






 FINRA使用AmazonEMR处理大量金融市场数据,通过优化架构、实例管理和监控,实现在4小时SLA内高效处理,降低成本。演讲详细介绍了挑战、解决方案和性能提升策略。
FINRA使用AmazonEMR处理大量金融市场数据,通过优化架构、实例管理和监控,实现在4小时SLA内高效处理,降低成本。演讲详细介绍了挑战、解决方案和性能提升策略。
ANT338 | 紧跟市场波动速度,使用 Amazon EMR 扩展数据处理
关键字: [Amazon Web Services re:Invent 2023, Apache Spark, Market Volatility, Scaling Data Processing, Consolidated Audit Trail, Optimizing Application Architecture, Apache Spark Performance]
本文字数: 1800, 阅读完需: 9 分钟
视频
导读
美国金融监管局的合并审查跟踪系统 (CAT) 是美国金融市场事件的最大单一存储库,使用 Amazon EMR 上的 Apache Spark 处理来自经纪交易商和交易所的数十亿个事件。需在规定的 4 小时 SLA 内处理来自经纪交易商的 2500 多亿个事件和来自交易所的 1.7 万多亿个事件,这是一项极其严峻的考验。此外,数据量每天都会根据市场活动而变化。在本次分享中,美国金融监管局团队讨论了他们如何借助 Amazon EMR 和 Amazon EC2 的最新技术改进 SLA 并降低系统运行成本。
演讲精华
以下是小编为您整理的本次演讲的精华,共1500字,阅读时间大约是8分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。
FINRA专家Meenakshi Shankaran和Sat Kumar Sami为我们带来了关于FINRA如何在四小时的严格服务等级协议内扩展其EMR集群以处理大量金融市场数据的深入见解丰富的演讲。
作为亚马逊云科技的高级大数据架构师,Meenakshi首先介绍了她的身份。她表示,接下来的演讲者Sat Kumar Sami是FINRA的科技总监,负责管理他们的CAT链接器和ETL项目。Meenakhari指出,他们将讨论FINRA在扩展EMR以每天处理数十亿个市场事件并在四小时内提供反馈方面的经验。
她从两个引入性的投票问题开始,以评估观众对大型EMR集群和Spark处理的经验。根据回应,很明显,这个观众是熟悉大规模数据管道挑战的资深人士。
Meenakshi承认我们都有处理截止日期,有些使用场景需要在指定时间内完成。当一个不灵活的SLA与不可预测的数据量相交时,管理就会变得非常困难。这次讨论将关注FINRA为每天处理数十亿个事件而构建的应用程序的实际情况。
特别地,这次演讲将涵盖FINRA概述、合并审计轨迹系统、FINRA如何在其SLA内构建一个处理极端数据量的应用程序以及优化应用程序架构以适应规模的经验教训。
在这个背景建立之后, Meenakhari将舞台交给了Sat, 让他提供更多关于FINRA应用程序、架构和优化过程的详细信息。
- 经纪商和交易所提交数据文件
- 对文件进行文件和记录级别的验证
- 有效记录进入下一环节,无效记录则被拒绝
- 验证并关联相关事件,找出父记录
- 在4小时内向提交者提供反馈
SAT强调,4小时的SLA非常紧迫。链路验证是整个流程中的关键部分。
随后,他概述了所面临的主要挑战:
- 性能:必须在4小时内完成处理
- 韧性:不能有任何时间损失。作业必须能够快速恢复。
- 可扩展性:市场波动可能导致数据量的突发性增长。系统必须能够动态调整扩展能力。
- 成本:随着数据量的增加,计算和存储成本也会上升。
在这些限制条件下,优化非功能参数如韧性、可扩展性和性能是实现SLA的关键。仅仅增加更多的容量而应用程序无法线性扩展是无济于事的。需要在满足SLA的前提下,有效地平衡应用的增强、韧性和可扩展性。
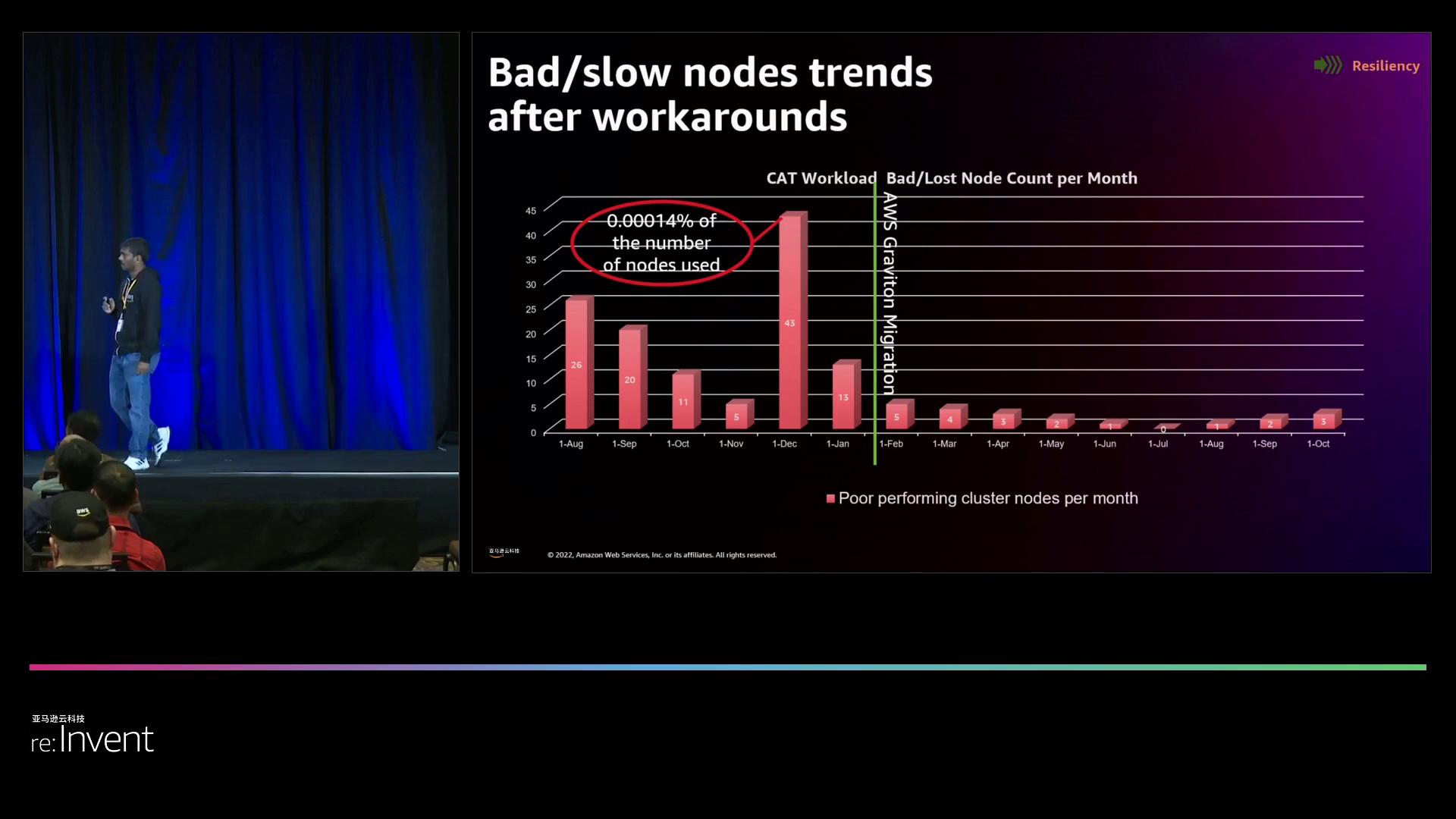
转换为Graviton实例,减少错误并提高稳定性。
- 通过弹性MapReduce(EMR)升级解决执行器和驱动器之间的通信间隙等问题。
- 优化Spark的猜测功能,避免使用性能不佳的实例。
- 配置节点排除功能,防止在后期使用慢速实例。
构建一套自定义监控系统,用于追踪和自动消除不良实例。这一变革使得性能不佳的实例影响降低了将近10倍。通过优化基础架构来辅助应用程序的改进,FINRA能够应对偶尔出现的硬件问题。
接下来的挑战是扩大EMR集群以适应S3分区的突发流量。由于他们的工作负载模式,他们开始达到S3吞吐量限制,从而导致503减速错误和作业失败。通过与S3团队合作,他们对前缀进行了重新分区以提高吞吐量。他们还采用自动扩展策略,减少了503错误75%。其他策略如优化文件大小、工作负载调度和利用分区修剪也进一步减轻了压力。
针对集群容量,有针对性的按需容量预留确保了关键工作负载的资源。通过在周末挂起未使用的预留,FINRA优化了成本。
在提高性能和规模之后,Meenakshi探讨了成本优化的问题。通过将关联处理迁移到Graviton,他们将价格性能提高了60%。对于非关键工作负载,多样化实例类型减少了对更昂贵的按需容量的依赖。
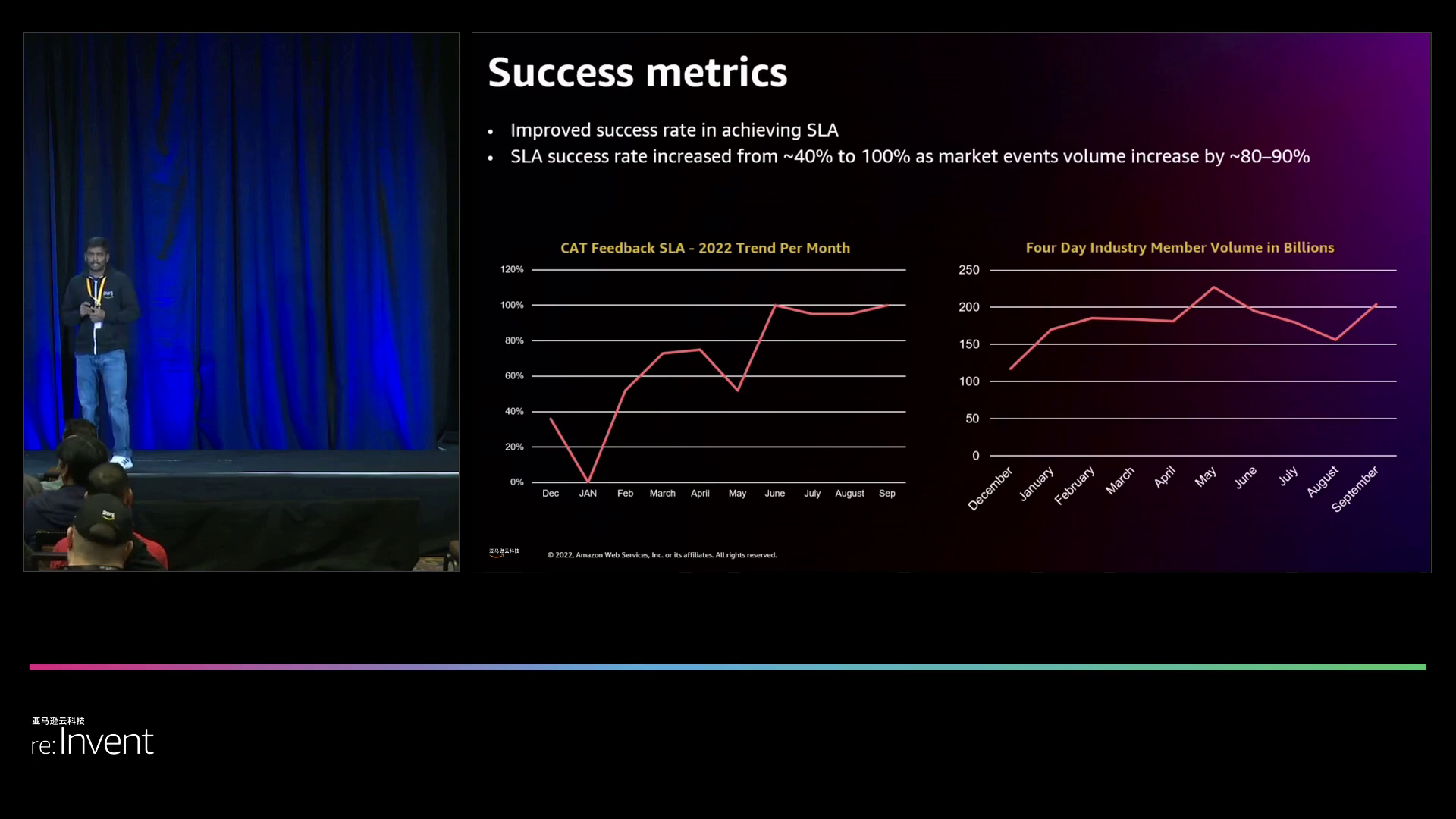
总的来说,通过全方位优化应用程序、基础设施和服务,FINRA将数据量提高到了原来的两倍,同时将计算小时数减少了50%,SLA合规性从40%提高到了100%。
持续进行的项目包括继续探索新技术,如EKS上的EMR、下一代实例、Apache Iceberg和Spark 3.2,以推动进一步的改进。
Meenakshi和Sat清晰地描述了FINRA在构建一个大规模可扩展、有弹性的数据处理管道所面临的挑战。通过分享他们在架构、软件、硬件、配置和基础设施方面的优化历程,他们提供了一份如何应对这些复杂大数据挑战的蓝图。他们系统地测试、监控和改进的方法显然在性能、规模和成本方面带来了巨大的回报。
FINRA的经验教训为任何寻求建立高度可扩展且健壮的数据平台的组织提供了宝贵的指导。他们的发展历程强调了在应用和基础设施两个方面实现端到端全面优化的重要性。Meenakshi和Sat的演讲提供了一系列实用的技术见解,有助于数据工程师应对大规模数据处理和严格服务等级协议所带来的挑战。
下面是一些演讲现场的精彩瞬间:
定期检查点(checkpointing)和作业自动重启是实现故障恢复的关键,这可以超过50%的时间防止手动干预。

领导者探讨了如何构建具有弹性和容错能力应用程序来应对性能不佳的硬件。

亚马逊云科技现已支持将一个团队中的实例类型从5个增至30个,并通过分配策略优化诸如EMR和EC2等服务的能力及成本。

在尝试多种实例类型后,尽管数量有所增加,但亚马逊云科技发现集群创建成功率得到了提高,整体服务等级协议(SLA)实现达到了100%。
领导者还谈到了评估新的亚马逊云科技功能,如EMR、EKS、Apache Iceberg、Graviton 3、EBS gp3卷、Apache Spark 3.2及应用现代化,以进一步提升可扩展性和性能。
为您的业务负载选择合适的亚马逊云科技实例类型,并设计您的应用以适应高峰流量。

总结
这是一篇关于FINRA如何利用亚马逊EMR扩展数据处理能力的演讲稿。FINRA负责监管经纪商,每天处理超过6000亿条记录。其合并审计追踪系统有助于跟踪市场活动并识别操纵行为。各公司必须在早上8点之前提交每日交易,而FINRA需要在4小时内完成处理并提供反馈——这是一个针对数十亿条记录的紧缩服务等级协议。
最初,FINRA使用非渐进式架构在早上8点后处理所有数据。他们通过在早上8点之前处理80%的数据优化了这一过程,节省了2个小时。通过定期升级Spark,性能得到了提升,例如在升级到EMR 6.5时实现了30%的增长。通过使用Graviton的NVMe磁盘优化了Shuffle操作,提高了性能30%并降低了成本50%。检查点、自动重启和跟踪作业状态提供了恢复力。
在基础设施方面,通过实例类型优化、EMR升级、配置调整、自定义监控和自动化实例删除,每天可以减少40-50倍的不称职实例。为了处理并发工作负载的S3限流问题,分区请求率策略将错误减少了79%。工作负载优化和调度也有帮助。容量保证来自于按需预留和分配策略。采用Graviton后,成本降低了50%。
关键收获是在应用、基础设施、可扩展性和恢复力方面进行性能测试。选择最优的实例类型并定期升级软件。设计可扩展的应用。
演讲原文
想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
2023亚马逊云科技re:Invent全球大会 - 官方网站
点击此处,一键获取亚马逊云科技全球最新产品/服务资讯!
点击此处,一键获取亚马逊云科技中国区最新产品/服务资讯!
即刻注册亚马逊云科技账户,开启云端之旅!
【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”
亚马逊云科技是谁?
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者,自 2006 年以来一直以不断创新、技术领先、服务丰富、应用广泛而享誉业界。亚马逊云科技可以支持几乎云上任意工作负载。亚马逊云科技目前提供超过 200 项全功能的服务,涵盖计算、存储、网络、数据库、数据分析、机器人、机器学习与人工智能、物联网、移动、安全、混合云、虚拟现实与增强现实、媒体,以及应用开发、部署与管理等方面;基础设施遍及 31 个地理区域的 99 个可用区,并计划新建 4 个区域和 12 个可用区。全球数百万客户,从初创公司、中小企业,到大型企业和政府机构都信赖亚马逊云科技,通过亚马逊云科技的服务强化其基础设施,提高敏捷性,降低成本,加快创新,提升竞争力,实现业务成长和成功。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









