







目录
一、二维卷积层
卷积神经网络是指会有卷积层的神经网络,本次实验学习的卷积神经网络均是使用最常见的二维卷积层,二维卷积层通常是用来处理图像数据,因为图像通常也是用一个二维矩阵来存储的,矩阵中的值为图像的灰度值,虽然彩色图像是用三维矩阵存储的,但它本质是一个三通道的二维矩阵,同样是二维的运算,本次实验我们将学习二维卷积层的简单计算。
1. 二维互相关运算
在卷积层中,我们通常使用的不是卷积运算,而是互相关运算,因为互相关运算更加直观,更容易理解。
首先我们给出一个二维特征矩阵和一个二维卷积核。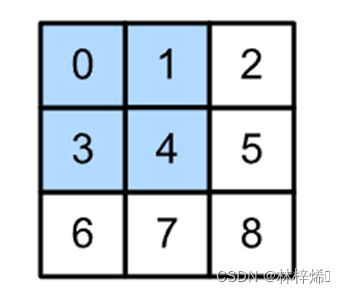
如上图,第一个为特征矩阵,第二个为卷积核
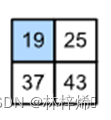
互相关运算的基本步骤是选择特征矩阵最左上的2x2(卷积核大小)的子矩阵,将其与卷积核进行对应位置的元素相乘再相加运算,即左边的子矩阵的第0,0个元素与卷积核第0,0个元素相乘,即0*0;左边第0,1个元素与右边第0,1个元素相乘,即1*1;依次递推,将每个乘积结果累加就能得到输出结果的第1个元素19,该元素所在位置是第一行。
此时再将特征矩阵当前子矩阵向右移一个stride(步长)的长度,这里是1,得到一个二维矩阵[[1,2],[4,5]],同样与卷积核运算得到输出结果的第2个元素25,该元素同样在输出结果的第一行。
重复上述的操作,如果向右移动到底了就移动到最左侧,再向下移动一个stride的长度,此时再进行运算的结果就会在第二行了,因为进行过一次向下移动的过程。重复上述操作直到整个特征矩阵都被遍历完。
最终能得到一个2x2的输出矩阵
根据上面的步骤,我们能写出一个计算互相关运算的函数
def corr2d(X, K): # 本函数已保存在d2lzh_pytorch包中方便以后使用
h, w = K.shape
X, K = X.float(), K.float()
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y上述代码首先获取卷积核的高和宽,接着定义一个矩阵Y,用Y来存储计算结果,根据上面我们的计算步骤我们可以得到它的行数是(X.shape[0]-h)/stride +1 ,列数是(X.shape[1] – w)/stride + 1,这里stride是1。
接着就可以开始卷积运算了,首先遍历行,再遍历列,每次移动一个步长,将当前子矩阵与卷积核进行点乘运算再求和得到当前元素的值,重复操作直到遍历结束。
2.二维卷积层
定义卷积层的方式同线性回归类似,线性回归是将特征与权重相乘再加上偏置,因此需要权重和偏差这两个参数,卷积层是将特征矩阵与卷积核进行卷积运算,同样需要加上偏置,我们同样可以把卷积核看成是一个权重,它的大小是卷积核的大小。线性回归的前向运算是线性变换,卷积的前向运算则是卷积运算,使用上面我们以及定义的corr2d函数进行卷积计算。得到如下的二维卷积层定义。
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias3.图像中物体边缘检测
接下来我们使用卷积层来做一个简单的应用:检测图像中的边缘信息,要检测图像的边缘,则需要一个特殊的卷积核。

如上图这个卷积核就是一个检测物体边缘的卷积核,因为物体的边缘通常是变化巨大的,如果横向的两个元素相同,则输出结果为0,否则为非0。如果为0,则说明与旁边的元素没有差别,为非0则于旁边的元素不同,说明该元素是边缘。
现在来使用它来检测下面这个图像

可以看出第2列和第7列是边缘
将其与卷积核进行互相关运算,得到如下结果:
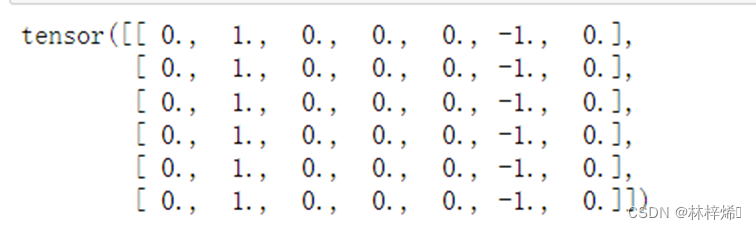
可以看出其检测结果如我们想的一样是第2列和第7列
4. 通过数据学习核数组
现在我们来尝试一下让卷积层进行训练得到我们上面定义的卷积核,其基本步骤与线性回归类似,都是首先自定义权重(卷积层中的权重即卷积核)和偏置,然后进行计算得到预测的y值,将其与实际的y值比较,得到训练损失,使用梯度下降法不断减少损失,达到最佳的训练效果,此时就能得到一个很好的权重值了(卷积核)
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1, 1, kernel_size=(1, 2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')训练结果如下:

可以看到,经过10次的迭代周期,训练损失将到了0.041,这是一个很好的结果,接下来我们再看看训练得出的卷积核与实际相差多少
![]()
可以看到这个值与我们实际的[[1,-1]]相差很小,训练效果很好。
二、多输入通道和多输出通道
前面我们使用的都是二维矩阵,但二维图像实际是灰度的图像,而我们日常所接触的图像大多都是彩色图像,彩色图像是三维的,其大小是3 * h * w,一般我们将第一维也就是3看作是通道数,因此彩色图像也可以看作是3通道的二维矩阵,我们在计算彩色图像时就是多输入通道的计算,实际的计算方法与二维矩阵是类似,输入通道数多只是要多计算几次而已。
1. 多输入通道
当输入通道有多个的时候,我们需要有与输入通道数相同的卷积核,每个卷积核都与一个输入通道的二维矩阵进行卷积运算,再将每个通道的卷积计算结果累加得到计算结果,因此尽管输入通道有多个,但计算的结果还是只有一个。
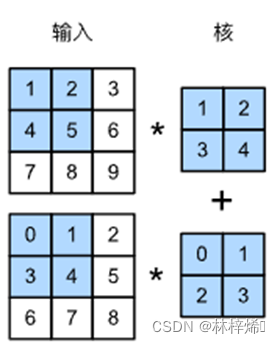
如上图这个多输入通道的矩阵,分别计算上面这个两个卷积的计算结果和下面的卷积计算结果,将这两个结果相加就能得到第一个元素的值56,其它操作与二维的运算相同,只是多了一个将多个通道的计算结果相加的操作而已。上图的卷积计算结果如下:
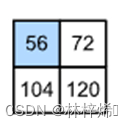
通过上面的介绍,我们能得到多输入通道的卷积计算函数
def corr2d_multi_in(X, K):
# 先遍历 “X” 和 “K” 的第0个维度(通道维度),再把它们加在一起
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))这里就是遍历X和K的通道维度,将每个通道进行卷积计算再求和即可。
计算结果:
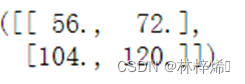
计算结果如我们手算的相同,计算正确
2. 多输出通道
在多输入通道中,我们将每个通道的结果累加在一起,因此无论通道数有多少,最终的计算结果都只有一个通道,那么如果我们需要多个通道该怎么做呢?我们可以将卷积核进行扩展,使其成为一个四维的矩阵,形状为𝑐𝑜×𝑐𝑖×𝑘ℎ×𝑘𝑤,这里的c0即输出通道数,假如有3个3通道的卷积核,每个3通道的卷积核都与多输入通道的矩阵卷积运算分别得到一个输出,这样一共就有3个输出结果。
因此我们能得到多输出通道的卷积计算函数
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)我们使用一个多输出通道的卷积核与上面的多输入通道矩阵进行卷积计算,看看其计算结果。
卷积核:

计算结果:

上面的第一个输出通道的计算结果同上,第二、三个结果我们手算一遍也能发现它是正确的。
3. 1×1卷积层
1×1的卷积层有什么用呢?我们来使用它计算一下就能得知它是将每个通道的特征加权累加起来,得到一个输出结果,因为1×1卷积核与特征矩阵运算就是将每个元素都乘上卷积核的值再与其他的通道的结果相加,也就是上面说的加权累加。我们可以发现1×1卷积核进行卷积运算很类似全连接的线性运算,事实也是如此,因此我们通常会使用全连接层的矩阵乘法进行计算1×1卷积。
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
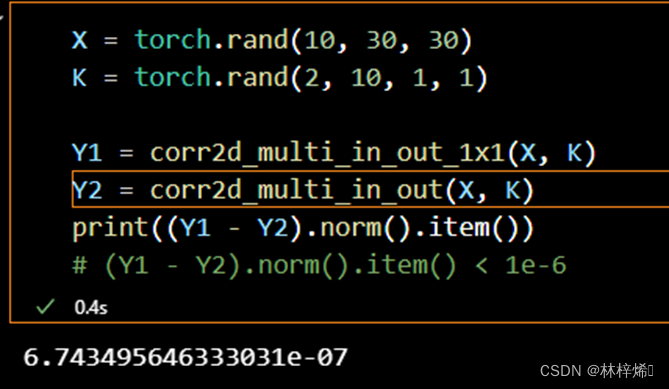
return Y.reshape((c_o, h, w))分别使用上述函数和之前的多输出通道函数计算1×1卷积,看看二者结果是否相同。

可以看出二者的计算结果是相同的。
三、卷积神经网络(LeNet)
上面我们已经介绍过什么是卷积神经网络,简单来说,卷积神经网络就是包含卷积层的神经网络,其与全连接层是类似的,只是从线性运算变为卷积运算而已。
1. LeNet模型
LeNet模型包含卷积层模块和全连接层模块两个部分。
卷积模块中包含有卷积层和池化层,卷积层是用来是吧图像中的空间模型,如检测边缘,检测线性、形状等图像信息,池化层则是将一个范围内的特征的值缩小为只有一个,来降低卷积层对位置的敏感性,这里使用的是最大值池化层,也就是只取一个范围内的特征值的最大值,达到减少特征的效果。在每次卷积计算完,还要对输出进行激活,使得模型能适应更复杂的数据。
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=3, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 6 * 6, 256), nn.ReLU(),
nn.Linear(256, 120), nn.ReLU(),
nn.Linear(120, 84), nn.ReLU(),
nn.Linear(84, 10))上述代码定义了一个LeNet模型,它的卷积层块包含两个卷积运算和两个池化,全连接块包含三个全连接层。
我们同样使用fashion_mnist数据集进行训练测试我们的模型
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)卷积神经网络的训练和预测与之前的步骤类似,都是首先定义损失函数和优化函数,再初始化权重和偏置,接着对每个批次的数据进行训练,计算预测值与实际值之间的损失,再使用梯度下降法不断更新优化参数来降低损失,最后打印每个训练周期的损失值。
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)。"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,范例数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')训练结果: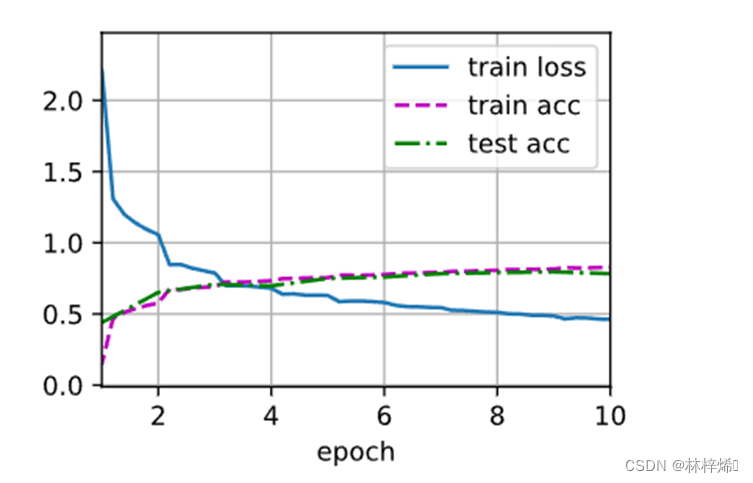
经过10个周期的训练后,得到的精确度已经达到0.8左右,与之间softmax回归得到的精确度差不多,是个不错的结果。
四、实验总结
卷积神经网络是包含卷积层的神经网络,卷积层是特征与卷积核进行卷积运算的层。卷积运算通常被用在图像的处理中,卷积运算是通过将一个范围内的值加权累加起来,通过更改的卷积核,我们能够得到矩阵中一个范围内的值与相邻的值的关联,因此卷积运算能够提取图像的边缘和形状信息,因此卷积神经网络通常会用在图像数据集中。通常在进行卷积运算后我们还要进行池化来减少特征的数量,以减少卷积层对位置的敏感性。
假设输入形状为ci x h x w,且使用形状为c0 x ci x kh x kw、填充为(ph,pw)、步幅为(sh,sw)的卷积核。那么这个卷积层的前向计算分别需要多少次乘法和加法?计算过程如下:
首先每个输入通道进行卷积运算,每个输入通道每一列卷积运算需要(h+2ph-kh)/sh + 1次乘法,每次乘法完后还有kh x kw-1次的加法,共((h+2ph-kh)/sh + 1) x (kh x kw-1)次加法,行需要(w+2pw-kw)/sw + 1次乘法,每次乘法完后还有kh x kw-1次的加法,共((w+2pw-kw)/sw + 1) x (kh x kw-1)次加法,各个通道计算完后还需要一次加法,共(h+2ph-kh)/sh + (w+2pw-kw)/sw + 2次乘法,((h+2ph-kh)/sh + (w+2pw-kw)/sw + 2) x (kh x kw-1)次加法,共ci个输入通道,结果乘以ci,输入通道计算完,输出通道为c0,前面的计算需要计算c0遍,再将结果乘以c0,共c0 x ci x((h+2ph-kh)/sh + (w+2pw-kw)/sw + 2)次乘法,c0 x ci(((h+2ph-kh)/sh + (w+2pw-kw)/sw + 2) x (kh x kw)- 1)+ c0次加法。
翻倍输入通道数ci和输出通道数c0会增加多少倍的计算?翻倍填充呢?
从上面的计算结果可以得出,最终计算的次数与c0和ci成正比,翻倍输入通道数和输出通道数则会增加4倍的计算,翻倍填充对计算次数影响不大,当h很大时,翻倍填充并不会显著增加计算,对计算次数的影响很小。
如果卷积核的高和宽kh=kw=1,能减少多少计算?
如果卷积核的高和宽都为1,对乘法的计算次数的影响不大,因为一般输入矩阵的大小都远大于卷积核的大小,但加法的计算次数会得到显著的减少,因为加法计算的次数与卷积核的大小是成正比的,卷积核的高和宽为1时,比不为1能减少c0 x ci(((h+2ph-kh)/sh + (w+2pw-kw)/sw + 2) x (kh x kw - 1)- 1)+ c0次的计算。
在第二节多输入通道何多输出通道中,最后一个例子中的变量Y1和Y2并不会完全一致,当输入矩阵很大时,二者的数值有微小的差别,这是因为浮点数运算会有精度误差,两种不同的方式计算出的结果在精度上可能会有一点差距,但这个差距是很小的,通常会小于10的-6次方。















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









