







损失函数
监督学习问题是在假设的空间F中选取模型 f 作为决策函数,对于给定的输入 X,由 f(x) 给定输出Y, 这个输出的预测值与真实值 Y可能不一致,用一个函数来度量预测错误的程度表示这种不一致,这个函数就是损失函数或者代价函数;
通常的损失函数如下:

损失函数值越小,模型越好;由于模式的输入,输出(X,Y)是随机变量,有联合分布P(X,Y) 所以损失函数的期望是:
上面关于联合概率的平均意义下的损失,也被叫做风险函数;
由于联合概率是未知的,不能从上氏中求出风险函数;而对于给到的训练集
T = {(X,Y),(X2,Y2),.........}
模型 f(x) 关于训练集数据的平均损失称为经验风险:
根据大数定律:当样本容量趋于无穷大的时候,经验风险 趋于 期望风险
经验风险和结构风险最小化
经验最小化求解的最优模型:
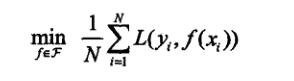
当样本容量足够大的时候,经验风险最小化能保证有很好的学习效果,但样本数量小的时候,就会产生“过拟合”现象。因为参数太多,会导致我们的模型复杂度上升,容易过拟合(训练误差会很小),但训练误差小不是我们的终极目标,我们的目标也是测试误差也小,所以我们要保证模型最简单的基础下最小化训练误差;模型复杂度可以通过正则函数来实现(约束我们的模型特征),强行的让模型稀疏,低秩,平滑等
结构风险最小化是为了防止过拟合提出的策略,结构风险最小化等价于正则化。结构风险的经验在经验风险上加上表示模型复杂度的正则化项或惩罚项;结构风险的定义:
其中 J( f ) 为模型的复杂度
误差
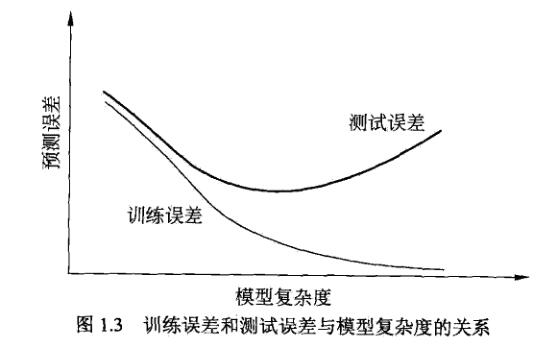
在多项式函数拟合中可以看到,随着多项式的次数(模型复杂度)的增加,训练误差会减少,直到趋于0;而测试误差会先减小,达到最小值后又增大(如下图)当选择的模型复杂度过大时候,过拟合现象(过拟合 就是模型训练的时候误差很小,但在测试的时候误差很大,也就是我们的模型复杂到可以拟合到我们的所有训练样本,但在实际测试新的样本的时候,就不行了;说白了就是应试能力很强,实际应用很差)就会发生;这样学习的时候就要防止过拟合,进行最优化模型选择,选择复杂度适当的模型;下面介绍两种常用模型的选择方法:正则化于交叉验证
正则化与交叉验证
正则化是结构风险最小化策划的实现,是在经验风险上加一个正则化项,或罚项;正则化一般是模型复杂度和单调递增函数,模型越复杂,正则化值就越大;比如正则化项可以是模型参数向量的范数。
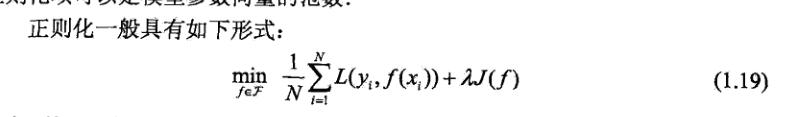

















 5163
5163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









