







1. RocksDB 简介
- RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的数据库软件,旨在充分实现快存上存储数据的服务能力。
- RocksDB是一个c++库,可以用来存储keys和values,且keys和values可以是任意的字节流,支持原子的读和写;
- RocksDB是一个基于LSM-Tree 存储引擎实现的数据库架构,LSM 通过 将磁盘的随机写转化为顺序写来提高写性能,而付出的代价就是牺牲部分读性能 、 写放大;
- RocksDB 所有的数据在引擎中是有序存储,可以支持Get(key)、Put(Key)、Delete(Key)和NewIterator()。
- RocksDB的基本组成是memtable、sstfile和logfile。
2. RocksDB 数据格式
2.1 RocksDB表记录的存储格式
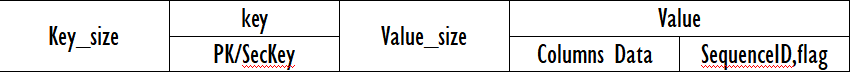
以上面的例子为基础,我们来逐一分解其数据的存储格式。
首先,Key 是一个行的唯一标识“rowid”,由于表没有主键, 系统会产生一个 bigint 类型的 rowid 作为主键, 占用 8 个字节。
然后,Value 的最前面部分就是存放记录的 null 信息根据记录中可以为空字段的个数, 确认需要占用的字节数, 如果小于 8 个, 则只需要一个字节。例子中, c1,c3,c4,c6 均可以为空, 因此需要 4 个 bit, 所以用 1 个 byte 表示 Null-flag 即可。对于null, 无论是定长还是非定长数据类型, 都不占用真实的存储空间, 只需要一个 bit 位来表示为 null 即可;对于定长字段, 则会补全;
对于变长字段, 如果数据长度小于 256,len 只需要占用一个 byte; 如果 len 大于 255, 且小于 65536, 则需要占用 2 个字节, 对于 longblob 类型, 则需要占 4 个字节;
最后,meta 主要是 SequenceID, 这个 SequenceID 在事务提交时产生, 主要用于 RocksDB 实现并发事务控制。
2.2 RocksDB索引的存储格式
RocksDB 中, 所有的数据都是通过索引来组织, 每个索引有一个全局唯一的索引标识“index_id” 。
索引主要包括两类: 主键索引和二级索引, 他们的数据结构一样, 都包括 key, value, meta 三部分。但是 value 中不包含任何数据, 只是包含 checksum(检查数据文件的校验位) 信息。具体格式如下所示:
表2.2.1 主健索引

表2.2.2 二级索引

对于索引长度限制也有所不同, 对于 InnoDB 引擎来说, 索引中单列长度不能超过 767 个字节, 而 RocksDB 引擎单列长度不超过 2048 个字节。因为id字段是主键索引,当查询条件是 where id = XX 或者where id in ( XX,XX,XX )的时候,可以根据Rocksdb的get或者mget接口,高效的获取某一条和某几条数据。当查询条件是 where id > XX and id < XX 这样的range查询的时候,我们可以创建一个迭代器。这个操作需要一个seek随机读和一个scan顺序读操作,也有很高的读取性能。
3. RocksDB 整体架构及读写分析
3 .1 RocksDB 基础架构组成
RocksDB的基本组成是 WAL、 memtable、sstfile 。
- WAL 是一个顺序写的文件。写请求会先将数据写到 WAL。
- memtable是一种内存数据结构,当WAL写入之后,数据会写到memtable中。
- sstfile是持久化数据文件,内存表中数据溢出或定期写入sstfile。
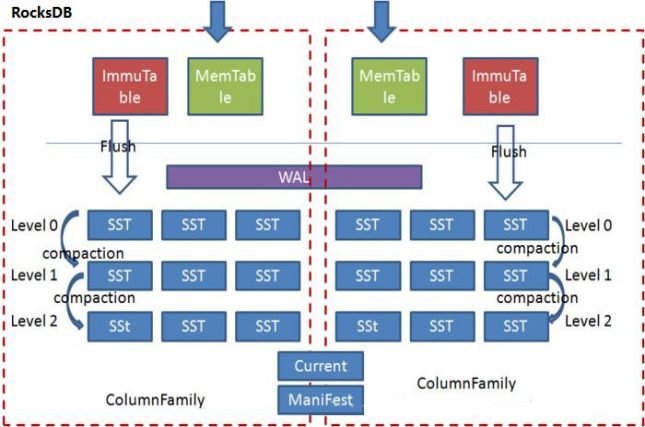
如图3.1所示Rocksdb的基础架构。Rocksdb中引入了ColumnFamily(列族, CF)的概念,所谓列族也就是一系列kv组成的数据集,所有的读写操作都需要先指定列族。写操作先写WAL,再写memtable,memtable达到一定阈值后切换为Immutable Memtable,只能读不能写。后台Flush线程负责按照时间顺序将Immutable Memtable刷盘,生成level0层的有序文件(SST)。后台合并线程负责将上层的SST合并生成下层的SST。Manifest负责记录系统某个时刻SST文件的视图,Current文件记录当前最新的Manifest文件名。每个ColumnFamily有自己的Memtable, SST文件,所有ColumnFamily共享WAL、Current、Manifest文件。
图3.1 RocksDB 基础架构图
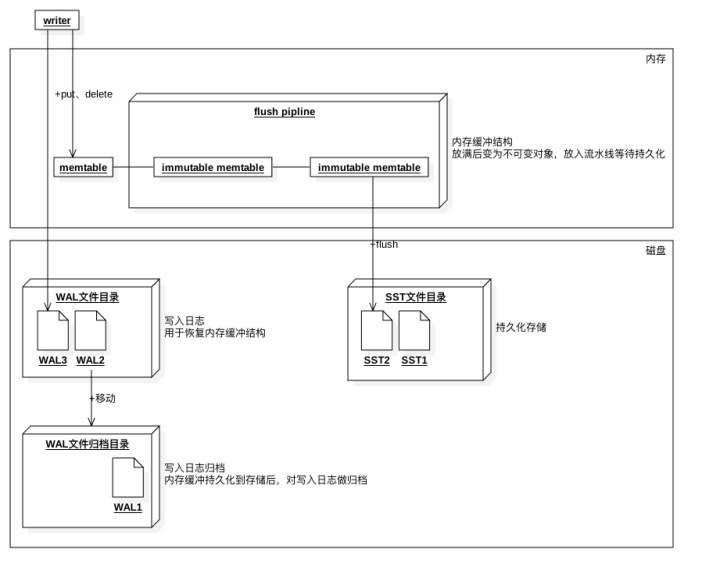
3.2 RocksDB 数据写入分析
图 3.2.1 RocksDB 写入流程图
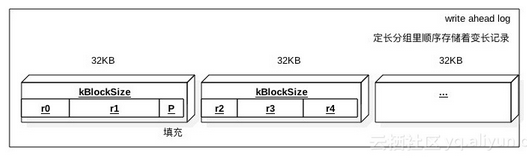
WAL文件结构如下图,按照写入的顺序来存储变长的K-V,按照固定长度来分组存储(可能一个K-V跨多个分组)的目的是便于读取
支持几种SST文件结构
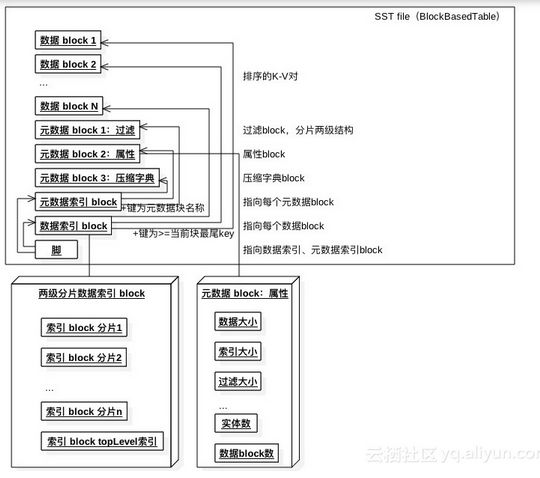
上图为按照多块来存储的结构。每块的K-V都是有序的,而多块也是有序的。文件中包含元数据相关的信息,包括数据压缩字典、过滤器等。会按照数据块所属的K-V范围来创建索引,为提升查询性能会给索引分片。
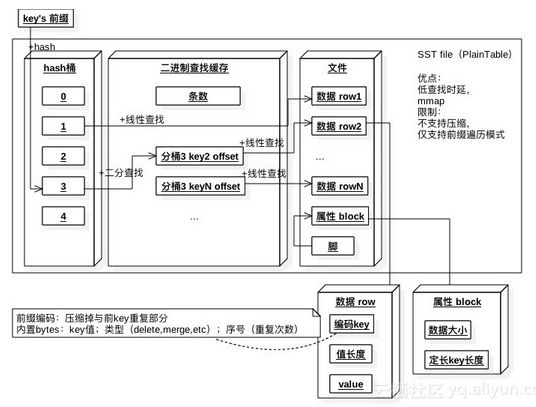
另外一种结构是每个K-V来存储。它的索引比较特殊,由hash结构和二进制查找缓存两部分组成。依然按照key的前缀做hash,如果桶对应的K-V记录很少,则直接指向第一个key(有多个key属于该桶)的记录位置。如果属于桶的K-V记录多于16条,或者包含多于一个前缀的记录,则先指向二进制查找缓存(先二分查找),而后指向第一个key的记录位置。
随着K-V的写入,会生成很多的SST文件。这部分文件需要被合并到一起,从而降低打开文件数量,并且移除已经不存在的记录。
如图所示,任何的写入都会先写到 WAL,然后在写入 Memory Table(Memtable)。当然为了性能,也可以不写入 WAL,但这样就可能面临崩溃丢失数据的风险。Memory Table 通常是一个能支持并发写入的 skiplist,但 RocksDB 同样也支持多种不同的 skiplist,用户可以根据实际的业务场景进行选择。当一个 Memtable 写满了之后,就会变成 immutable 的 Memtable,RocksDB 在后台会通过一个 flush 线程将这个 Memtable flush 到磁盘,生成一个 Sorted String Table(SST) 文件,放在 Level 0 层。当 Level 0 层的 SST 文件个数超过阈值之后,就会通过 Compaction 策略将其放到 Level 1 层,以此类推。
图 3.2.2 RocksDB Compaction
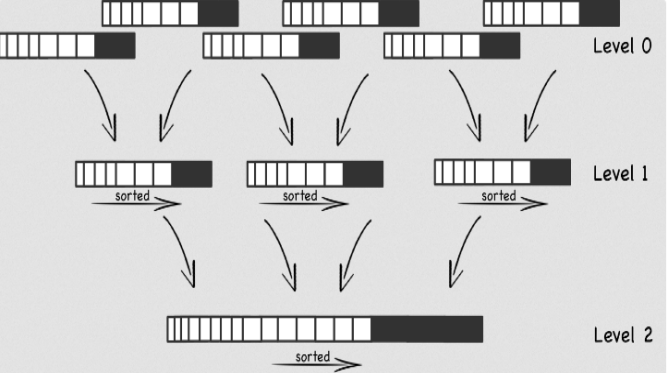
关于Compaction,如图所示,处于L0的SST文件是无需的,重叠的。而经过 Compaction 处理之后的 L1、L2 ….LN 层的SST文件是被有序并且逐步合并为大文件的过程。
如果没有 Compaction,那么写入是非常快的,但会造成读性能降低,同样也会造成很严重的空间放大问题。为了平衡写入,读取,空间这些问题,RocksDB 会在后台执行 Compaction,将不同 Level 的 SST 进行合并。但 Compaction 并不是没有开销的,它也会占用 I/O,所以势必会影响外面的写入和读取操作。对于 RocksDB 来说,他有三种 Compaction 策略,一种就是默认的 Leveled Compaction,另一种就是 Universal Compaction,还有一种就是 FIFO Compaction。
接下来,我们来针对RocksDB写的特点进行性能的定性分析:
( 1 ) . 所有的刷盘操作都采用append方式,这种方式对磁盘和SSD是相当有诱惑力的;
( 2 ) . 写操作写完WAL和Memtable就立即返回,写效率非常高。
( 3 ) . 由于最终的数据是存储在离散的SST中,SST文件的大小可以根据kv的大小自由配置。
简而言之,在RocksDB中的读取需要处理的最核心的一个问题就是如何读取最新的数据,这是由于RocksDB是基于LSM,因此在RocksDB中,对于数据的delete以及update,它并不会立即去执行对应的动作,而只是插入一条新的数据,而数据的最终更新(last-write-win)以及删除是在compact的时候来做的.
3.3 RocksDB 数据读出分析
如图所示,相对于写流程,读取的流程还是相对而言比较简单的,结合读取流程图,我们这里简单的梳理一下读取经过哪几个步骤,看看RocksDB的数据读取是怎么样进行处理的。
图 3.3.1 RocksDB 读取流程图
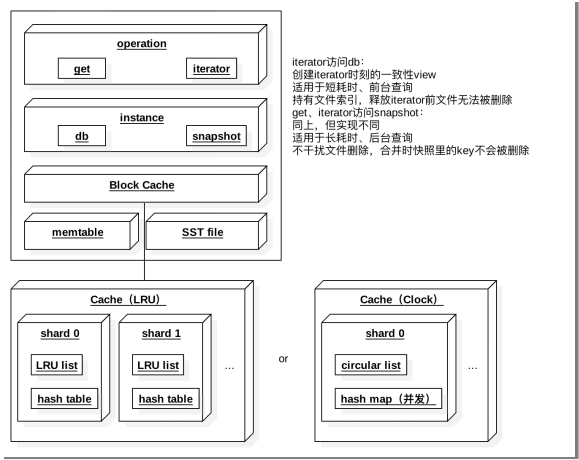
首先,获取当前时刻的SuperVersion。SuperVersion是RocksDB内针对于所有SST文件列表以及内存中的Memtable和Immutable memtable的一个版本。
接着,获取当前的序号来决定当前读操作依赖的数据快照。
然后,尝试从第一步SuperVersion中引用的Memtable以及Immutable memtable中获取对应的值。
再次,尝试从Block cache中读取
最后,尝试从sst文件中获取。
整个流程其实是比较清晰的,主要是涉及到Memtable的查找,以及SST内数据的查找。对于Memtable内部的查找,相对而言还是有很多细节的,篇幅原因不做展开。我们主要针对SST文件的查找来做进一步展开分析:
在Level0(L0)中的数据文件是可能会有数据重叠部分的,所以在L0中查找一个key,我们需要依次查找所有的SST文件;而对于非L0层级,每个文件都是按顺序存放的。首先我们需要遍历搜索Level 0(L0)层所有的文件,假设没有找到则继续。到了L1层,该层数据文件是有序的,每一个文件都会有一个FileMetaData保存着该文件的最小key和最大key,同时还有IndexUnit(记录关键KEY值的数据结构)。对L1层文件进行二分查找来找到第一个largest key大于要查找key的文件。我们继续对此SST文件内的key进行查找,假如没有找到,则继续。理论上到L1层我们可以再次进行二分查找来找到对应的key,但是借助IndexUnit我们可以快速过滤不需要查找的文件,提升查找速度。
4 RocksDB的适用场景分析
4.1 RocksDB 的特性分析
RocksDB 虽然在代码层面上是在LevelDB原有的代码上进行开发的,但却借鉴了Apache HBase的一些好的思想。LevelDB则是一个比较单一的存储引擎,也是因为LevelDB的单一性,在做具体的应用的时候一般需要对其作进一步扩展。相对于LevelDB而言,RocksDB在很多地方做了改进:
(1). RocksDB支持一次获取多个K-V,还支持Key范围查找。
(2) . RocksDB 除了简单的Put、Delete操作,还提供了一个Merge操作,为了对多个Put操作进行合并(站在引擎实现者的角度来看,相比其带来的价值,其实现的成本要昂贵很多)。
(3). RocksDB 支持多线程合并。LSM型的数据结构,最大的性能问题就出现在其合并的时间损耗上,在多CPU的环境下,多线程合并那是 LevelDB所无法比拟的。
(4). RocksDB增加了合并时过滤器,对一些不再符合条件的K-V进行丢弃。
(5) . RocksDB可采用多种压缩算法,除了LevelDB用的snappy,还有zlib、bzip2。LevelDB里面按数据的压缩率(压缩后低于75%)判断是否对数据进行压缩存储,而RocksDB典型的做法是Level 0-2不压缩,最后一层使用zlib,而其它各层采用snappy。
(6) . RocksDB 支持管道式的Memtable,也就说允许根据需要开辟多个Memtable,以解决写入与压缩速度差异的性能瓶颈问题。















 3153
3153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









