







目录
一、线性回归的从零开始实现
1. 生成数据集
从零开始,为了使算法更易实现,让我们能更快的掌握算法的流程,我们自己构造一组简单的数据,然后使用它作为我们初次实现线性回归的数据集。
由于我们人只能直观的观察三维以下的数据,因此我们将特征个数设为2。
数据集中的数据我们选择从简单的标准正态分布中选取,标准差设为1。
随后我们随机选择一个权重值[4.3, 5.7],偏差值b选择2.1,并添加一个噪声项ε,噪声值我们假设其服从正态分布,为了简化问题,将标准值设为0.01,均值设为0,这样标签值则为:
y = Xw + b + ε
初始化线性回归模型参数:
true_w = torch.tensor([4.3, 5.7])
true_b = 2.1将生成数据集的操作包装为函数,传入权重值w和偏差值b以及样本个数,返回数据集,数据集包括特征值和标签值,为了方便后续计算,我们将特征值和标签拆分存入不同的torch中。
def synthetic_data(w, b, num_examples):
X = torch.normal(0, 1, (num_examples, len(w))) # 最后一个参数指定X维度,len(w)特征个数
y = torch.matmul(X, w) + b # 矩阵乘法
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))如上述代码,首先使用torch的normal函数生成形状为(num_examples, len(w))的从标准差为1的标准正态分布中取出的数据构成的数据集。
随后计算标签值y,使用torch的matmul函数将数据集和权重值相乘再加上偏差值b,最后再添加上一个噪声值,噪声值从标准差为0.01的标准正态分布中取值,形状与y相同便于运算。
最后返回特征值和标签值,为了后续计算方便,将标签y形状由行向量改为列向量
打印输出特征和标签后可以看到特征为1000*2的向量,每行包含两个特征值,共1000个样本,标签值为1000*1的向量,每行包含一个标签值,共1000行,且标签值与特征值每一行一一对应。
接着我们使用d2l包的scatter函数进行绘制散点图,通过散点图我们可以直观的观察到两个特征与labels之间的关系。
d2l.set_figsize()
d2l.plt.scatter(features[:, 0].detach().numpy(), labels.detach().numpy(), 1) # 最后一个参数是点的大小分别使用features[:, 0]和features[:, 1]观察各个特征与标签的关系


2. 读取数据集
GPU拥有并行运算的优势,因此我们可以将数据集进行拆分一定大小的小批量,GPU可以对小批量中的每个样本进行并行运算,且样本损失函数的梯度也可以被并行计算,GPU并行运算多个样本所花的时间也不会比运算一个样本多多少。
因此我们对数据集进行遍历时,每次从数据集中抽取一个小批量的样本进行并行计算。
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]上述代码即为用于抽取小批量的函数,传入小批量大小,特征矩阵,标签向量,返回一个可迭代的生成器。
这里使用的yield则使用于一次次返回一个小批量,对其进行迭代就可以一次次抽取一个小批量的样本直到抽取完毕。
注意返回小批量可能会超出样本的范围,比如批量大小不能整除样本数时,最后一次抽取小批量就会抽取到超过样本大小的范围,造成数组越界,因此我们需要进行约束,使用min(i + batch_size, num_examples) 确保下标不会超出样本大小的范围。
下面我们对样本进行抽取大小为10的小批量的测试(这里只打印第一个小批量)
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break输出结果如下:

3. 初始化模型参数
在开始使用梯度下降法优化模型参数前,我们先初始化模型参数,选取一个合适的初始权重值w和偏差值b,权重值选择从标准差为0.01、均值为0的正态分布中取值,偏差值设为0.
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)4. 定义模型
我们使用的是线性模式,因此要计算模型的输出y,则将特征X乘上权重w再加上b即可,X与w的乘法使用torch包的matmul()函数实现。
def linreg(X, w, b): #@save
return torch.matmul(X, w) + b上面的函数即为计算模型输出的函数,传入特征X、权重w、偏差b,返回模型输出y。
5. 定义损失函数
我们训练模型使用的方法是梯度下降法,这里的梯度即为损失函数关于模型参数的梯度,通过不断向减小损失的方向更新模型参数即可得到较为准确的结果。这里我们使用的损失函数为均方损失函数。
def squared_loss(y_hat, y): #@save
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2上述函数实现了均方损失函数的计算,传入预测值y和实际值y,返回均方损失。
为了保证y_hat和y之间形状相同,避免计算时出现错误,因此在计算是需要将y或者y_hat reshape成y_hat或y的形状。
6. 定义优化算法
在对模型参数进行训练前,需要先定义优化算法来优化模型参数。这里我们使用小批量随机梯度下降法,首先从数据集中抽取一个小批量,然后计算损失函数的梯度,接着根据梯度向着损失减少的方向更新参数,更新的步长为学习率,我们需要选取合适的学习率以保证模型能很好的收敛。
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()如上图代码所示,因为损失函数的梯度是其增加最快的方法,我们只需将参数减去其乘上学习率(步长)的积即可实现向梯度下降的方向更新,在更新模型时不需要反向传播,因此使用with torch.no_grad()防止计算被跟踪,同时由于梯度是累加的,在更新完后需要将梯度清零以免影响后续更新操作。
7. 训练模型
我们已经准备好了模型训练所需的所有要素,现在我们可以开始训练模型了,我们每次从数据集中抽取一个小批量的数据,根据小批量中的数据和模型参数,我们可以得到计算的结果y_hat,将y_hat和y传入损失函数进行计算小批量损失,接着再计算损失函数的梯度,再根据梯度优化更新参数,在更新完后,我们可以测试更新后的效果。
实现代码如下:
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
y_hat = net(X, w, b)
l = loss(y_hat, y) # `X`和`y`的小批量损失
# 因为`l`形状是(`batch_size`, 1),而不是一个标量。`l`中的所有元素被加到一起,
# 并以此计算关于[`w`, `b`]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad(): #前分批次训练,测试更新后的效果
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')在多次测试后发现学习率为0.1时训练效果最好,0.03也可以
输出结果:
学习率为0.1

学习率为0.3
最后输出w和b的误差:

二、线性回归的简易实现
我们已经掌握了线性回归从零开始实现,现在我们来尝试使用框架来轻松实现线性回归
1. 生成数据集
数据选取与之前相同,不过这次我们不用自己手动写一个生成数据集的函数,而是使用d2l包中的synthetic_data()函数进行自动生成数据集。
true_w = torch.tensor([4.3, 5.7])
true_b = 2.1
features, labels = d2l.synthetic_data(true_w, true_b, 1000)2. 读取数据集
读取数据集同样可以使用现有的框架来实现,我们调用框架中的API来构造一个pyTorch数据迭代器来实现批量抽取数据。
def load_array(data_arrays, batch_size, is_train=True):
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)上述函数传入特征矩阵、批量大小、是否希望迭代器在每个迭代周期打乱顺序,返回一个批量数据迭代器。
3. 定义模型
我们可以通过实例化Sequential类将多个层串联到一起,它可以将上一层的输出作为下一层的输入,这样我们就只需关注使用哪些层来构造模型,而不必关注各个层实现的细节,大大简化了我们的操作。虽然本次实验我们的模型只包含一层,但使用Sequential类也能让我们更好的熟悉“标准的流水线”
net = nn.Sequential(nn.Linear(2, 1))实例化Sequential类时需要传入全连接层,全连接在Linear中定义,我们将输入特征形状和输出特征形状传入Linear中。
4. 初始化模型参数
我们需要使用的只有网络中的第一层,因此我们访问第一层的w和b并使用normal_()和fill()函数分别重写w和b的值,将它们的值初始化。
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)5. 定义损失函数
损失函数同样可以使用已有的API进行实现,MSELoss类、SmoothL1Loss类等,这里我们使用MSELoss类
loss = nn.SmoothL1Loss()6. 定义优化算法
Pytorch在optim模块中实现了小批量随机梯度下降算法,我们可以通过实例化SGD来使用它,在实例化SGD时,我们需要指定优化的参数。
trainer = torch.optim.SGD(net.parameters(), lr=0.03)7. 训练
训练方法与线性回归从零开始实现相同,只是实现函数替换为了已有的API
num_epochs = 3
for epoch in range(num_epochs):
# 每次取一个小批量
for X, y in data_iter:
# 计算损失
l = loss(net(X) ,y)
# auto_grad的梯度是累加的,再每次训练前需要先将之前的梯度清零
trainer.zero_grad()
# 反向传播计算梯度
l.backward()
trainer.step()
l = loss(net(features), labels)
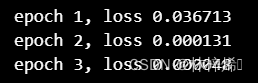
print(f'epoch {epoch + 1}, loss {l:f}')输出结果:
学习率为0.03

















 88
88











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









