







python提取图片数据写入excel,并打包为exe可执行文件
1. 以下面的图片为例
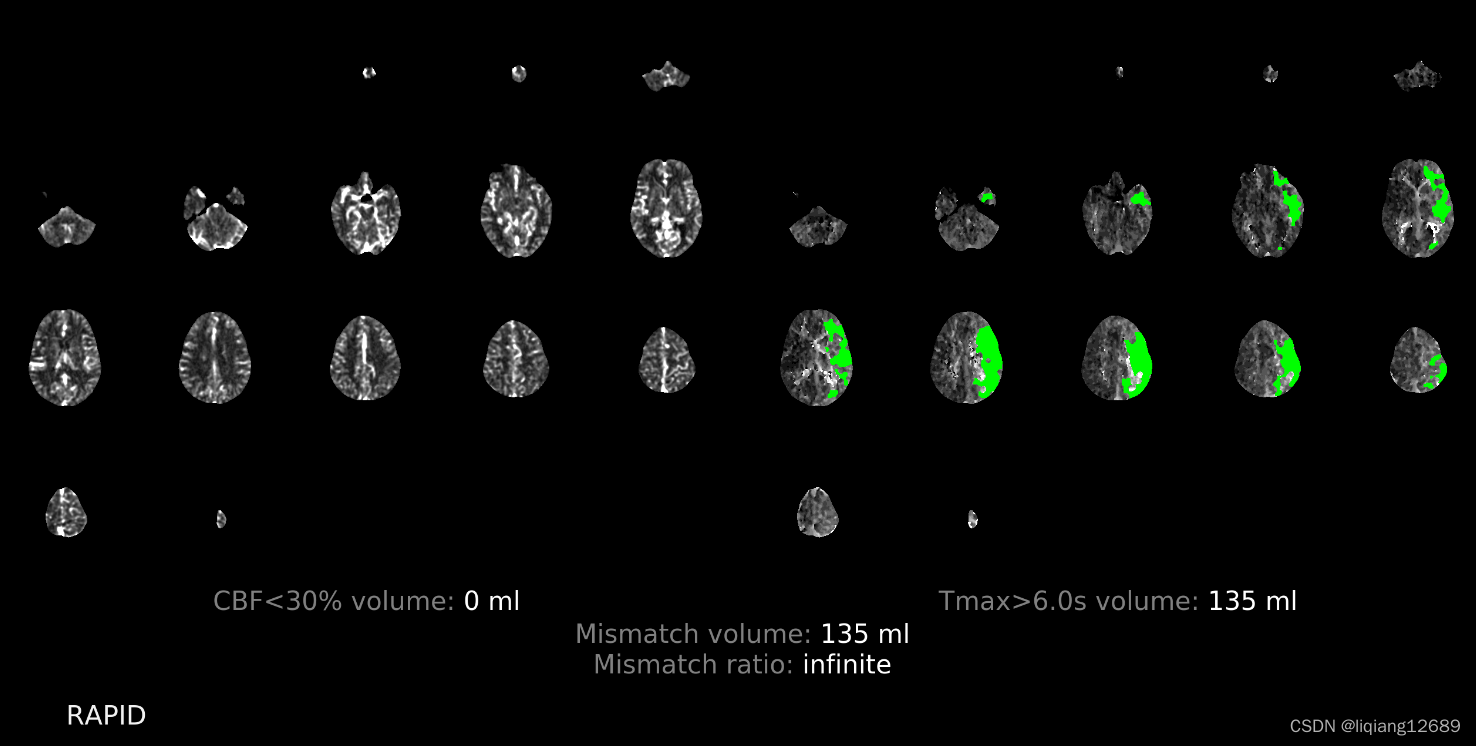
2. python环境需要的依赖包
import os
import re
import pytesseract
from tkinter import Tk, filedialog
from PIL import Image, ImageOps
import pandas as pd
3. 创建交互式窗口
# 创建Tkinter窗口
root = Tk()
root.withdraw() # 隐藏主窗口
# 弹出选择文件夹对话框
folder_path = filedialog.askdirectory(title='选择图片文件夹')
4. 读取文件夹下的所有文件并提取数据
# 弹出选择文件夹对话框
folder_path = filedialog.askdirectory(title='选择图片文件夹')
# 配置Tesseract路径,如果已配置环境变量则可以省略这步
pytesseract.pytesseract.tesseract_cmd = r'D:\toolsoft\tesseractocr\tesseract.exe'
# 创建一个字典来存储数据
data = {
'file name': [],
'CBF<30% volume': [],
'Tmax>6.0s volume': [],
'Mismatch volume': [],
'Mismatch ratio': []
}
# 如果用户取消选择,返回空路径
if not folder_path:
print('未选择文件夹。')
else:
print(f'选择的文件夹路径为:{folder_path}')
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
if os.path.isfile(file_path):
# 检查文件是否为图片文件(可以根据实际需求扩展这个条件)
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
# 打开图片
try:
image = Image.open(file_path)
# 处理图片,例如显示、保存或进行其他操作
data = from_fig_get_txt(data, image)
data['file name'].append(f"{filename}")
# 例如,显示图片
# image.show()
# 或者进行其他处理,如图像处理、识别等
# 这里可以添加你的其他代码逻辑
except OSError:
print(f'无法打开文件:{file_path}')
# 使用pandas将数据写入Excel
df = pd.DataFrame(data)
df.to_excel('output.xlsx', index=False)
print('提取完成并已写入output.xlsx文件。')
5. 提取图片中字段的代码
def from_fig_get_txt(data, image):
# 将彩色图像转换为灰度图像
gray_image = ImageOps.grayscale(image)
# 使用pytesseract提取图片中的文字
text = pytesseract.image_to_string(gray_image, lang='eng') # chi_sim使用简体中文,'eng'用于英文
# 将提取的文字按要求分割或处理
lines = text.split('\n')
for i, line in enumerate(lines):
if 'CBF<30% volume' in line.strip(): # 跳过空行
# 使用正则表达式进行匹配
# 匹配CBF后面的数据
cbf_match = re.search(r'CBF<(\d+%) volume:\s*(\S+)\s*ml', line)
if cbf_match:
# cbf_percent = cbf_match.group(1) # 提取CBF的百分比
cbf_volume = cbf_match.group(2) # 提取CBF的体积
# print(f"CBF百分比: {cbf_percent}, CBF体积: {cbf_volume} ml")
data['CBF<30% volume'].append(f"{cbf_volume} ml")
if 'Tmax>6.0s volume' in line.strip(): # 跳过空行
# 匹配Tmax后面的数据
tmax_match = re.search(r'Tmax>([\d.]+)s.*?volume:\s*([\d.]+)\s*ml', line)
if tmax_match:
# tmax_value = tmax_match.group(1) # 提取Tmax的数值
tmax_volume = tmax_match.group(2) # 提取Tmax的体积
# print(f"Tmax数值: {tmax_value} s, Tmax体积: {tmax_volume} ml")
data['Tmax>6.0s volume'].append(f"{tmax_volume} ml")
if 'Mismatch volume' in line.strip(): # 跳过空行
# 匹配Mismatch后面的数据
Mis_match = re.search(r':\s*(.*)$', line)
Mis_volume = Mis_match.group(1) # 提取Tmax的体积
# print(f"Tmax数值: {tmax_value} s, Tmax体积: {tmax_volume} ml")
data['Mismatch volume'].append(f"{Mis_volume}")
if 'Mismatch ratio' in line.strip(): # 跳过空行
# 匹配Mismatch后面的数据
Mis_ratio = re.search(r':\s*(.*)$', line)
Mis_ratio = Mis_ratio.group(1) # 提取Tmax的体积
# print(f"Tmax数值: {tmax_value} s, Tmax体积: {tmax_volume} ml")
data['Mismatch ratio'].append(f"{Mis_ratio}")
return data
6. 打包代码为exe可执行文件
安装打包依赖文件
pip install pyinstaller
运行打包代码
pyinstaller --onefile yourpyfile.py
生成的 EXE 文件将在 dist 文件夹中















 6840
6840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









