







历史文章:
文章目录
一、kafka的分区
1.1、分区的基础概念
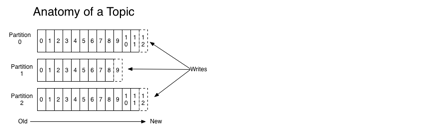
Kafka 有主题(Topic)的概念,它是承载真实数据的逻辑容器,而在主题之下还分为若干个分区,也就是说 Kafka 的消息组织方式实际上是三级结构:主题 - 分区 - 消息。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。官网上的这张图非常清晰地展示了 Kafka 的三级结构。
分区的作用就是提供负载均衡的能力,或者说对数据进行分区的主要原因,就是为了实现系统的高伸缩性(Scalability)。不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处理。并且,我们还可以通过添加新的节点机器来增加整体系统的吞吐量。
1.2、生产者分区策略
也就是我们常说的负载均衡策略。在消息产生的时候你需要将消息发送到不同的分区中存储,那么这时候就需要一个分区策略来决定消息可以发送到哪个分区去。
1.2.1、轮询策略 RoundRobinAssignor(默认)
消息会按照顺序发送到不同的分区。kafka默认的策略就是轮询,轮询策略能保证消息的均衡分配,如果没有特殊要求,建议使用默认配置。
分区1:[消息1,消息4]
分区2:[消息2,消息5]
分区3:[消息3,消息6]
1.2.2、随机策略 Randomness
消息会随机发送到不同分区上。实际场景用到的比较少,不建议使用。
分区1:[消息1,消息3,消息6]
分区2:[消息4,消息5]
分区3:[消息2,消息7]
1.2.3、按key分区策略 Key-ordering
kafka 可以为消息指定key,如果指定了key,那么kafka首先会获取key的hashcode,然后对分区数取模,得到的分区就是对应key存放的分区。
Key-ordering策略可以保证相同key的消息的顺序性,但是会有可能造成数据倾斜。
分区1:[key1,key1,key1]
分区2:[key2,key2]
分区3:[key3,key3]
1.2.4、自定义分区策略
kafka java api提供了一个接口,用于自定义分区策略:org.apache.kafka.clients.producer.Partitioner
用户可以通过实现该接口自定义分区策略。
public interface Partitioner extends Configurable, Closeable {
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes The serialized key to partition on( or null if no key)
* @param value The value to partition on or null
* @param valueBytes The serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
/**
* This is called when partitioner is closed.
*/
public void close();
}
二、kafka的副本
2.1、副本的基础概念
kafka中有个概念叫副本(Replication),kafka的副本指的是分区的副本。分区是kafka存放数据的单位,每个分区有多个副本,其中一个副本是领导者副本 (Leader replica),所有的消息都直接发送给领导者副本;其他副本是追随者副本 (Follower replica),需要通过复制来保持与领导者副本数据一致,当领导者副本不可用时,其中一个追随者副本将成为新首领。
这里有个限制,就是kafka的副本数量不能大于broker节点数量。当你配置是副本数量大于broker节点数量时会报错,这是因为分区是以目录存储在各个broker节点的data目录下,命名为:topicName-分区编号。当副本数量大于broker节点时就表示在同一个Broker节点的data目录下有两个一样的文件夹,会导致报错。
kafka设计副本的好处是:
- 提供数据备份。即使服务宕机也可以保证数据的可用性。
- 弹性伸缩。支持横向扩展,能够通过增加机器的方式来提升读性能,进而提高读操作吞吐量。
- 改善数据局部性。允许将数据放入与用户地理位置相近的地方,从而降低系统延时。
副本的存放:每个分区的副本不能存放在同一台机器下,
broker1:[分区1副本1,分区2父本1]
broker2:[分区2副本2,分区3副本2]
broker3:[分区1副本2,分区3副本1]
2.2、领导者副本(leader)与追随者副本(follower)
在 Kafka 中,副本分成两类:领导者副本(Leader Replica)和追随者副本(Follower Replica)。每个分区在创建时都要选举一个副本,称为领导者副本,其余的副本自动称为追随者副本。
领导者副本是对外提供服务的,读写请求都是经过领导者副本处理的。追随者副本仅仅用于数据的备份,不对外提供服务。追随者副本是通过拉取的方式同步领导者副本的数据。
当领导者副本所在的 Broker 宕机了,会开始新的领导者选举,从追随者副本中选一个作为新的领导者。老的 Leader 副本重启回来后,只能作为追随者副本加入到集群中。
2.3、In-sync Replicas(ISR)
每个分区都有一个 ISR(in-sync Replica) 列表,用于维护所有同步的、可用的副本。ISR 中的副本都是与 Leader 同步的副本,而领导者副本必定存在于ISR副本集中。
满足进入ISR副本集的条件是通过 replica.lag.time.max.ms 参数确定的,这个参数的含义是 Follower 副本能够落后 Leader 副本的最长时间间隔,默认值是 10 秒。Follower 副本唯一的工作就是不断地从 Leader 副本拉取消息,然后写入到自己的提交日志中。如果这个同步过程的速度持续慢于 Leader 副本的消息写入速度,那么在 replica.lag.time.max.ms 时间后,此 Follower 副本就会被认为是与 Leader 副本不同步的,因此不能再放入 ISR 中。任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。
如果OSR中的副本后面慢慢地追上了 Leader 的进度,那么它是能够重新被加回 ISR 的。
2.4、副本的数据同步过程
2.4.1、kafka中的高水位(high watermark)
kafka中用水位来描述一个分区中的可见数据的 offset。
kafka中有个高水位的概念,通过高水位可以标识哪些消息可以被消费者消费的,同时完成所有副本的同步。
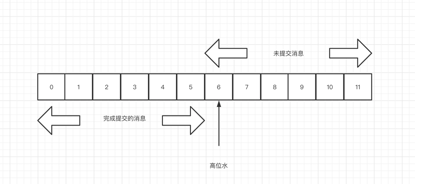
如图所示,offset 6 表示副本中的高水位。在高水位之前的消息,都是已提交的消息,高水位以后的消息(包括高水位)都是未提交的消息。
副本的最后一条消息也就是的12,成为Log End Offset,简写是 LEO,这时候新来了一条消息,会填充到12中。同一个副本对象,其高水位值不会大于 LEO 值,且分区的高水位就是其 Leader 副本的高水位。
2.4.2、副本中高水位HW与LEO的存储方式
在领导者副本中会保存所有追随者副本的LEO与HW值:

-
follower副本更新LEO与HW:
follower副本会通过FETCH从leader副本拉取数据,更新LEO值。
在更新完LEO值后会重新计算HW,具体算法是比较当前是LEO值与leader的HW值,取两者的小者作为新的HW值。 -
leader副本端的follower副本备份更新LEO:
在leader在处理follower FETCH请求时会更新follower副本备份的LEO值。 -
leader副本更新LEO和HW:
leader副本收到数据后就会去更新LEO的值。
在leader副本更新完LEO的值后或者follower FETCH leader副本之后,会重新计算HW的值。 -
HW的计算方式
获取 Leader 副本所在 Broker 端保存的所有远程副本 LEO 值{LEO-1,LEO-2,……,LEO-n}。
获取 Leader 副本高水位值:currentHW。
更新 currentHW = min(currentHW, LEO-1,LEO-2,……,LEO-n)。
2.4.3、同步过程

首先生产者产生了一条数据,写入了leader 副本,leader副本的LEO值被更新为1。
follower副本fetch leader副本的数据,拉取数据后写入本地log,并更新follower副本的LEO值为1。
在新一轮的拉取请求中,follower 会请求拉取offset=1 的消息。leader 副本收到fetch请求后,更新本地follower远程副本 LEO 为 1,然后更新 leader HW 为 1,然后将当前已更新过的高水位HW值=1 返回给 follower 副本。follower 副本接收到后将自己的高水位值更新成 1。
2.5、Leader Epoch
在副本数据同步的过程中,很有可能会发生leader副本挂了,重新进行选举,那么这个follower副本去获取到的LEO与HW的值很有可能是错误的。为了解决这个问题,kafka引入了Leader Epoch,它由两部分数据组成:
- Epoch。一个单调增加的版本号。每当副本领导权发生变更时,都会增加该版本号。
- 起始位移(Start Offset)。Leader 副本在该 Epoch 值上写入的首条消息的位移。
假设有两个 Leader Epoch<0, 0> 和 <1, 10>,那么,第一个 Leader Epoch 表示版本号是 0,这个版本的 Leader 从位移 0 开始保存消息,一共保存了 10 条消息。之后,Leader 发生了变更,版本号增加到 1,新版本的起始位移是 10。
每个副本都引入了Leader Epoch来保存自己当leader时开始写入的第一条消息的offset以及leader版本。这样在恢复的时候完全使用这些信息而非水位来判断是否需要截断日志。















 3407
3407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









