







本文是实验设计与分析(第6版,Montgomery著傅珏生译)第4章随机化区组,拉丁方,以及有关的设计第4.1节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您可以从Detail 下载实验设计与分析(第6版,Montgomery著傅珏生译)电子版。本文假定您已具备python基础,如果您还没有python的基础,可以从Detail 下载相关资料进行学习。
在很多实验中,由讨厌因子产生的变异性可能会影响结果。一般地,我们定义讨厌因子(nuisance factor)为一个可能对响应产生影响的设计因子。但是,我们对这个效应并不感兴趣。有时,讨厌因子是未知的且不可控制的。也就是说,我们并不知道因子的存在,但在进行实验时,它甚至可能正在改变着因子水平。随机化是一种常用于抵制这种“潜伏”的讨厌因子的设计技术,
在其他情形中,讨厌因子虽然是已知的但却是不可控的。如果我们至少可以观测到讨厌因子影响了实验的每一轮中的值,那么就可以用协方差分析(将在第14章中讨论)作为它在统计分析中的补充,当讨厌来源的变异性是已知的且可控的,我们可以用所谓的区组化没计技术来系统地消除它在处理间统计比较中的效应。区组化是一种十分重要的设计技术,广泛应用于工业实验,它也
是本章的主要内容。
为了说明这种基本思想,再考虑前面2.5.1节中讨论过的硬度检验试验。假定我们想确定4只不同的压头在一台硬度试验机上是否得出不同的读数。像这样的实验可能是测量仪能力研究的一部分。机器将压头压入一块金属试件中去,由压入的深度可确定试件的硬度。实验者决定用洛氏硬度试验法对每只压头取4个观测值。因为仅有一个因子--压头类型,所以,一个完全随机化的单因子设计就由4×4=16次试验组成,这16次试验中的每一次试验都被随机安
排到一个实险单元(即,一块金属试件),然后观测所得的硬度读数。这样一来,在这个实验中就需要16块不同的金属试件,每块作一次试验。
在这种设计情况下,完全随机化实验存在一个潜在的严重问题。如果金属试件取自不同炉次的铸锭,可能造成它们的硬度略有不同,那么,实验单元(试件)就会对硬度数据观测值的变异性产生影响。于是,实验误差就不仅反映出随机误差,还反映出试件间的变异性。
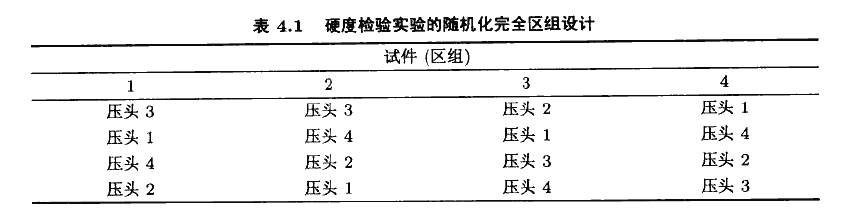
我们当然希望实验误差尽可能的小。也就是说,我们希望从实验误差中消除试件间的变异性。为了做到这一点,实验者在4块试件的每一块上对每只压头检验一次。这种设计(如表4.1所示)叫做随机化完全区组设(RCBD)。“完全”一词指的是每一区组(试件)包含了所有的处理(压头),使用这种设计方法,区组或试件形成了一个较齐性的实验单元,在这些实验单元上比
较压头的硬度,从效果上说,这种设计方案因为消除了试件间的变异性从而提高了压头间进行比较的精度。在一个区组内,4只压头被检验的顺序是随机确定的.这一设计问题和2.5.1节中曾讨论过的配对t检验法所提的问题有一定的相似性。随机化完全区组设计是那个概念的推广。
RCBD是得到最广泛应用的实验设计之一。适用RCBD的情况很多。试验仪器或机器的单元间在其运行特性上常常也会有所不同,这是一类典型的区组化因子。原材料的批次、人以及时间,也都是实验变异性的常见干扰源,它们也是可以通过区组化而被系统控制的。
区组化对于不一定包含讨厌因子的情形也是有用的。例如,假定化学工程师想要研究催化剂进料率对聚合体黏性的影响。她知道有许多因子(例如原材料来源、温度、操作者以及原材料的纯度)在整个过程中非常难以控制。因此她决定用区组化的方法检验催化剂进料率因子,这些不可控因子的某种组合构成一个区组,事实上,她用这些区组检验过程变量(进料率)相应于不易
控制的条件的稳键性(robustness)。关于这-一点的讨论,详见Coleman and Montgomery(1993)。
4.1.1 RCBD的统计分析
一般地,假设我们有ā个待比较的处理和b个区组。随机化完全区组设计如图4.1所示。在每个区组内,每个处理都有一个观测值,且进行试验时各种处理的次序是随机确定的。因为只有在区组内,处理才有随机性,所以我们常说区组表示了关于随机性的一种约束。
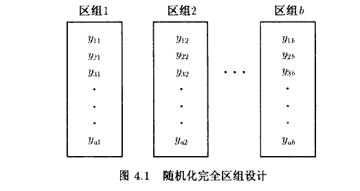
如表4.2所示的方差分析表通常可以用一个统计软件包进行计算。

这些量可以在工作表(如Excel)的列中进行计算。对每列进行平方再求和得到平方和。另外,计算公式可以用处理和与区组和来表示,这些计算公式是
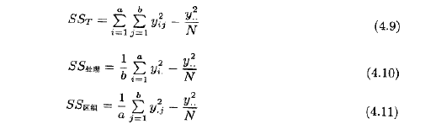
而误差平方和由减法得出为
![]()
例4.1某医疗器械工厂生产供移植用的人造血管。通过将聚四氟乙烯(PTFE)树脂块借助于洞滑剂挤压成管子制造人造血管。生产流程中一些管子的外表面经常会出现小的、硬的突出物。这些缺陷通常称为“疵点”,这些缺陷导致产品不合格。
人造血管的产品开发者怀疑挤压压强导致了疵点的产生,从而想到一个实验来验证这个假设。然面,生产用的树脂由外来供应商按批次送到医疗器城工厂。工程师也怀凝各批次之间有显著性差异,因为尽管材料的有关参数(比如,分子量、平均微粒尺寸,保特力、峰高比等参数)应该是一致的,但材料可能并不因为树脂供应商的生产过程变化以及材料的自然变化而变化。因此,产品开发者决定考虑将树脂的批次作为区组,运用完全随机化区组设计,研究4个不同水平的挤压压强对疵点的效应。该RCBD如表4.3所示,有4个水平的挤压压强(处理),6个批次的树脂(区组),注意到在每个区组内的挤压压强的试验次序是随机的,响应变量是产率,即没有疵点的成品的百分比。
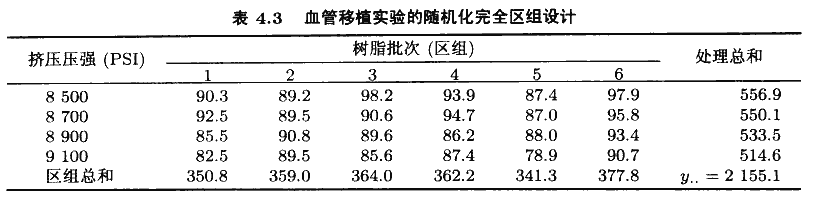
为进行方差分析,先计算下面的平方和:
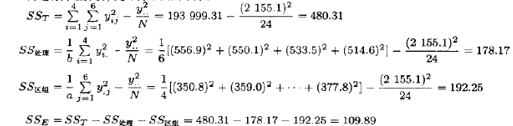
方差分析见表4.4.用a=0.05,F的临界值为F005.3,15=3.29。因为8.11>3.29,我们得出结论:挤压压强影响了产品的均值。检验的P值也很小。同样,树脂批次(区组)似乎也有显著性差异,因为区组的均方相对于识差也很大。

#以下内容保存为4-1.txt
value Block PSI
90.3 1 8500
89.2 2 8500
98.2 3 8500
93.9 4 8500
87.4 5 8500
97.9 6 8500
92.5 1 8700
89.5 2 8700
90.6 3 8700
94.7 4 8700
87.0 5 8700
95.8 6 8700
85.5 1 8900
90.8 2 8900
89.6 3 8900
86.2 4 8900
88.0 5 8900
93.4 6 8900
82.5 1 9100
89.5 2 9100
85.6 3 9100
87.4 4 9100
78.9 5 9100
90.7 6 9100
import pandas as pd
import seaborn as sns
import statsmodels.api as sm
import matplotlib as plt
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
# load data file
d = pd.read_csv("4-1.txt", sep="\t")
model = ols('value ~ C(Block)+ C(PSI)', data=d).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
anova_table
>>> anova_table
sum_sq df F PR(>F)
C(Block) 192.252083 5.0 5.248666 0.005532
C(PSI) 178.171250 3.0 8.107077 0.001916
Residual 109.886250 15.0 NaN NaN
如果我们不知道随机化区组设计,则观那些可能得到的结果是很有趣的。假设这个实验按照完全随机设计来做,并且(碰巧)同样的实险结果如表4.3所示。这些数据作为完全随机单因子设计的不正确的分析如表4.5所示:

因为P值小于0.05,我们仍拒绝原假设,得到挤压压强显著影响平均产率的结论。但是,注意到均方误差成倍增加,从RCBD的7.33增如到15.11。所有的变化是因为将区组放在误差项里。容易理解为什么我们有时称RCBD为降噪设计技术,因为它有效地增加了数据中的信噪比,或者说,它提高了处理均值比较的精度。这个例子也说明了这一点。如果实验者在必须区组化时,没有区组化,那么误差效应被夸大了,很有可能夸大太多,导致处理均值间的重要差异不能被识别出来。
import pandas as pd
import seaborn as sns
import statsmodels.api as sm
import matplotlib as plt
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
# load data file
d = pd.read_csv("4-1.txt", sep="\t")
model = ols('value ~ C(PSI)', data=d).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
anova_table
>>> anova_table
sum_sq df F PR(>F)
C(PSI) 178.171250 3.0 3.931339 0.023448
Residual 302.138333 20.0 NaN NaN
1.计算机输出示例(略)
2.多重比较(略)
4.1.2模型适合性检验
前面讨论过检验假定模型适合性的重要性,一般说来,我们应该警惕那些由正态性假定、处理或区组的不等的误差方差以及区组处理交互作用引起的潜在问题。如同在完全随机化设计中那样,残差分析是用于这类诊断性检验的主要工具。例4。1的随机化区组设计的成差被列在图4.2中的Design-Expert输出的底部。
这些残差的正态概率图如图4.4所示,既没有非正态性的严重标志,也没有任何存在离群值的证据。图4.5画出了拟合值与残差的关系图。残差的大小与拟合值之间没有什么关系。这张图没有显示出令人特别感兴趣的地方,图4.6描绘的是处理(挤压压强)与残差的关系图以及树脂的批次(即区组)与残差的关系图,这些图可能非常有益。如果一特定处理的残差较为分散,则表示这一处理与其余的处理相比,比较容易得出不稳定的响应。较为分散的残差标志着区组不齐性。不过,在我们的例子中,图4.6并未表明处理方差不齐性,但却表明6个批次的产量有较小的不同。然而,如果其他所有的残差图都令人满意,我们就可以忽视这一点。
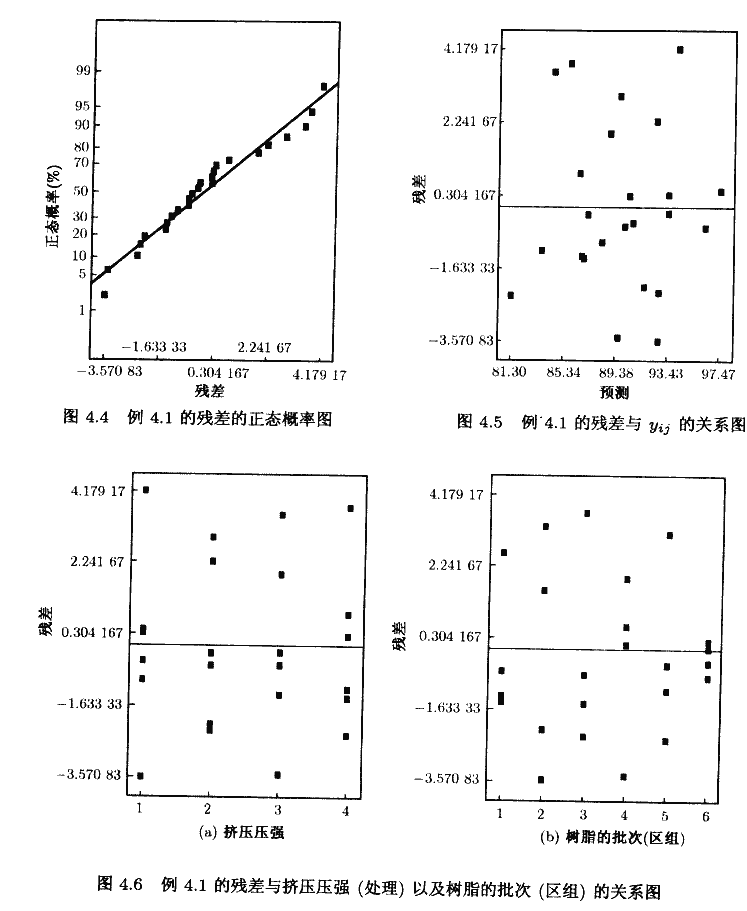
有时,残差与估计值的关系图是一条曲线。例如,对于低的估计值,存在着产生负残差的趋向:对中等的估计值,存在着产生正残差的趋向:对高的估计值,存在着产生负残差的趋向。这类图像暗示着区组与处理间存在着交互作用。如果这类图像出现,就要利用变换来消除或最小化交互作用。第5章(5.3.7节)中给出了一个统计检验法,可以用来检验随机化区组设计中可能存在的交互作用。
#以下内容保存为4-6.txt
value Block PSI
90.3 1 8500
89.2 2 8500
98.2 3 8500
93.9 4 8500
87.4 5 8500
97.9 6 8500
92.5 1 8700
89.5 2 8700
90.6 3 8700
94.7 4 8700
87.0 5 8700
95.8 6 8700
85.5 1 8900
90.8 2 8900
89.6 3 8900
86.2 4 8900
88.0 5 8900
93.4 6 8900
82.5 1 9100
89.5 2 9100
85.6 3 9100
87.4 4 9100
78.9 5 9100
90.7 6 9100
import pandas as pd
import seaborn as sns
import statsmodels.api as sm
import matplotlib as plt
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
# load data file
d = pd.read_csv("4-1.txt", sep="\t")
model = ols('value ~ C(Block)+ C(PSI)', data=d).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
anova_table
>>> anova_table
sum_sq df F PR(>F)
C(Block) 192.252083 5.0 5.248666 0.005532
C(PSI) 178.171250 3.0 8.107077 0.001916
Residual 109.886250 15.0 NaN NaN
d['predicted']=model.predict()
d['residuals']=d.predicted-d.value
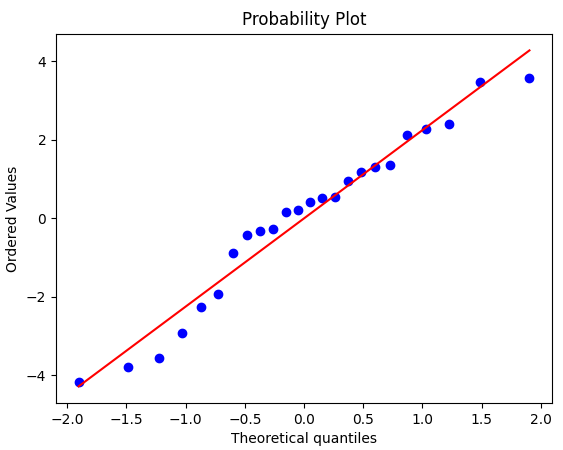
stats.normaltest(d.residuals)
>>> stats.normaltest(d.residuals)
NormaltestResult(statistic=0.9773121113526294, pvalue=0.6134502834560667)
stats.probplot(d.residuals, plot=plt)
plt.show()
4.1.3随机化完全区组设计的一些其它方面
1.随机化区组模型的可加性
2.随机处理与区组
3.样本量的选择
4.缺失值的估计
在用RCBD时,有时,某一个区组的一个观测值缺失。由于不小心或犯错误或失去控制,这种情况是会发生的,例如,一个实验单元出现了不可避免的损伤等。一个缺失的观测值给分析带来了一个新问题,因为处理不再与区组正交了,也就是说,并不是每一个处理都在每一个区组中出现。对于缺失值的问题,有两个一般的近似方法。一个近似分析法是,估计这一缺失观测值,并
把它作为真实数据进行通常的方差分析,只是将误差自由度减小1。这一种近似分析法是本节的主题。另一个是一个精确的分析法,将在4.1.4节中讨论。
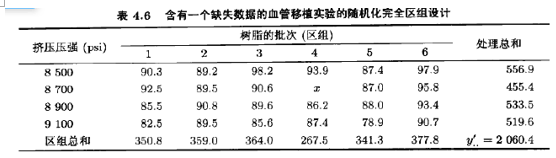
设处理i在区组j中的观测值yij缺失。用x表示这一缺失值。作为一种解释,假定在例4.1的人造血管试验中,当挤压机器用8700psi操作第4批材料时出现问题,并且没有得到该点的数据。就会出现如表4.6那样的数据。
一般地,以y’ij表示yij缺失时其他数据的总和,以y’i.表示有一个缺失值的处理的总和,y’.j表示有一个缺失值时区组的总和。假设我们希望被估计的那个缺失值x对误差平方知有最小的贡献,因为![]() ,这个问题就等价于去选取x,使得
,这个问题就等价于去选取x,使得
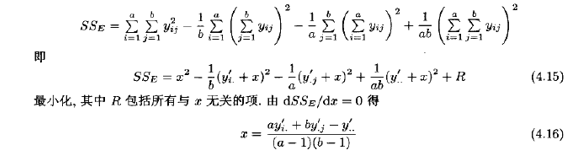
把它作为缺失值的估计值。
对于表4.6中的数据,得y’2.=455.4,y’.4=267.5,y’..=2060.4。因此,由(4.16)式
![]()
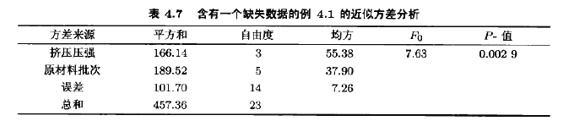
现在,用y24=91.08来进行通常的方差分析,并将误差自由度减少1。方差分析如表4.7所示,请将这一近似分析法与由完全数据组(表4.4)所得的结果比较一下。
如果有几个观测值缺失,则可以把误差平方和写为这些缺失值的函数,对每一缺失值求导数,令其为零,然后解这一方程组,求得缺失值的估计值。也可以由(4.16)式用选代法来估计缺失值。为了解释送代法,设有两个缺失值,任意估计第一个缺失值,然后用这一数据作为真实值并与(4.16)式一起去估计第二个。现在,(4.16)式再用来重新估计第一个缺失值,此后,又可以重新估计第二个,这一过程继续进行下去,直至收敛为止,在任何缺失值问
题中,误差自由度对每一个缺失值都减少1。
#以下内容保存为4-6.txt
value Block PSI
90.3 1 8500
89.2 2 8500
98.2 3 8500
93.9 4 8500
87.4 5 8500
97.9 6 8500
92.5 1 8700
89.5 2 8700
90.6 3 8700
4 8700
87.0 5 8700
95.8 6 8700
85.5 1 8900
90.8 2 8900
89.6 3 8900
86.2 4 8900
88.0 5 8900
93.4 6 8900
82.5 1 9100
89.5 2 9100
85.6 3 9100
87.4 4 9100
78.9 5 9100
90.7 6 9100
import pandas as pd
import seaborn as sns
import statsmodels.api as sm
import matplotlib as plt
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
# load data file
d = pd.read_csv("4-6.txt", sep="\t")
model = ols('value ~ C(Block)+ C(PSI)', data=d).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
anova_table
>>> anova_table
sum_sq df F PR(>F)
C(Block) 189.522000 5.0 5.218117 0.006533
C(PSI) 163.398167 3.0 7.498080 0.003130
Residual 101.696000 14.0 NaN NaN
4.1.4估计模型参数和一般回归显著性检验(略)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











