Twith leafs)+α∣Twith leafs∣
根据刚才说的,我们有 R ( T root only ) > R ( T with leafs ) R(T_\text{root only}) > R(T_\text{with leafs}) R(Troot only)>R(Twith leafs)成立。同时, α < α ∣ T with leafs ∣ \alpha < \alpha|T_\text{with leafs}| α<α∣Twith leafs∣。那么是不是可以找到一个 α \alpha α,使得 R α ( T root only ) = R α ( T with leafs ) R_\alpha(T_\text{root only}) = R_\alpha(T_\text{with leafs}) Rα(Troot only)=Rα(Twith leafs)成立呢?
α e f f e c t i v e ( t ) = R ( T root only ) − R ( T with leafs ) ∣ T with leafs ∣ − 1 \alpha_{effective}(t) = \frac{R(T_\text{root only})-R(T_\text{with leafs})}{|T_\text{with leafs}|-1} αeffective(t)=∣Twith leafs∣−1R(Troot only)−R(Twith leafs) 就是我们要找的那个临界 α \alpha α。
你看,对于每一个内部结点t, 我们都有两种选择,要么保留它的叶子结点;要么裁剪掉它的叶子结点,让这个父结点成为一个叶子结点。我们在剪枝的过程中,也是从外到内,从最外的叶子结点,不断往内部裁剪。在裁剪时,我们会遇到一个问题:外面这一圈有这么多叶子结点,我应该先剪掉哪一个父结点的叶子结点呢?
L. Breiman等人证明过,存在一个 α \alpha α的单调区间序列,在这个 α \alpha α序列里每一个 α i \alpha_i αi对应一个最优子树,而且这些子树是相互嵌套的(序列里小的树是序列里比他更大的所有树的子树)。
具体的证明在这里不会展开,因为我也不会。这里简单粗暴地给出他们的证明可以怎么用。
重点来了:
刚才我们对某个内部结点t计算了它的临界
α
\alpha
α,即
α
e
f
f
e
c
t
i
v
e
(
t
)
\alpha_{effective}(t)
αeffective(t)。那么对于每一个内部结点
i
i
i,我们是不是都可以计算它的
α
e
f
f
e
c
t
i
v
e
(
i
)
\alpha_{effective}(i)
αeffective(i)。那么好,假设我们已经根据决策树的生长算法生成了一颗很大的树,我们猜测它过拟合了,我们要对他进行剪枝,以提升泛化能力。可以怎么做呢?
step1 对当前树的所有叶子结点的父结点,计算临界 α e f f e c t i v e \alpha_{effective} αeffective,找到临界值最小的那个父结点,对他进行剪枝,即把它的叶子结点裁剪掉,让它作为叶子结点。它的输出标签为该结点所持有的样本标签的多数类。裁剪后的树设置为当前树。
step2 重复step1,直到满足停止剪枝条件。比如,剪枝轮次达到阈值、临界值达到阈值等等。
上面这个过程中,我们其实可以产生一个临界 α \alpha α的序列,同时也会产生每棵最优子树的impurity,后面代码的时候我们会用到。
为什么需要调整ccp_alpha参数
由上可知,式子里需要加一个 α \alpha α参数来进行协调两个部分的影响,如果它俩的变化方向是同向的也就没必要加这个参数了。因此,这个 α \alpha α是决策树的一个超参数,在使用决策树模块时可能需要对其进行合理设置以获得更好的模型表现。很容易理解,比起对训练集的预测表现,如果你更希望树复杂度低一点,那么把 α \alpha α调大;如果你希望它能够充分学习训练集甚至过拟合,那么把 α \alpha α调小。
看到这里,你可以先看看来自scikit-learn官网决策树模块有关ccp_alpha参数的解释。
下面是scikit-learn里决策树模块的ccp_alpha参数解释:
ccp_alpha : non-negative float, default=0.0
Complexity parameter used for Minimal Cost-Complexity Pruning. The subtree with the largest cost complexity that is smaller than ccp_alpha will be chosen. By default, no pruning is performed.
为什么前面说,在scikit-learn的决策树模块里,默认是不剪枝的, 应该就很好理解了。
接下来,本文将通过一个代码示例,介绍如何可视化选择合适的ccp_alpha。
初始化
为了下文中代码的可读性,这里先把所有本文涉及到的依赖一次性给出。
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from sklearn.metrics import recall_score, precision_score
后面的随机状态默认使用0,即
random_state = 0
获取数据,这里使用的是sklearn自带的乳癌数据集,标签是二分类。并做训练集和测试集划分。
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
计算临界 α \alpha α序列和对应的impurity序列。然后把临界值序列对应的最优子树也准备好放在clfs变量里备用。
clf = DecisionTreeClassifier(random_state=0)
path = clf.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
clfs = []
for ccp_alpha in ccp_alphas:
clf = DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
clf.fit(X_train, y_train)
clfs.append(clf)
然后接下来这段代码比较多,但是也很容易理解。我都写上注释了。
# 由于alpha序列的最后一个是最大的临界alpha,它对应的最优子树其实是根节点,
# 对我们没啥意义,所以剔除掉。
clfs = clfs[:-1]
ccp_alphas = ccp_alphas[:-1]
# 使用最优子树序列预测训练集和测试集。
y_test_preds = [clf.predict(X_test) for clf in clfs]
y_train_preds = [clf.predict(X_train) for clf in clfs]
# 计算训练集、测试集的召回率
train_recall_scores = [recall_score(y_train, y_train_pred) for y_train_pred in y_train_preds]
test_recall_scores = [recall_score(y_test, y_test_pred) for y_test_pred in y_test_preds]
# 计算训练集、测试集的精确率
train_precision_scores = [precision_score(y_train, y_train_pred) for y_train_pred in y_train_preds]
test_precision_scores = [precision_score(y_test, y_test_pred) for y_test_pred in y_test_preds]
# 计算训练集、测试集的准确率
train_accuracy_scores = [clf.score(X_train, y_train) for clf in clfs]
test_accuracy_scores = [clf.score(X_test, y_test) for clf in clfs]
# 画图函数,入参为模型指标(recall、accuracy、precision)
def draw_func(metric_name):
fig, ax = plt.subplots()
ax.set_xlabel("alpha")
ax.set_ylabel(metric_name)
ax.set_title(metric_name + " vs alpha for training and testing sets")
ax.plot(ccp_alphas, eval(f"train_{metric_name}_scores"), marker="o", label="train", drawstyle="steps-post")
ax.plot(ccp_alphas, eval(f"test_{metric_name}_scores"), marker="o", label="test", drawstyle="steps-post")
ax.legend()
plt.show()
看看这三个指标的效果
(1)准确率
draw_func(metric_name='accuracy')
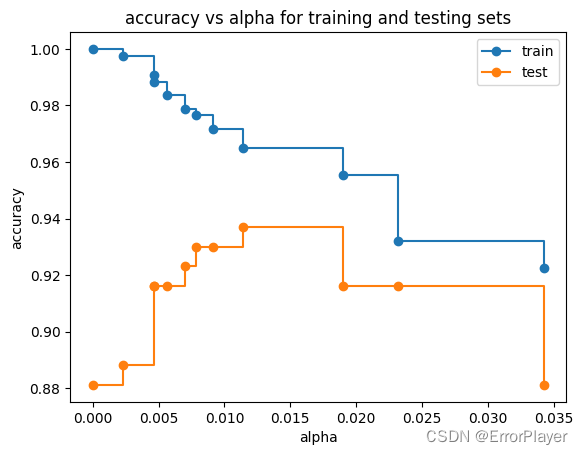
从准确率来看,选择alpha为0.015, 比较好。
(2)召回率
draw_func(metric_name='recall')
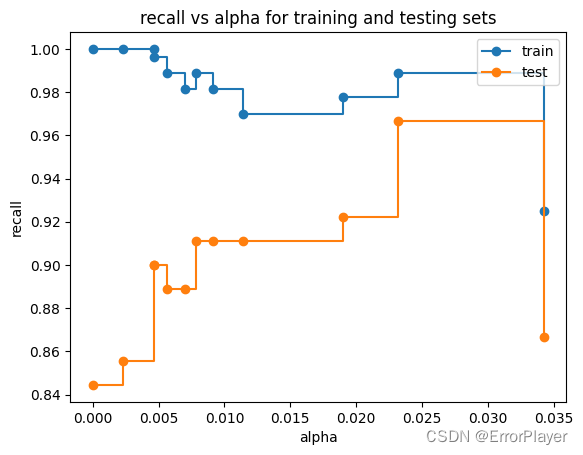
从召回率来看,选择0.03比较好。
(3)精确率
draw_func(metric_name='precision')
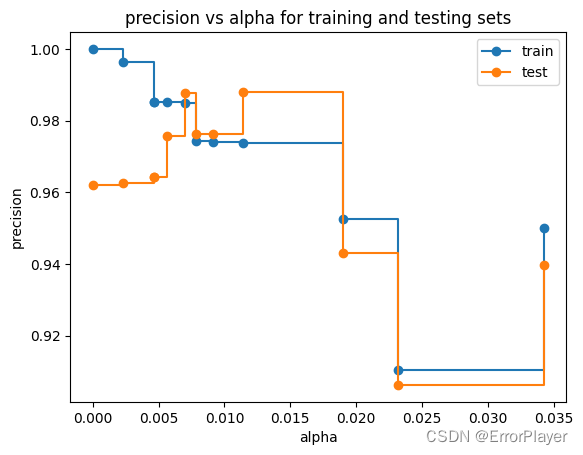
可以发现在0.005到0.01之间有一段非常小的区间,测试集表现最高且训练集没有太大下降。但是这个区间有些窄,好像看起来有点不稳定。我们暂且又选择0.015吧。
现在把ccp_alpha设置好,打印得分出来看看
def get_results(ccp_alpha_para):
clf = DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha_para)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(f'acc: {round(clf.score(X_test, y_test), 3)}')
print(f'recall: {round(recall_score(y_test, y_pred), 3)}')
print(f'precision: {round(precision_score(y_test, y_pred), 3)}')
我这里还是觉得放在表格里一目了然一些:
import pandas as pd
adf = pd.DataFrame(columns=['ccp_alpha'], data=[0.0, 0.001, 0.015, 0.03])
adf[['acc', 'recall', 'precision']] = adf.apply(lambda x:get_results(x['ccp_alpha']), axis=1, result_type='expand')
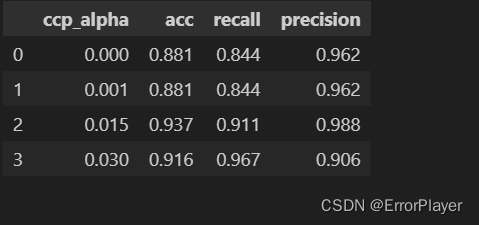
表格里的结果都是在测试集下的表现。如同刚才所说的,召回率在0.03的时候高一些,准确率和精确率则是选择0.015比较好。
可见, 当ccp_alpha=0时(也就是默认参数),模型性能不是最好的。
在本案例中,假如设置为0.015, 相比默认参数0,acc提升5.6%,recall提升6.7%,precision提升2.6%。
后续
在获得了临界alpha序列和对应的最优子树序列之后,如果你不指定ccp_alpha,那么剪枝算法其实是对每一个最优子树在数据集上重新计算综合代价来确定的子树。
在李航的统计学习方法中,还讲到可以用验证集来进行剪枝。这样可能具有更好的泛化性。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









