






一:经验误差和泛化误差
错误率:把分类错误的样本占总体样本总数的比率
精度(accuracy)= 1 -错误率
误差:把学习器的实际预测输出与样本的真实输出的差异叫做误差;学习器在训练数据集上的误差叫做经验误差或训练误差,而在新样本的上的误差叫做泛化误差;对于我们来说,我们一定想使学习器在新样本的误差最少化,极致为0;但我们并不知道新样本;取而代之的只能使我们的学习器经验误差最小;
二:过拟合和欠拟合
过拟合:当学习器把样本学习的太“过”的时候,把一些样本的自身的某些特点当做所有潜在样本的一般性质的时候就会出现过拟合现象,这样就会导致泛化能力弱化;导致过拟合的现象发生一般是学习器过于强大和模型过于复杂引起的;
欠拟合:就是在学习器学习能力低下的条件下,没把样本的一般特性的大部分学会,拟合一般比较好解决,可以适当的加强模型复杂度,增加学习次数等;
三:查准率和查全率
对于两分类情况,我们可以得到样本真实类别和学习器预测的类别的组合,可以划分如下:
TP 表示真实的正例预测为 正例;FN 表示为真实的正例预测为负例;FP表示真实的负例预测为正例;TN表示真实的负例预测为负例;
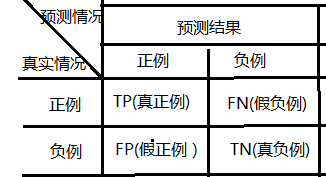
查准率 P = TP/(TP+FP) ---表示预测为正例中真实正例的比率
查全率 R = TP/(TP+FN) ---表示为所有真实正例中有多少被预测为正例的比率
一般来说查准率和查全率是矛盾的;比如有5个西瓜,3个为熟瓜,2个为生瓜;为了找出熟瓜查全率最大化,我可以把5个瓜都选择了;那么熟瓜都被选中了,查全率很大,但查准率比较低; 若我一共只选1个瓜呢,那查全率就会小了,因为一定会有两个熟瓜丢掉的,那查准率会提高;
我们根据查准率和查全率的特性可以画出一条曲线,如下图可以看出随着查全率增大,查准率减小;
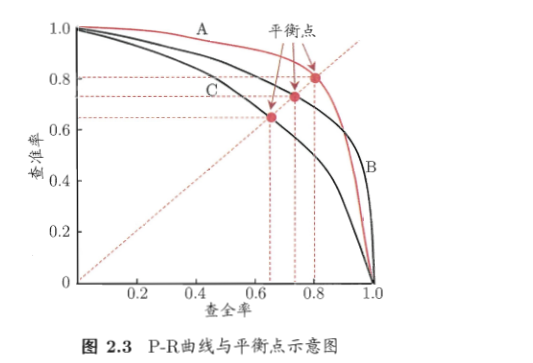
那若多个学习器,怎么根据P-R曲线判断好坏呢?若一个学习器的P-R包住了另一个学习器的P-R曲线的时候,面积大的P-R曲线对应的学习器效果比较好;若要量化的,可以画出一条平衡线使的查全率和查准率相等的时候;比较查全率和查准率的大小;数值大的分类器效果好;
我们在查全率和查准率的基础上又引入一个参考指标;F
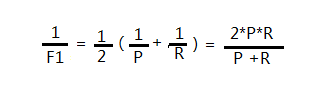
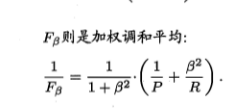

当 B>1的时候,查全率影响大;B<1 的时候,差准率影响大;















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









