






心得:
第一题:限制条件也可以放在递归函数里,不一定要写辅助函数。
求自增子序列,是不能对原数组进行排序的,排完序的数组都是自增子序列了。所以不能使用之前的去重逻辑!要保证同一个父节点同层的重复数字不能用,同一个树枝的可以重复。用一个unordered_set或者哈希表来保存有没有用过这个数。
第二题:递归的终止条件可以直接用path.size和nums.size来判断,灵活一点!
还是用一个布尔数组来记录当前的数字是否用过,只用没有用过的数字加入答案数组。
第一题、递增子序列 LeetCode491 https://leetcode.cn/problems/non-decreasing-subsequences/
给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。
数组中可能含有重复元素,如出现两个整数相等,也可以视作递增序列的一种特殊情况。
求自增子序列,是不能对原数组进行排序的,排完序的数组都是自增子序列了。所以不能使用之前的去重逻辑!要保证同一个父节点同层的重复数字不能用,同一个树枝的可以重复。用一个unordered_set或者哈希表来保存有没有用过这个数。
限制条件不用局限于辅助函数: 限制答案集要两个以上,直接放在res.push_back前;限制条件递增,直接在递归的for里用nums[i] >= path.back();
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
void backetracking(vector<int>& nums, int startIndex){
if(path.size() > 1){
res.push_back(path);
}
//unordered_set<int> uset;
int used[201] = {0};
for(int i = startIndex; i < nums.size(); i++){
if((!path.empty() && nums[i] < path.back())
//|| uset.find(nums[i]) != uset.end()){
|| used[nums[i] + 100] == 1){
continue;
}
//uset.insert(nums[i]);
used[nums[i] + 100] = 1;
path.push_back(nums[i]);
backetracking(nums, i + 1);
path.pop_back();
}
return;
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
res.clear();
path.clear();
backetracking(nums, 0);
return res;
}
};第二题、全排列 LeetCode46 https://leetcode.cn/problems/permutations/
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
我以[1,2,3]为例,抽象成树形结构如下:
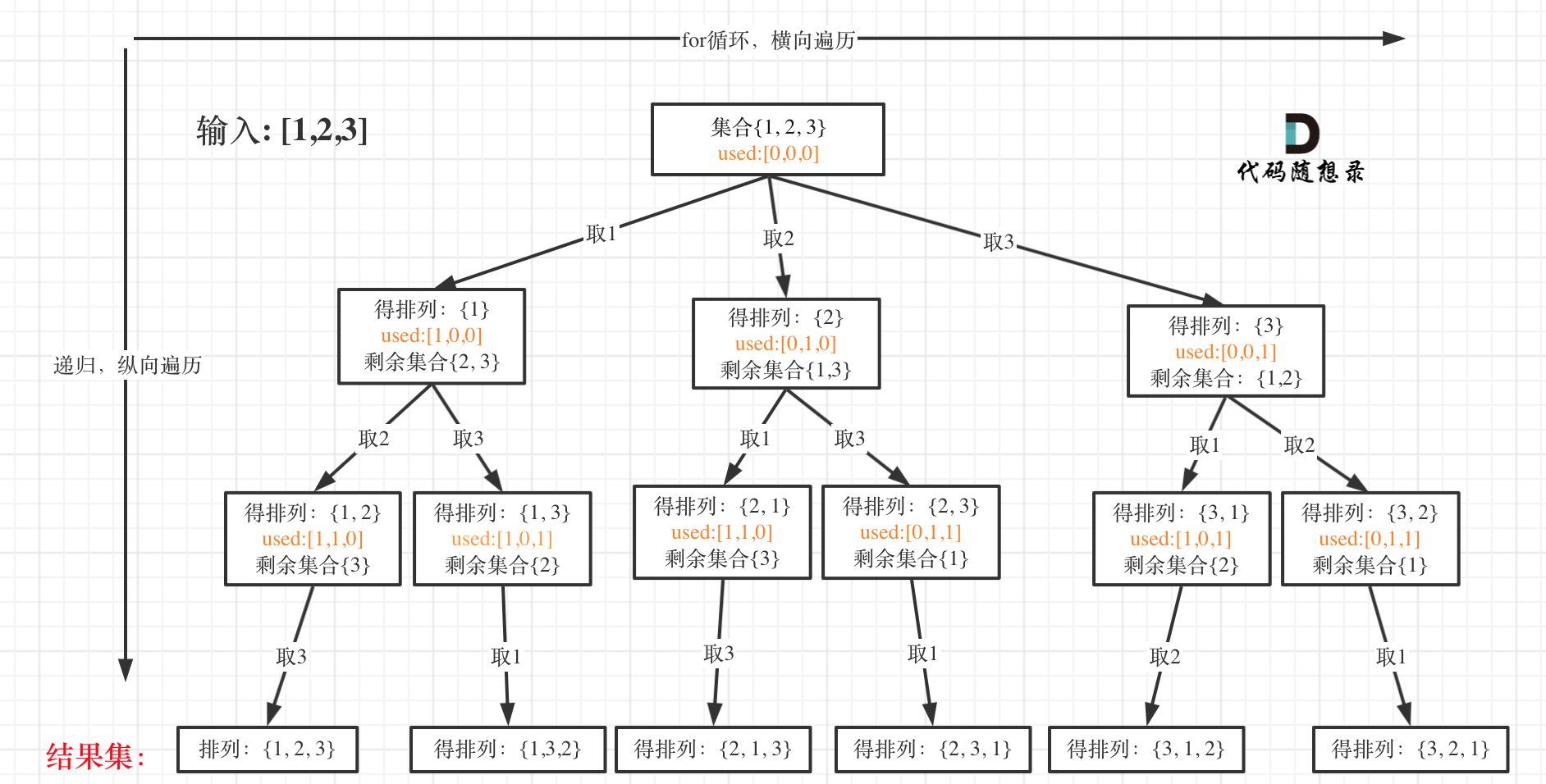
首先是思维要灵活,递归的终止条件可以直接用path.size和nums.size来判断。
其次是用一个bool数组来判断当前的数有没有被用过。
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
void backtracking(vector<int>& nums, vector<bool> used){
if(path.size() == nums.size()){ //直接用path来看数量够不够
res.push_back(path);
return;
}
for(int i = 0; i < nums.size(); i++){
if(used[i] == true){
continue;
}
path.push_back(nums[i]);
used[i] = true;
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
vector<vector<int>> permute(vector<int>& nums) {
res.clear();
path.clear();
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return res;
}
};第三题、全排列-3 LeetCode47 https://leetcode.cn/problems/permutations-ii/
和上一题相比,数组中会出现重复的元素,因此要用num[i] == nums[i - 1] 来判断和上一个元素是否相等。
这里又涉及到去重了。
在40.组合总和II (opens new window)、90.子集II (opens new window)我们分别详细讲解了组合问题和子集问题如何去重。
那么排列问题其实也是一样的套路。
还要强调的是去重一定要对元素进行排序,这样我们才方便通过相邻的节点来判断是否重复使用了。
我以示例中的 [1,1,2]为例 (为了方便举例,已经排序)抽象为一棵树,去重过程如图:
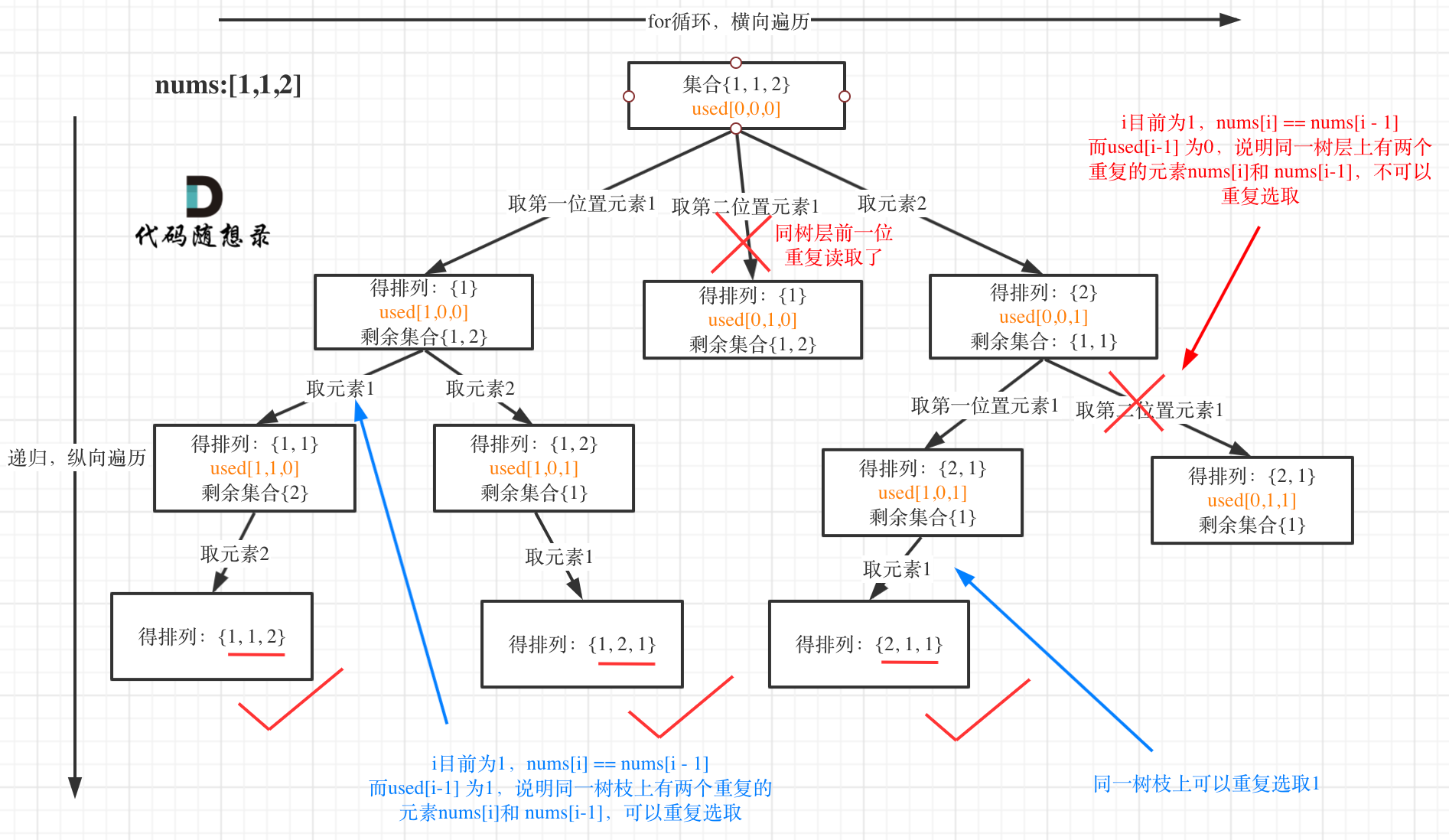
图中我们对同一树层,前一位(也就是nums[i-1])如果使用过,那么就进行去重。
一般来说:组合问题和排列问题是在树形结构的叶子节点上收集结果,而子集问题就是取树上所有节点的结果。
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
void backtracking(vector<int>& nums, vector<bool>& used){
if(path.size() == nums.size()){
res.push_back(path);
return;
}
for(int i = 0; i < nums.size(); i++){
if(i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false){
continue;
}
if(used[i] == false){
path.push_back(nums[i]);
used[i] = true;
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
return;
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
res.clear();
path.clear();
vector<bool> used(nums.size(), false);
sort(nums.begin(), nums.end());
backtracking(nums, used);
return res;
}
};
大家发现,去重最为关键的代码为:
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
continue;
}
如果改成 used[i - 1] == true, 也是正确的!,去重代码如下:
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) {
continue;
}
这是为什么呢,就是上面我刚说的,如果要对树层中前一位去重,就用used[i - 1] == false,如果要对树枝前一位去重用used[i - 1] == true。
对于排列问题,树层上去重和树枝上去重,都是可以的,但是树层上去重效率更高!
这么说是不是有点抽象?
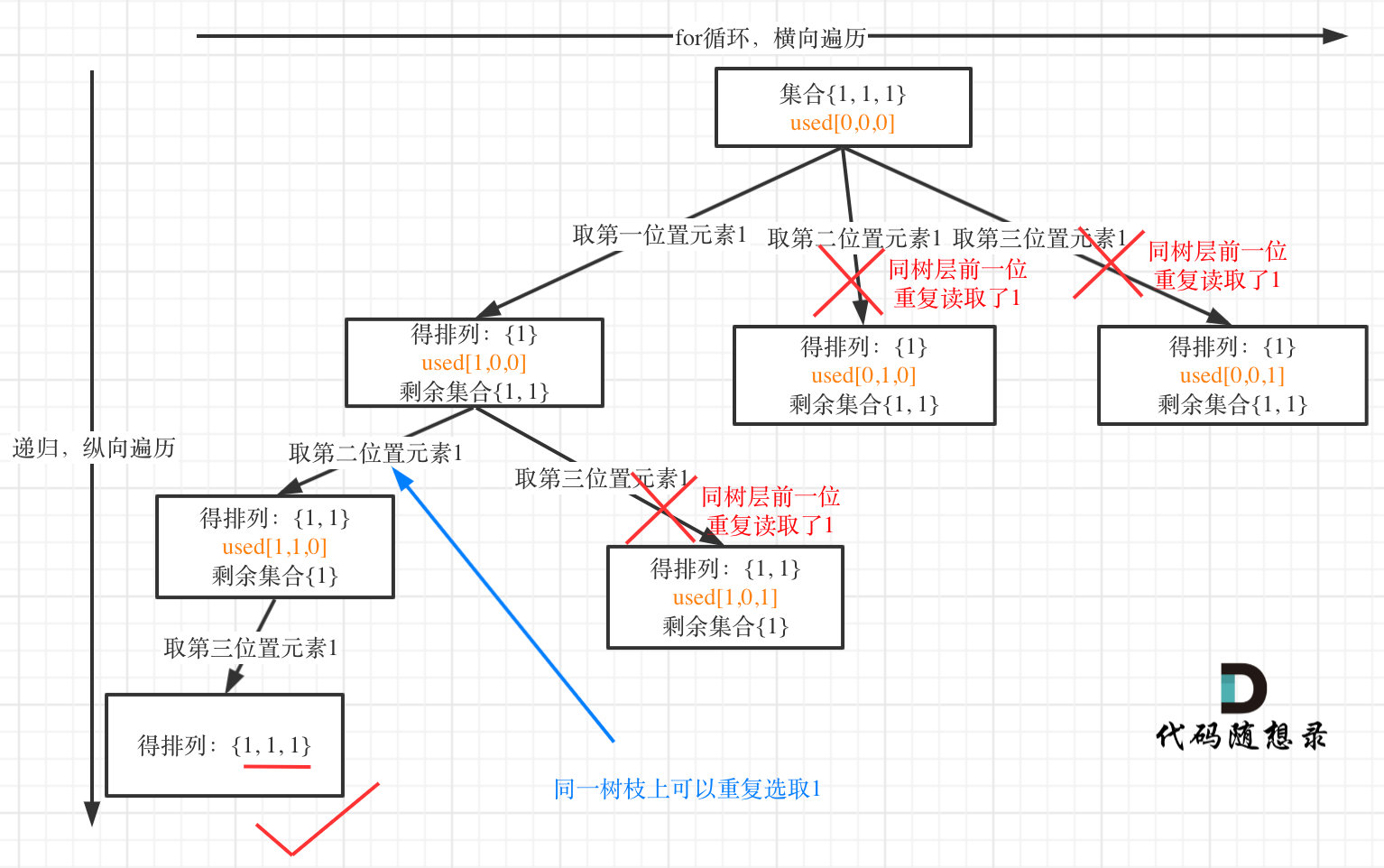
来来来,我就用输入: [1,1,1] 来举一个例子。
树层上去重(used[i - 1] == false),的树形结构如下:
树枝上去重(used[i - 1] == true)的树型结构如下:
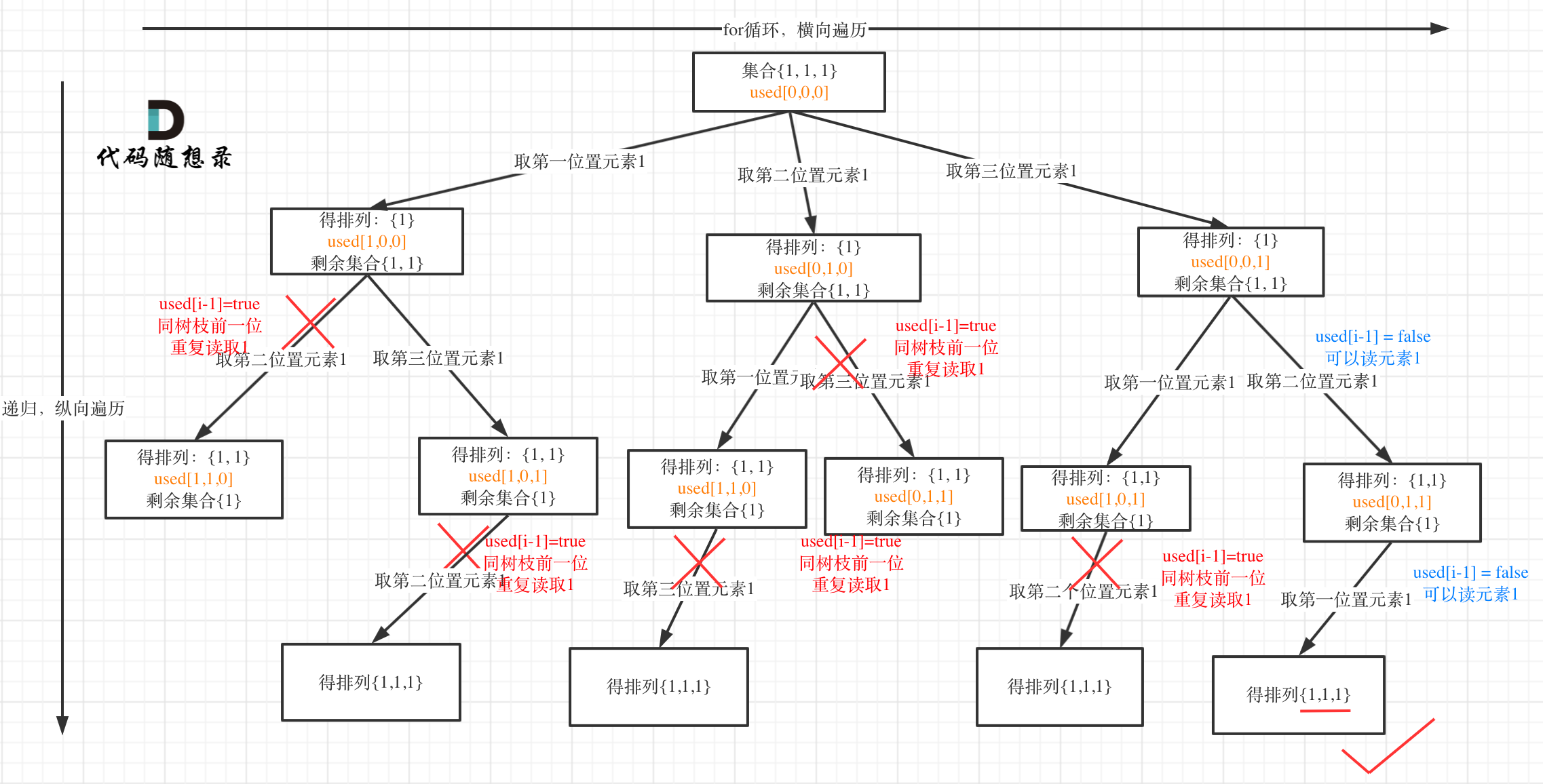
大家应该很清晰的看到,树层上对前一位去重非常彻底,效率很高,树枝上对前一位去重虽然最后可以得到答案,但是做了很多无用搜索。















 1073
1073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









