







Elasticsearch入门到精通
一、Elasticsearch基础入门
1、Elasticsearch的下载与安装
下载Elasticsearch
访问 Elasticsearch 官网 https://www.elastic.co/cn/downloads/elasticsearch 下载安装包
安装Elasticsearch
运行Elasticsearch
访问ES
http://localhost:9200/
2 、Elasticsearch可视化工具下载
下载elasticsearch-head
项目地址:https://github.com/mobz/elasticsearch-head
安装并启动:
- git clone git://github.com/mobz/elasticsearch-head.git
- cd elasticsearch-head
- npm install
- npm run start
- open http://localhost:9100/
连接ES

连接跨域,需要在es的配置文件elasticsearch.yml中添加配置
http.cors.enabled: true
http.cors.allow-origin: "*"
3、安装kibana
下载
- 官网下载地址:https://www.elastic.co/cn/kibana
- 华为镜像市场:https://mirrors.huaweicloud.com/kibana/ (需先注册一个账号)
修改配置
访问
http://localhost:5601
3、通过可视化工具或者postman请求es服务端CRUD操作
略。。。。
4、Elasticsearch提供的rest接口
| 接口 | 作用 |
|---|---|
| /index/_search | 搜索指定索引下的数据 |
| /_aliases | 获取或者操作索引的别名 |
| /index/ | 查看索引的详细信息 |
| /index/type/ | 创建或者操作类型 |
| /index/_mapping | 创建或者操作mapping |
| /index/_setting | 创建或者操作_setting |
| /index/_open | 打开被关闭的索引 |
| /index/_close | 关闭指定索引 |
| /index/_refresh | 刷新索引(使用新加的内容可见,不保证数据被写入磁盘) |
| /index/flush | 刷新索引(会触发lucene提交) |
5、Elasticsearc配置说明
| 配置 | 说明 |
|---|---|
| cluster.name: my-application | 集群名 |
| node.name: node-1 | 集群中当前ES的节点 |
| path.data: /path/to/data | ES存储的数据目录 |
| path.logs: /path/to/logs | 日志目录 |
| network.host: 192.168.0.1 | 当前虚拟机IP地址的别名 |
| http.cors.enabled: true | 允许别的插件服务访问 |
| http.cors.allow-origin: “*” |
6、curl操作ES
curl的参数:
- -X:指定HTTP的请求方法,GET、PUT等
- -d:指定要传输的数据
- -H:指定请求头信息
7、使用postman操作ES
7.1 创建索引库
put http://localhost:9200/myblog
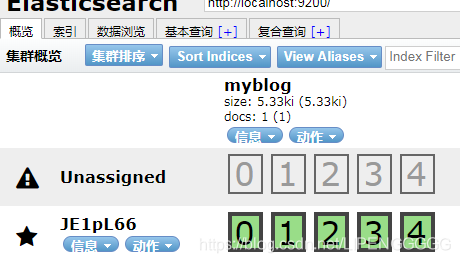
7.2 创建type和文档
post http://localhost:9200/myblog/article/1

7.3更新数据和新增数据一致
7.4 删除
delete http://localhost:9200/myblog/article/1
7.5 查询
根据ID查询
get http://localhost:9200/myblog/article/3
source格式化输出
get http://localhost:9200/myblog/article/3/_source
指定字段输出
get http://localhost:9200/myblog/article/3?_source=title,content
查询所有附加条件
get http://localhost:9200/myblog/article/_search?q=title:2
7.6 批量操作(_bulk)
8、ES插件
8.1 BigDesk Plugin
用于节点实时监控,包括JVM、Lniux的情况
安装地址
https://github.com/lukas-vlcek/bigdesk
安装步骤
8.2 head可视化工具
前面有介绍
9、ES集群
拷贝三份ES,修改配置
第一台机
cluster.name = bigdata
http.port:9200
network.host:0.0.0.0
第二台机
cluster.name = bigdata
http.port:19200
network.host:0.0.0.0
transport.tcp.port:19300
第三台机
cluster.name = bigdata
http.port:29200
network.host:0.0.0.0
transport.tcp.port:29300
启动三个节点
10、ES的几个概念
10.1 _cluster集群
查看集群状态
get http://localhost:9200/_cluster/health
10.2 _shards分片
10.3 _recovery&gateway数据恢复和网关
10.4 _discovery.zen新加节点自我发现机制
10.5 _replicas副本
10.6 _Transport交互
11、java API完成CRUD
11.1 ES连接与关闭
Settings settings = Settings.builder().put("cluster.name","my-application").build();
TransportClient esClient = new PreBuiltTransportClient(settings);
esClient.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"),9300));
esClient.close();
11.2 添加索引文档
JSON方式
//JSON方式添加索引
Article article = new Article(10l,"武松打老鼠","大数达不到大his到死后的撒");
esClient.prepareIndex("bigdata","article","10")
.setSource(JSON.toJSONString(article), XContentType.JSON)
.get();
Map方式
Map<String,Object> data = Maps.newHashMap();
data.put("id",11);
data.put("title","武松打老鼠11");
data.put("content","大数达不到大his到死后的撒11");
esClient.prepareIndex("bigdata","article","11")
.setSource(data)
.get();
Bean方式
Article article = new Article(13l,"武松打老鼠13","大数达不到大his到死后的撒13");
ObjectMapper objectMapper = new ObjectMapper();
byte[] bytes = objectMapper.writeValueAsBytes(article);
esClient.prepareIndex("bigdata","article","13")
.setSource(bytes, XContentType.JSON)
.get();
XContentBuilder方式
XContentBuilder xContentBuilder = XContentFactory.contentBuilder(XContentType.JSON)
.startObject()
.field("id",14)
.field("title","娃哈哈奶茶")
.field("content","好喝大生意的撒互动萨迪")
.endObject();
esClient.prepareIndex("index_hello","article","14").setSource(xContentBuilder).get();
11.3 文档更新和删除
Map<String,Object> data = Maps.newHashMap();
data.put("id",7);
data.put("title","武松打老鼠11");
data.put("content","大数达不到大his到死后的撒11");
esClient.prepareUpdate("index_hello", "article", "7").setDoc(data).get();
esClient.prepareDelete("index_hello", "article", "lAQHg3EBk3Y9erc5mCiK").get();
11.4 批量操作数据
String content = "尴尬大31231";
String title = "范德萨发放到大";
BulkRequestBuilder builder = esClient.prepareBulk();
for (int i = 1;i< 20;i++){
IndexRequestBuilder indexRequestBuilder = esClient.prepareIndex("index_hello", "article", String.valueOf(i)).setSource(JSON.toJSONString(new Article(i, title + i, content + i)), XContentType.JSON);
builder.add(indexRequestBuilder);
}
DeleteRequestBuilder deleteRequestBuilder = esClient.prepareDelete("index_hello", "article", "kwQDg3EBk3Y9erc5HigK");
builder.add(deleteRequestBuilder);
builder.get();
11.5 文档查询
根据ID查询
GetResponse response = esClient.prepareGet("index_hello", "article", "7").get();
Map<String, Object> data = response.getSource();
System.out.println(data);
查询总记录
long hits = esClient.prepareSearch()
.setIndices("index_hello")
.setTypes("article")
.execute()
.actionGet()
.getHits()
.getTotalHits();
System.out.println("总记录数:"+hits);
分页查询排序
SearchResponse response = esClient.prepareSearch()
.setIndices("index_hello")
.setTypes("article")
.setFrom(0)
.setSize(2)
.setQuery(QueryBuilders.fuzzyQuery("title", "解决"))
.addSort(SortBuilders.fieldSort("id").order(SortOrder.DESC))
.get();
SearchHit[] searchHits = response.getHits().getHits();
for (SearchHit searchHit : searchHits) {
System.out.println(searchHit.getSourceAsMap());
}
过滤查询
SearchResponse response = esClient.prepareSearch()
.setIndices("index_hello")
.setTypes("article")
.setPostFilter(QueryBuilders.rangeQuery("id").gte(11))
.setPostFilter(QueryBuilders.rangeQuery("id").lte(19))
.get();
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsMap());
}
高亮显示
SearchResponse response = esClient.prepareSearch()
.setIndices("index_hello")
.setTypes("article")
.setQuery(QueryBuilders.wildcardQuery("title","哈*"))
.highlighter(new HighlightBuilder().field("title").preTags("<font style='color:red;size:20px;'>").postTags("</font>"))
.get();
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
Map<String, HighlightField> fields = hit.getHighlightFields();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
fields.forEach((key,value) -> sourceAsMap.put(key,value.getFragments()[0].toString()));
System.out.println(sourceAsMap);
}
全文检索
聚合查询
SearchResponse response = esClient.prepareSearch()
.setIndices("index_hello")
.setTypes("article")
.setQuery(QueryBuilders.rangeQuery("id").from(1).to(10))
.addAggregation(AggregationBuilders.min("minId").field("id"))
.addAggregation(AggregationBuilders.max("maxId").field("id"))
.addAggregation(AggregationBuilders.avg("avgId").field("id"))
.addAggregation(AggregationBuilders.count("count").field("id"))
.get();
Aggregations aggregations = response.getAggregations();
Min minId = aggregations.get("minId");
Max maxId = aggregations.get("maxId");
Avg avgId = aggregations.get("avgId");
ValueCount count = aggregations.get("count");
System.out.println("最小值:"+minId.getValue());
System.out.println("最大值:"+maxId.getValue());
System.out.println("平均值:"+avgId.getValue());
System.out.println("总条数:"+count.getValue());
SearchType
四种,另外两种已经摒弃
SearchType.QUERY_THEN_FETCH;//默认的搜索方式
SearchType.DFS_QUERY_THEN_FETCH;//可以更精确控制搜索打分和排名
文档查询各种QueryBuilders说明
| 查询类 | 作用说明 |
|---|---|
| 精确查询系列 | |
| QueryBuilders.idsQuery(id.toString()); | 根据ID查找 |
| QueryBuilders.termQuery(“title”,title); | 根据字段含有的词精确查找 |
| QueryBuilders.termsQuery(“title”,title+1,title+2); | 根据字段批量精确查找 |
| QueryBuilders.matchQuery(“id”,id); | 匹配单个字段 |
| QueryBuilders.matchAllQuery(); | 匹配所有 |
| QueryBuilders.multiMatchQuery(title,“title”,“content”); | 根据ID查找 |
| 范围查询系列 | |
| QueryBuilders.rangeQuery(“id”).from(id).to(id); | 闭区间查询 |
| QueryBuilders.rangeQuery(“id”).from(id,false).to(id,false); | 开区间 |
| QueryBuilders.rangeQuery(“id”).gt(id); | 大于 |
| QueryBuilders.rangeQuery(“id”).gte(id); | 大于等于 |
| QueryBuilders.rangeQuery(“id”).lt(id); | 小于 |
| QueryBuilders.rangeQuery(“id”).lte(id); | 小于等于 |
| 模糊查询系列 | |
| QueryBuilders.wildcardQuery(“title”,title); | 通配符模糊查询,?匹配单个字符,*匹配多个字符,中文只支持关键字 |
| QueryBuilders.prefixQuery(“title”,title); | 前匹配查询,中文只支持关键字 |
| QueryBuilders.regexpQuery(“title”,title); | 正则表达式查询,中文只能支持关键字查询 |
| QueryBuilders.fuzzyQuery(“title”,title); | 模糊查询 不支持数字的模糊,中文只能支持单字模糊 |
| QueryBuilders.matchPhrasePrefixQuery(“title”,title); | 能满足大部分情况下的中文模糊匹配 |
| QueryBuilders.matchPhraseQuery(“title”,title); | 能满足大部分情况下的中文模糊匹配 |
| QueryBuilders.moreLikeThisQuery(new String[]{“title”,“content”},new String[]{title,content},null); | 多个字段模糊匹配 |
| QueryBuilders.queryStringQuery(“哈哈”); | 分词后逐个匹配多个字段查询 |
| 空查询系列 | |
| QueryBuilders.existsQuery(“title”); | 非空查询 |
| 复合查询系列 QueryBuilders.boolQuery(); | |
| boolQueryBuilder.must(QueryBuilders.termQuery(“title”,title)); | 与 |
| boolQueryBuilder.should(QueryBuilders.termQuery(“content”,content)) | 或 |
| boolQueryBuilder.mustNot(QueryBuilders.existsQuery(“title”)); | 非 |
所有query
//精确查询系列
QueryBuilders.idsQuery(id.toString());//根据ID查找
QueryBuilders.termQuery("title",title);//根据字段单个精确查找
QueryBuilders.termsQuery("title",title+1,title+2);//根据字段批量精确查找
QueryBuilders.matchQuery("id",id);//匹配单个字段
QueryBuilders.matchAllQuery();//匹配所有
QueryBuilders.multiMatchQuery(title,"title","content");//多个字段匹配某值
//范围查询系列
QueryBuilders.rangeQuery("id").from(id).to(id);//闭区间查询
QueryBuilders.rangeQuery("id").from(id,false).to(id,false);//开区间
QueryBuilders.rangeQuery("id").gt(id);//大于
QueryBuilders.rangeQuery("id").gte(id);//大于等于
QueryBuilders.rangeQuery("id").lt(id);//小于
QueryBuilders.rangeQuery("id").lte(id);//小于等于
//模糊查询系列
QueryBuilders.wildcardQuery("title",title);//通配符模糊查询,?匹配单个字符,*匹配多个字符,中文只支持关键字
QueryBuilders.prefixQuery("title",title);//前匹配查询,中文只支持关键字
QueryBuilders.regexpQuery("title",title);//正则表达式查询,中文只能支持关键字查询
QueryBuilders.fuzzyQuery("title",title);//模糊查询 不支持数字的模糊,中文只能支持单字模糊
QueryBuilders.matchPhrasePrefixQuery("title",title);//能满足大部分情况下的中文模糊匹配
QueryBuilders.matchPhraseQuery("title",title);//能满足大部分情况下的中文模糊匹配
QueryBuilders.moreLikeThisQuery(new String[]{"title","content"},new String[]{title,content},null);//多个字段模糊匹配
QueryBuilders.queryStringQuery("嘿嘿");//分词后逐个匹配多个字段查询
//空查询系列
QueryBuilders.existsQuery("title");//非空查询
//复合查询系列
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.termQuery("title",title));//与
boolQueryBuilder.should(QueryBuilders.termQuery("content",content));//或
boolQueryBuilder.mustNot(QueryBuilders.existsQuery("title"));//非
QueryBuilders.constantScoreQuery();
QueryBuilders.functionScoreQuery();
QueryBuilders.geoBoundingBoxQuery();
QueryBuilders.geoDisjointQuery();
QueryBuilders.geoIntersectionQuery();
QueryBuilders.geoPolygonQuery();
QueryBuilders.geoShapeQuery();
QueryBuilders.geoWithinQuery();
QueryBuilders.nestedQuery();
QueryBuilders.scriptQuery();
QueryBuilders.simpleQueryStringQuery();
QueryBuilders.spanContainingQuery();
QueryBuilders.spanFirstQuery() ;
QueryBuilders.spanMultiTermQueryBuilder();
QueryBuilders.spanNearQuery() ;
QueryBuilders.spanNotQuery();
QueryBuilders.spanOrQuery();
QueryBuilders.spanTermQuery();
QueryBuilders.spanWithinQuery();
QueryBuilders.disMaxQuery();
QueryBuilders.typeQuery();
QueryBuilders.termsLookupQuery();
QueryBuilders.wrapperQuery(" { \"query\":{\"match_all\" : {\"boost\" : 1.0}}}");//原生语句查询
11.6 中文分词
下载分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases
安装
解压到plugins新建的ik目录下
12、SpringBoot+ Spring data Elasticsearch集成
引入依赖
<!--springboot集成spring data es-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
添加配置
spring:
data:
elasticsearch:
cluster-nodes: 127.0.0.1:9300
properties:
path:
logs: ./elasticsearch/log #elasticsearch日志存储目录
data: ./elasticsearch/data #elasticsearch数据存储目录
启动类添加扫描
@SpringBootApplication
@EnableElasticsearchRepositories("com.liangjiachu.liangjiachuframework.es.dao")
public class LiangjiachuFrameworkApplication {
public static void main(String[] args) {
SpringApplication.run(LiangjiachuFrameworkApplication.class, args);
}
}
DAO层
public interface ArticleDao extends ElasticsearchRepository<Article,Long> {
List<Article> findByTitle(String title);
Page<Article> findByTitle(String title, Pageable pageable);
List<Article> findByTitleOrContent(String title, String content);
}
实体类
@Document(indexName = "index_hello",type = "article",shards = 5,replicas = 1,refreshInterval = "1s",indexStoreType = "fs")
@Data
@AllArgsConstructor
public class Article {
@Id
@Field(type = FieldType.Auto,index = true,store = true)
private Long id;
@Field(type = FieldType.Auto,store = true,searchAnalyzer = "ik_max_word",analyzer = "ik_smart")
private String title;
@Field(type = FieldType.Auto,store = true,searchAnalyzer = "ik_max_word",analyzer = "ik_smart")
private String content;
}
二、Elasticsearch进阶
kibana操作ES
添加索引和文档数据
POST /arcticle/_doc
{
"id":1,
"title":"中国共产党万岁",
"content":"我志愿加入中国共产党,遵守党的纲领"
}
带ID的添加文档方式
POST /arcticle/_doc/1001
{
"id":1,
"title":"中国共产党万岁",
"content":"我志愿加入中国共产党,遵守党的纲领"
}
全量更新文档
PUT /arcticle/_doc/1001
{
"id":1,
"title":"中国共产党万岁1",
"content":"我志愿加入中国共产党,遵守党的纲领"
}
局部更新文档
查询
查询所有(默认10条分页)
GET /arcticle/_search
指定分页数查询
GET /arcticle/_search
{
"query": {
"match_all": {}
},
"size": 20,
"from": 0
}
条件查询
GET /arcticle/_search?q=id:2
{
"query": {
"match_all": {}
},
"size": 2,
"from": 0
}
ES分词后如何模糊查询
记录一下ES分词以后当前那个字段是没有办法用来进行模糊查询的,但是当我们加入es的字段类型为text的时候,es会自动帮我们创建一个为keyword的字段
创建数据:
http://localhost:9200/forum/article/_bulk
{ "index": { "_id": 1 }}
{ "articleID" : "XHDK-A-1293-#fJ3", "userID" : 1, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 2 }}
{ "articleID" : "KDKE-B-9947-#kL5", "userID" : 1, "hidden": false, "postDate": "2017-01-02" }
{ "index": { "_id": 3 }}
{ "articleID" : "JODL-X-1937-#pV7", "userID" : 2, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 4 }}
{ "articleID" : "QQPX-R-3956-#aD8", "userID" : 2, "hidden": true, "postDate": "2017-01-02" }
按分词字段进行模糊查询:
http://localhost:9200/forum/article/_search
{
"query":{
"bool":{
"must":{
"wildcard":{
"articleID":"*JODL*"
}
}
}
}
}
按照keyword进行查询:
http://localhost:9200/forum/article/_search
{
"query":{
"bool":{
"must":{
"wildcard":{
"articleID.keyword":"*JODL*"
}
}
}
}
}














 5997
5997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









