







前言
初学Python,总会遇到这样那样的问题,最近学到了文件这一版块儿,本以为看看视频,在依葫芦画瓢就Ok了,可文件读取却给我上了眼药,必须解决
描述及实现
read()读取报错及解决
网上找了篇现代诗复制到记事本,然后用Python代码来读取,报错

默认读取的编码为cp936,但显然读取不了,改为utf-8就好了
用记事本打开也可看出文件编码为utf-8

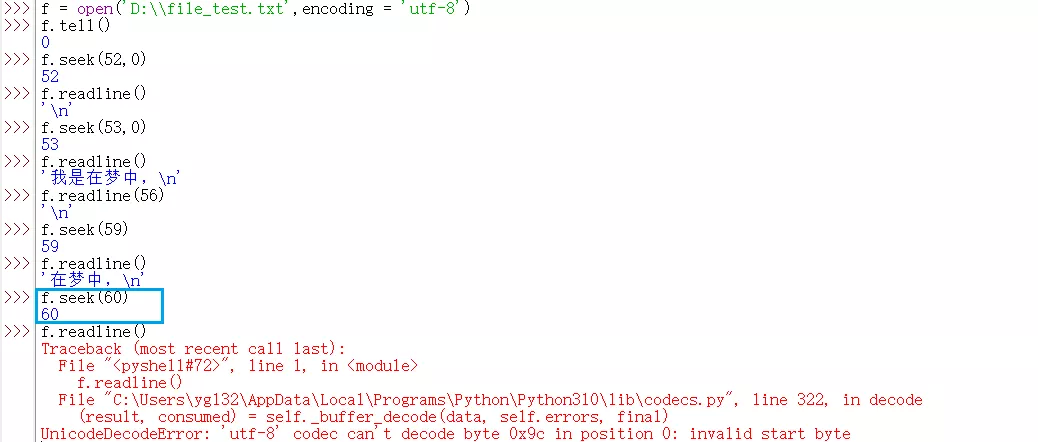
readline()报错及解决
将文件指针移到60字节处报错,移到53、56、59为什么不报错,这个是因为使用f.seek()定位的文件指针是按字节为单位进行计算的,演示文件是以utf-8编码的,按照规则,一个汉字要占三个字节(注意:以GBK编码,一个汉字要占两个字节),f.seek(59)的位置位于字符的开始位置(或结束位置),因此可以正常打印,而f.seek(60)正好位于字符中间位置,无法将编码进行解码
至于readline()读取的结果为什么是这样,没弄清楚,但可以知道readline()报错怎么解决
补充
编码解码的概念可以简单理解为把字符转为字节,而解码就是把字节转为字符
升华
因为复制过来的现代诗中间有一空行,于是打算用Pyghon来删除空行,正好实践下
#原理就是将原文件中的空行去除,然后写入到新文件中
f = open('D:\\file_test.txt',encoding = 'utf-8') #要删除空行的文件
f1 = open('D:\\file_test1.txt','x',encoding = 'utf-8') #要写入的文件,该文件原来并不存在
for line in f.readlines():
if line == '\n':
line = line.strip('\n') #strip 去除 意思是判断所读取到的是空行,就去除掉
f1.write(line)
f.close() #要记得写入操作完成后关闭,以免缓存所写入的数据因突然断电而丢失
f1.close()运行如图

效果如图

总结
Python读取文件容易出现编码问题,还有就是文件指针所在位置问题,学了Python终于可以干点实事,用它来去除文本文件中的空行,别说,还挺好使















 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









