







作者:刘旭晖 Raymond 转载请注明出处
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
Dryad的论文是微软早在2007年就发布的,Tez的核心思想来源于Dryad,差不多可以算是Dryad的开源实现吧。最近正好看到几个有趣的项目是基于Tez实现的,于是顺便追本溯源,学习了一下Dryad的理论基础
== 目标问题 ==
Dryad的设计目标和当时先后出现的各种分布式运算框架一样,是为了简化大规模分布式编程的难度,提供给用户一个简单通用的分布式运算框架。和其它分布式运算框架解决的问题类似,不外乎就是用户不需要考虑分布式运算所涉及的众多繁琐的问题,例如资源分配,并发调度,系统容错等等,而只需要关注核心运算逻辑。
== 核心思想 ==
按照官方定义,Dryad是一个通用的粗颗粒度的分布式计算和资源调度引擎,这里所说的粗颗粒度,自然指的是针对批量数据进行处理的这种应用模式,当然批处理的粒度可大可小。
Dryad的核心数据模型由Vertex计算节点和Channel数据通道两部分组成,用户通过实现自定义的Vertex节点来执行定制的运算逻辑,而节点之间通过各种形式的数据通道传输数据,用户的运算逻辑本身通常是顺序执行的,而与分布式相关的逻辑则由Dryad框架来实现。
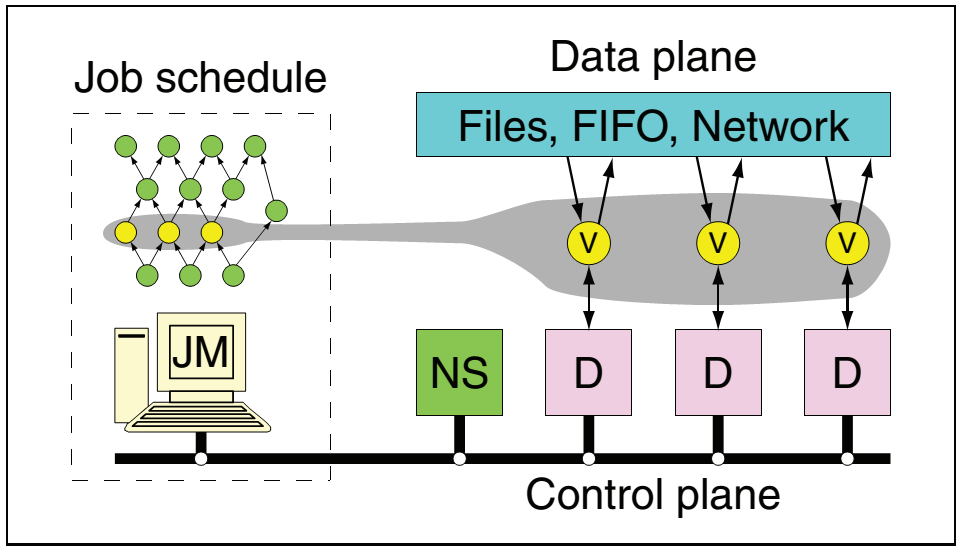
如图所示的是Dryad的系统架构框图。Dryad的作业管理模块JM在应用程序内部维护了一个基于DAG图模型的计算节点依赖关系图,作业管理模块通过命名服务器NS来获取可用的服务器列表,而后通过在这些服务器上运行的守护进程Daemon来调度和执行计算节点Vertex。各个计算节点之间通过例如文件,管道,网络等形式的数据通道交换数据。
表面上看,从整体的概念来说,Dryad和MapReduce十分相似,所不同的就是MapReduce的用户逻辑分为Map和Reduce两个阶段,在Dryad里就只有不分阶段的Vertex一个概念。不过这一点恰恰就是它与MapReduce区别的关键。
从用户使用的角度来说,MapReduce强制定义了Map和Reduce两个阶段,以及两阶段之间的数据输入输出格式。用户程序通过套用这种模型来抽象自身的运算逻辑,带来的好处是,简化了用户编程接口,降低编程难度,同时在这种模型的基础上MapReduce框架可以自动完成各种调度优化和容错处理工作。但是固定的编程模型自然也就在一定程度上限制了它的通用性,比如MR模型中所有的计算节点只能接受统一格式的一组输入数据,也只能输出一组数据,无论是否需要,用户逻辑都必须由匹配的Map和Reduce阶段组成等等。
为了具备更大的通用性,Dryad从模型上不区分运算阶段,从框架的角度上也不定义各个计算节点之间的数据交换格式,而是由具体的需要相互通讯的计算节点自己处理数据的格式兼容问题。这样做在一定程度上当然增加了用户的编程难度,例如就可能需要针对具体计算节点的实现,编写各种Channel数据通道的实现(当然可以通过实现一些通用的数据通道供用户匹配使用来解决部分问题)但是带来的好处也是显而易见的,就是更加灵活的编程模型。
用户自定义调度拓扑图
Dryad的核心特性之一,是允许用户自己构建DAG调度拓扑图,这个特性正是基于上述的原因而具备了实现的可能性和价值。MapReduce通过隐藏调度逻辑,简化用户编程。与之相反,Dryad期望通过适当增加的编程复杂度,暴露给用户更加灵活的调度编程接口,让用户能够更有效的优化运行逻辑,从而达到提升程序性能的目的。
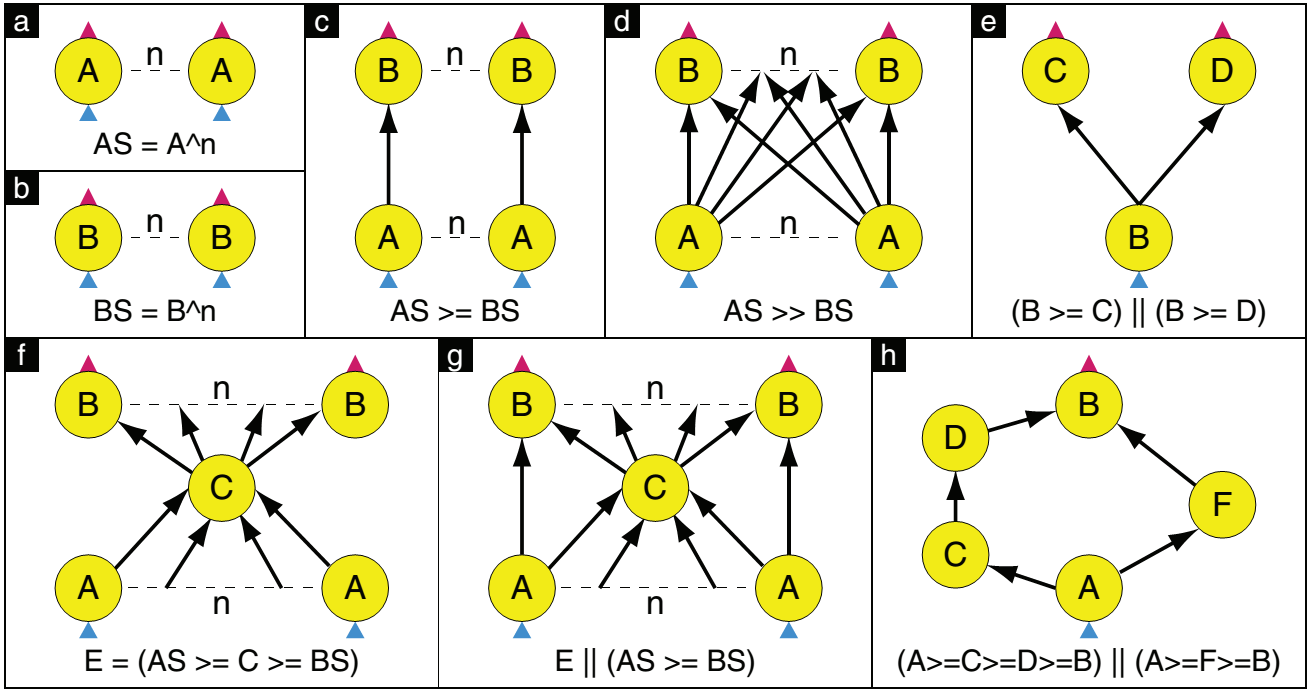
Dryad运行库实现了一个简单的图形描述语言(graph description language)用来构建调度拓扑图,基本的操作原语和例子如下图所示:
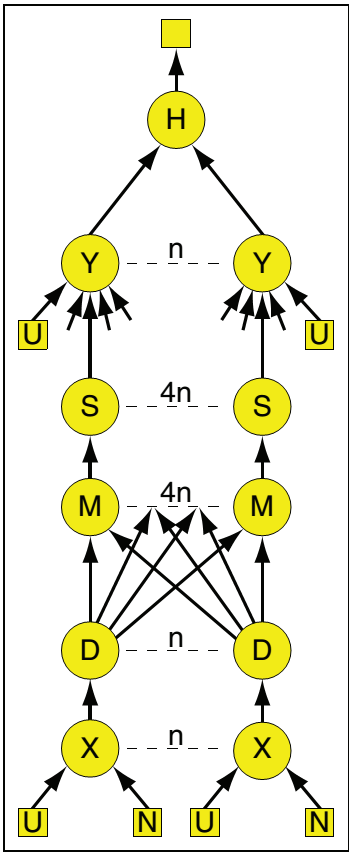
构建一个具体的DAG的例子:
GraphBuilder XSet =moduleX^N;
GraphBuilder DSet =moduleD^N;
GraphBuilder MSet =moduleM^(N*4);
GraphBuilder SSet =moduleS^(N*4);
GraphBuilder YSet =moduleY^N;
GraphBuilder HSet =moduleH^1;
GraphBuilder XInputs= (ugriz1 >= XSet) || (neighbor >= XSet);
GraphBuilder YInputs= ugriz2 >= YSet;
GraphBuilder XToY =XSet >= DSet >> MSet >= SSet;
for (i = 0; i <N*4; ++i)
{ XToY = XToY || (SSet.GetVertex(i) >=YSet.GetVertex(i/4));}
GraphBuilder YToH =YSet >= HSet;
GraphBuilderHOutputs = HSet >= output;
GraphBuilder final =XInputs || YInputs || XToY || YToH || HOutputs;
上述代码构建的DAG图如下所示
动态优化调度逻辑
Dryad的另一个特点是允许用户动态的改变DAG调度拓扑图,这是通过在计算节点中反馈实际所处理的数据的相关信息给作业管理模块来实现的。之所以需要这么做,是因为在很多情况下,最优的调度拓扑结构往往取决于实际的输入数据,中间计算结果或者当时的运行环境,因此无法在编程的时候或者程序启动的时候提前给出最优结构。
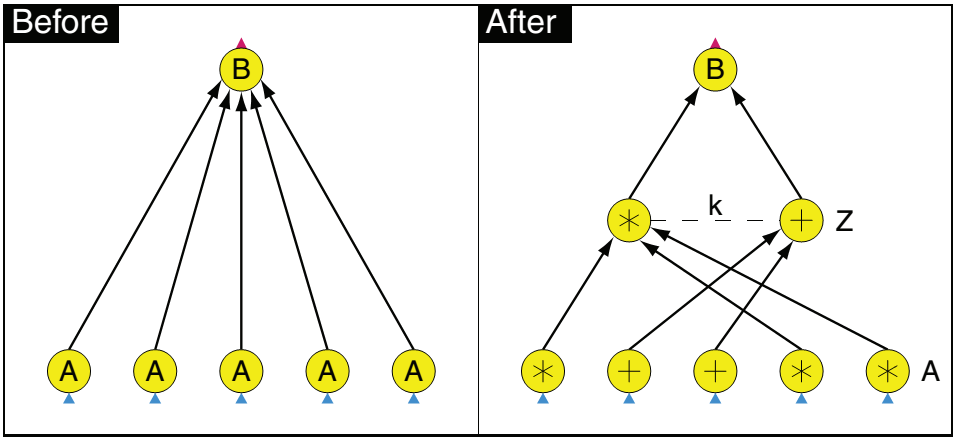
例如图示的一个Aggregation类型的操作,在实际执行的时候,我们通过数据的本地性信息,可以动态的在原有的拓扑图中(A->B)添加一层额外的计算节点(A->Z->B),比如将同一个机架上的数据汇总到同一个中间节点上作一次Aggregation,然后再提交给原拓扑图中的后续节点处理。此外,也可以通过获取实际的数据规模信息,动态调整各个计算节点的并发度来适配程序实际运行情况等等。
当然,这些动态调整的代码逻辑本身需要用户根据自己的业务逻辑来实现,因此在一定程度上对用户来说也是需要付出额外的努力的
== 实现 ==
Dryad的具体实现是否优化合理,实际性能如何,一方面由于它不是开源项目,另一方面我个人也不了解微软的整套软件体系,所有也就无从谈起了,不过有空可以结合Tez这个开源版本的实现来具体分析一下。
== 思考 ==
Dryad的编程模型相对于MapReduce来说固然更加灵活,但是同时也带来了更高的编程门槛。此外,因为数据流程和交互过程更加灵活多变,大概会有很多在MapReduce里适用的各种框架级的优化工作或者通用的处理方法无法在Dryad的框架中应用,因此在易用性上势必受到影响,而如果用户代码不能自己完成这些优化工作的话,应该也会对应用程序的实际性能产生一定的影响。这好比Hadoop2采用Yarn框架来支持更加通用的编程模型,但是要和MapReduce一样,在Yarn的基础上构建自己的模型相关的调度模块,依然需要付出很大的努力,当然不能把Dryad的模型与Yarn简单的资源调度模型直接对比,毕竟Dryad的编程模型还是与MapReduce一样,属于更高层次的概念。
在易用性方便,Dryad的DAG图描述语言固然灵活,但在许多常用case的场合下也显得琐碎,比如并发度的设置等问题,许多情况下应该可以自动决定,各种常用处理流程的DAG拓扑图也相对固定,因此也就需要一些高层封装来简化编程,比如构建在Dryad上的Nebula,用户使用脚本语言的形式编程,Dryad的众多使用细节和动态优化逻辑都被封装在Nebula的方法操作中(例如Filter/Aggregate等),这点思想和Spark中RDD的方法封装调用DAGScheduler作业调度相关操作的思想很接近,即暴露给用户的接口是要做什么,而不是要怎么做。
另外微软的DryadLINQ是LINQ在Dryad上的实现,这里暴露给用户的也是更高层的应用接口,前面提到的各种需要解决的问题同样交给DryadLINQ的框架来处理。
从Paper的描述来看,当时的Dryad在并发,负载,HA等等大规模集群需要考虑的问题方面的处理方式还很简陋,当然经过这么多年的发展,应该在这些方面会有改善和发展,目前的具体情况就不得而知了
Dryad的开源实现Tez所面临的问题大概也是类似,Tez提供了各种通用的channel的实现(如针对MapReduce的应用模式的通道)来简化用户编程难度,但使用Tez依然比使用MapReduce要困难,Tez的稳定性和性能优化方面显然也还有很长的路要走。而Stinger等基于Tez的上层框架显然是希望在借助Tez在调度逻辑上提供的优化空间来提高性能的同时,通过更加高级的编程接口来保证易用性。















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









