







前言
昨天在得到听吴军老师的硅谷来信时,想起了吴军老师所说的这句话,买的不如卖的精,于是就去文档找这句话的原位置,结果愣是没找着,年纪大了,眼神也不好使了,这不正在学正则表达式,那就学以致用。
解决过程
第一阶段
直接借助正则表达式在线验证网站来达成,而这个网站是由白月黒羽up主推荐的
有图有真相
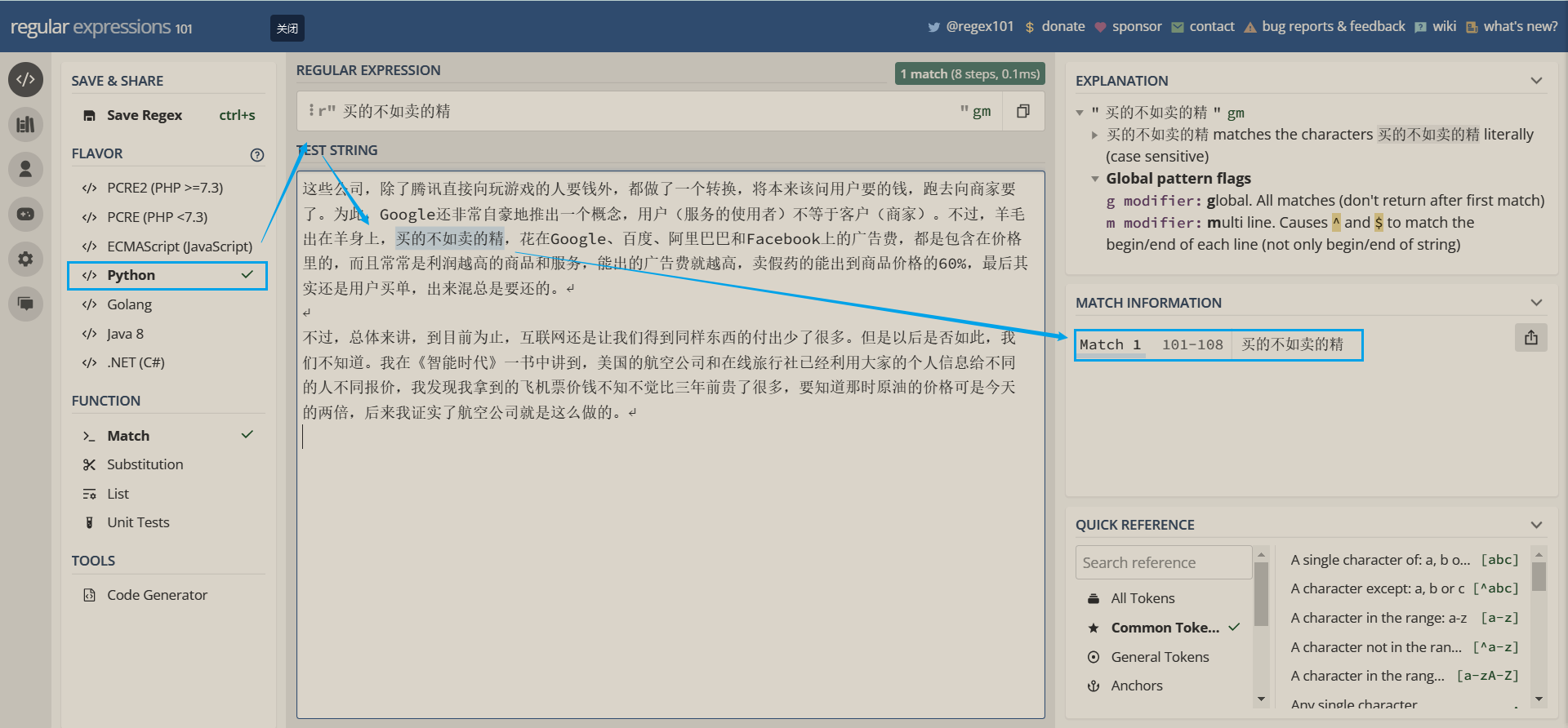
第二阶段
作为一名计算机专业人士,不能这么草率了事,要学会用编程解决问题
代码实现
import re
with open('D:\Python_txt\内容高亮.txt',encoding = 'utf-8') as f:
p = re.compile(r'买的不如卖的精')
content = f.read()
print((p.search(content)).span())
运行结果显示

当然这种实现效果不是很好,所以我的想法是对文本文件中的指定内容进行多颜色注解,并以docx文档格式输出,暂时是实现了,想做个图形化界面出来,毕竟这种需求不算虚假需求
学习记录
正则表达式的入门,我是看鱼C论坛小甲鱼写得正则表达式文档和白月黑羽up主的视频
元字符.的使用
题目:提取一段文本中带颜色的文字块
苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
直接实现如下
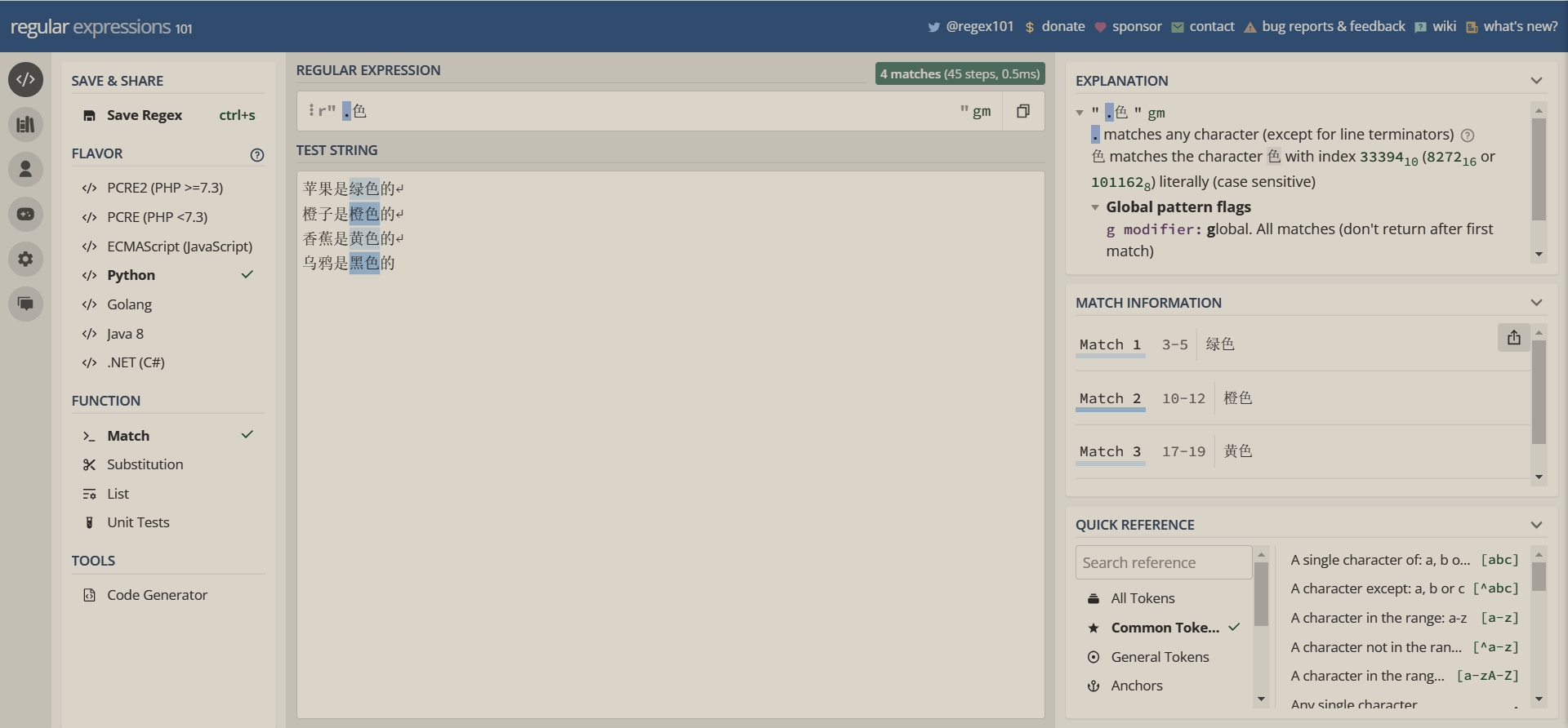
代码实现
content = '''
苹果,是绿色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,是无色的
'''
import re
p = re.compile(r'.色')
for one in p.findall(content):
print(one)

要知道正则表达式中的.几乎匹配任意一个字符,但不匹配换行符\n
正则表达式被编译为模式对象,该对象拥有各种方法供你操作字符串,如findall(),遍历字符串,找到正则表达式匹配的所有位置,并以列表的形式返回
元字符*的使用
题目:匹配文本中逗号及其后面的文字块
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
直接实现

代码实现
content = '''
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
'''
import re
p = re.compile(r',.*')
for one in p.findall(content):
print(one)
正则表达式中*这个元字符用于指定前一个字符匹配零次或者多次
元字符+的使用
正则表达式中+这个元字符用于指定前一个字符匹配一次或者多次,与元字符*有点区别
直接上图演示


元字符{}的使用
正则表达式中{}这个元字符用于指定前一个字符匹配次数,可以说是*和+的升级版
上示例
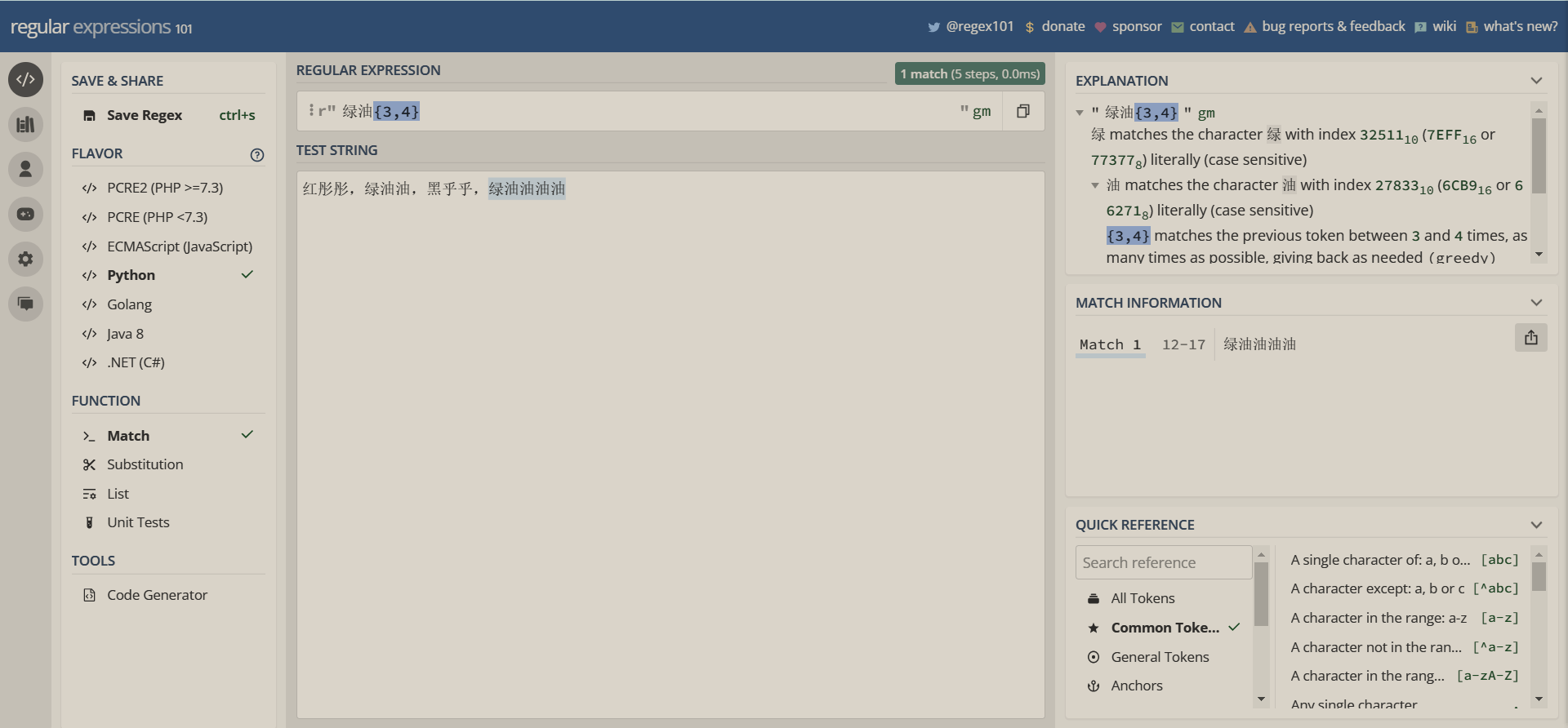
通常使用的形式是这种{m,n}(m和n都是十进制数),它的含义是前一个字符必须匹配m次到n次之间
m和n可以省略,省略m,将被解释为下限为0;省略n则会被解释为无穷大
如果是{n},则是重复前一个字符n次
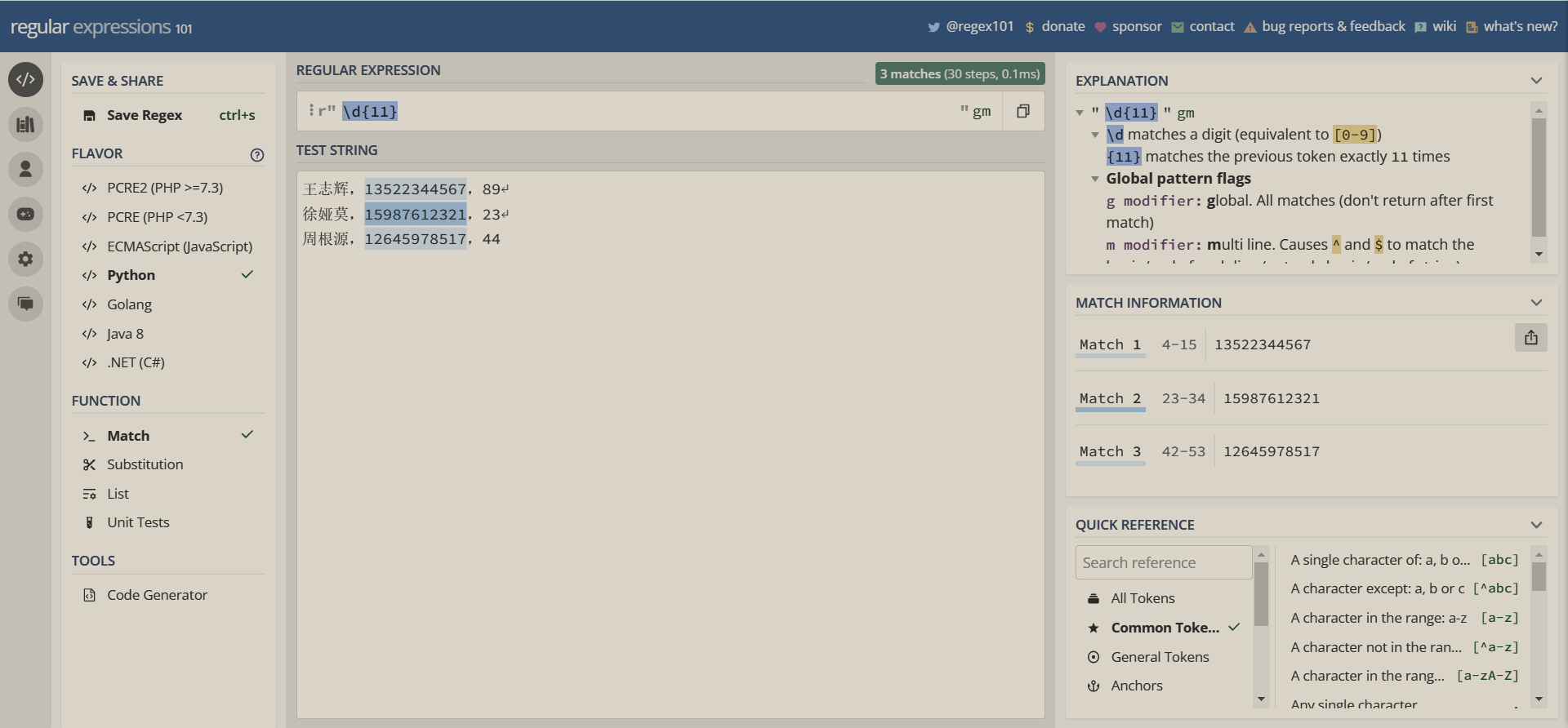
实际场景应用
国内手机号码通常为11位,于是在这段文本内提取手机号码
王志辉,13522344567,89
徐娅莫,15987612321,23
周根源,12645978517,44
实现如图
小结
正则表达式很好用也很重要(听说哈),所以还是得学好,毕竟书到用时方恨少。
















 6891
6891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









