







对平台上发布的租房信息进行抓取
分析网页
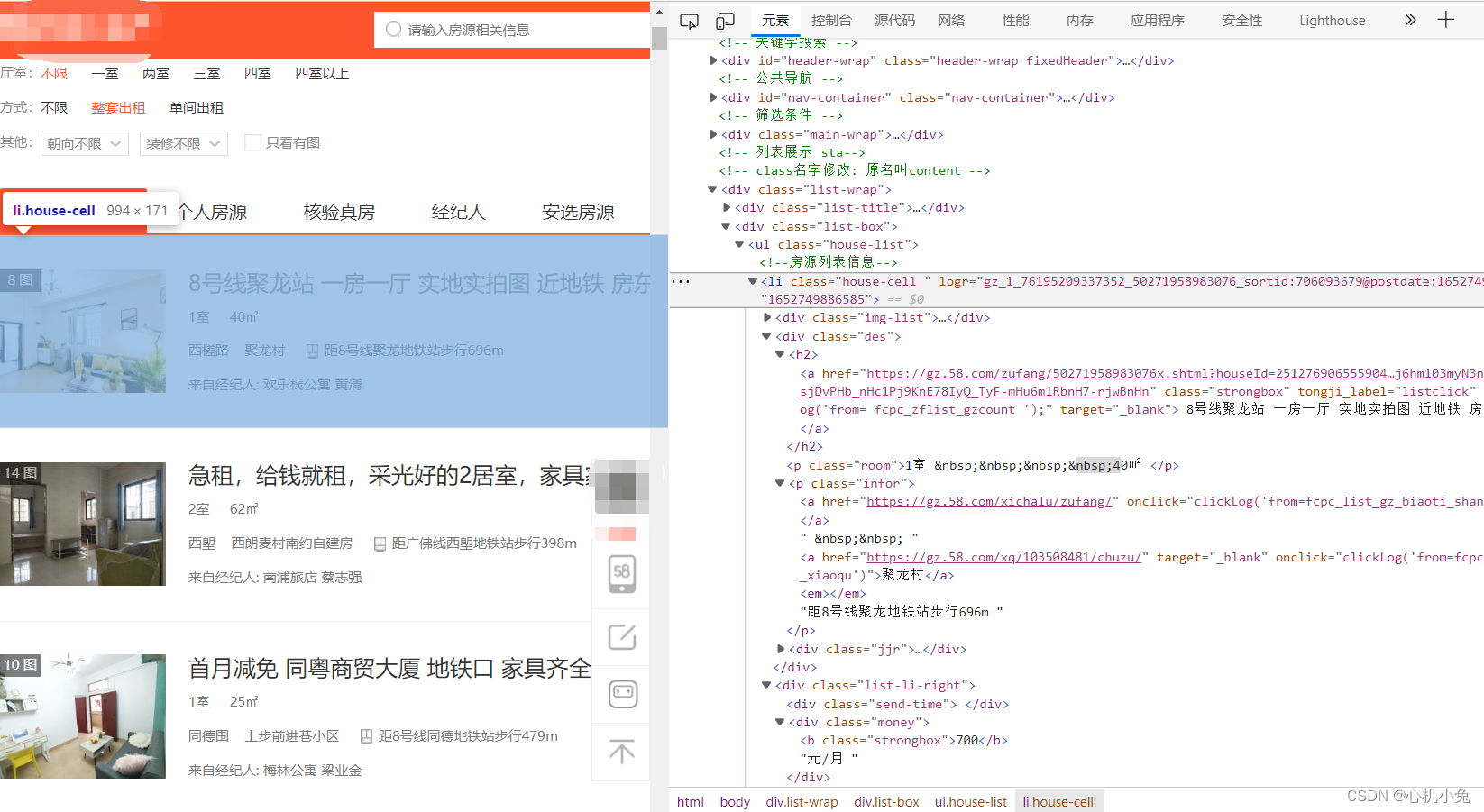
(一)这个网站的画相对简单一点,每条信息基本都是存放在一个 li 标签下(二)选择用 BeautifulSoup 进行解析
(三)再根据属性值进行定位
(四)用 get_text() 获取标签文本
这里我就直接数了一下获取到的每一个值,直接列表切割得到数据

代码
简单易操作,笨人有笨方法,直接上,注释都懒了
# 心机小兔的python之路
# @Time : 2022/5/20 11:46
import requests
from bs4 import BeautifulSoup
def get_html(url,headers):
html = requests.get(url,headers=headers)
soup = BeautifulSoup(html.text,'lxml')
li_list = soup.find_all('li')
for li in li_list:
try:
directory = li.find('a',class_="strongbox").get_text()[25:55]
size1 = li.find('p',class_="room").get_text()[0:2]
size2 = li.find('p',class_="room").get_text()[26:29]
locations = li.find('p',class_="infor").get_text().split()
location = locations[0] + "," + locations[1] + "," + locations[2]
price = li.find('div',class_="money").get_text()[1:9]
item = {}
item['directory'] = directory
item['size1'] = size1
item['size2'] = size2
item['location'] = location
item['price'] = price
print(item)
except:
pass
if __name__ == '__main__':
url = 'https://gz.58.com/zufang/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32'
}
get_html(url,headers=headers)
总结
其实方法多的是,只是刚好回顾了一下bs4,心血来潮敲两下,也没写文件的保存,有兴趣的兄弟可以试着往下写,不难
















 1881
1881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











