







contents
数据库简介
数据库系统:数据库、数据库管理系统、应用开发工具
数据库:储存数据的仓库
数据库管理系统:用来定义数据管理和维护数据的软件,eg:MySQL,Oracle
基本操作
- 登入
mysql -uroot -p - 退出
exit
quit
\q - Welcome to the MySQL monitor. Commands end with ; or \g.
提示默认分隔符是 ;或者 \g - 注释符号是#或者–
语句规范
- 关键字与函数名称全部大写
- 数据库名称、表名称、字段名称等全部小写
- SQL语句必须以分隔符结尾
- SQL语句支持折行操作,只要不把单词、标记或引号字符串分割为两部分,可以在下一行继续写
- 数据库名称、表名称、字段名称等尽量不要使用MySQL的保留字,如果需要使用的时候需要** 使用反引号**(``) 将名称括起来
命令输出到文本文件
开始输入:\T E:\mysql\mysqlDemo\mysql.txt
结束:\t
常用命令
- 查看上一步操作产生的警告信息
SHOW WARNINGS; - 得到当前打开的数据库名称
SELECT DATABASE()|SCHEMA(); - help 想查询的东西 eg: help TINYINT; help CREATE DATABASE;
数据库操作(DDL)
{}表示必须出现,|表示二选一,[]表示可选
- 创建数据库
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name [[DEFAULT] CHARACTER SET [=] charset_name] - 查看当前服务器下的数据库列表
SHOW {DATABASES|SCHEMAS} - 查看指定数据库的定义
SHOW CREATE {DATABASE|SCHEMA} db_name - 修改指定数据库的编码方式
ALTER {DATABASE|SCHEMA} db_name [DEFAULT] CHARACTER SET [=] charset_name - 打开指定数据库
USE db_name - 得到当前打开的数据库名称
SELECT DATABASE()|SCHEMA(); - 删除指定数据库
DROP {DATABASE|SCHEMA} [IF EXISTS] db_name
表
概念
数据表是数据库最重要的组成部分之一,是其它对象的基础,存储数据的数据结构,包含了特定实体类型的数据,由行(row)和列(column)构成的二维网络。
数据表一定先有表结构,再有数据,至少有一列,可以没有行或者多行,数据表名称要求唯一,而且不要包含特殊字符。
创建数据表
CREATE TABLE [IF NOT EXISTS] tbl_name(
字段名称 字段类型 [完整性约束条件]
…
)ENGINE=引擎名称 CHARSET=‘编码方式’;
| 完整性约束条件 | 说明 |
|---|---|
| PRIMARY KEY 主键 | 一般是无意义字段,不能重复,会自动设置不能为空。 可创建单一字段(直接加在字段类型后),也可创建复合主键(PRIMARY KEY(字段名1,字段名2)) |
| AUTO_INCREMENT 自增长 | 一个表中只能有一个自增长,一般要配合主键使用 不指定时或值为NULL或DEFAULT时,在已有编号最大值+1 在建表时,可指定自增长起始值AUTO_INCREMENT=数字 修改自增长值用语句 ALTER TABLE tbl_name AUTO_INCREMENT=数字 |
| UNIQUE KEY唯一 | 值不能重复(NULL除外),一个表可有多个UNIQUE,但只能有一个主键 |
CREATE TABLE IF NOT EXISTS test11(
id INT AUTO_INCREMENT,
user_name VARCHAR(20) NOT NULL UNIQUE KEY, #非空且唯一
card CHAR(5),
PRIMARY KEY(id,card) #作为复合关键字
);
#自增长测试
INSERT test11 VALUES (1,'king','2314');
INSERT test11 VALUES (2,'queen','123'); #不指定时或值为NULL或DEFAULT时,在已有编号最大值+1
ALTER TABLE test11 AUTO_INCREMENT=100;
INSERT INTO test11 (user_name,card)VALUES ('xiatian','233');
SELECT * FROM test11;

数据类型
整数类型
在数据类型后加(数字),表显示长度,如,INT(3) .
在后面跟上ZEROFILL,表示长度不足的部分用零填充。

浮点类型

- 浮点类型DOUBLE精度比FLOAT类型高,如果需要精确到10位以上,就应该选择DOUBLE类型。
- 都会四舍五入,DECIMAL以字符串形式存储经度较高,如3.14159,decimal通过四舍五入存为‘3.14’,转换成浮点数可能是3.139999999
CREATE TABLE test2(
num1 FLOAT(6,2),
num2 DOUBLE(6,2),
num3 DECIMAL(6,2)
);
INSERT test2 VALUES(3.14159,3.1499,3.149)
INSERT test2 VALUES(3.14159,3.2499,3.149)
SELECT * FROM test2 WHERE num2=3.25 and num3=3.15; #成功
字符串类型

- CHAR定长字符串,占用空间大,速度快,
VARCHAR变长字符串,占用空间小,速度慢 - CHAR在保存的时候,后面会用空格填充到指定的长度,在检索的时候后面的空格会去掉;
VARCHAR在保存的时候,不进行填充。当值保存和检索时尾部的空格仍保留。
但是前面的空格都会保留。 - TEXT类型是一种特殊的字符串类型。只能保存字符数据,而且不能有默认值
- 据检索的效率CHAR>VARCHAR>TEXT
- ENUM插入值只能从列举出来的值中选一个,每个值都有一个序号,mysql实际保存的是序号,会自动清除字符后的空格,默认可为空
- set插入是可选多个值,之间用逗号分隔,以二进制保存
CREATE TABLE IF NOT EXISTS test3(
sex ENUM('男','女','保密')
);
INSERT test3 VALUES ('男');
INSERT test3 VALUES ('男');
INSERT test3 VALUES ('女');
INSERT test3 VALUES ('1');
INSERT test3 VALUES ('2');
INSERT test3 VALUES(NULL);
SELECT * FROM test3;
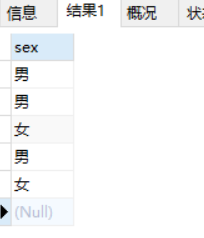
CREATE TABLE IF NOT EXISTS test4(
fav SET('A','B','C','D','E')
);
INSERT test4 VALUES ('A,D');
INSERT test4 VALUES ('D,B,A');
INSERT test4 VALUES (3);
INSERT test4 VALUES (15);
SELECT * FROM test4;

日期时间类型

- 一般是用整型来保存时间戳
- year插入值可以数字可以是字符串,也支持两位数字(或两位字符串),00 ~ 69会转换成2000~2069,70 ~99会转换成1970 ~1999之间,数字0会转成0000,‘0’会转成2000
- time 第一个是包括了天数的小时,天数在0~34之间,依次省略小时、分钟、秒
CREATE TABLE IF NOT EXISTS test5(
t TIME
);
INSERT test5 VALUES('1 12:12:12');
INSERT test5 VALUES('12:12');
INSERT test5 VALUES('1234');
INSERT test5 VALUES('12');
SELECT * FROM test5;

CREATE TABLE IF NOT EXISTS test6(
t DATE
);
INSERT test6 VALUES('21-03-20');
INSERT test6 VALUES('210320');
INSERT test6 VALUES('21@03/20');
SELECT * FROM test6;

二进制类型
主要是用来保存图片,向量等
字段选择类型示例
| 字段 | 类型 | 代码 |
|---|---|---|
| 编号 | 整数(无符号) | MEDIUMINT 或 MEDIUMINT UNSIGNED |
| 姓名 | 字符串 | VARCHAR(20) |
| 年龄 | 整数 | TINYINT |
| 性别 | 字符串 | ENUM(‘男’,‘女’,‘保密’) |
| 薪水 | 浮点数 | FLOAT(8,2) |
| 是否结婚 | 布尔类型 | TINYINT(1) |
note:
通过COMMENT ’ 注释内容 ’ 给字段添加注释
CREATE DATABASE IF NOT EXISTS learnsql CHARACTER SET = 'utf8';
USE learnsql;
CREATE TABLE IF NOT EXISTS `user`(
id SMALLINT,
username VARCHAR(20),
age TINYINT,
sex ENUM('男','女','保密'),
salary FLOAT(8,2),
maried TINYINT(1) COMMENT '0表示未婚,非0表示已婚'
)ENGINE=INNODB CHARSET=UTF8;
存储引擎
存储引擎就是指表的类型。数据库的存储类型决定了表在计算机中的存储方式。用户可以根据不同的存储方式、是否进行事务处理等来选择合适的存储引擎。
| 需要 | 操作 |
|---|---|
| 查看MySQL支持的存储引擎 | SHOW ENGINES;或者SHOW ENGINES\G;以表格形式展现 |
| 查看显示支持的存储引擎信息 | SHOW VARIABLES LIKE ‘have%’ |
| 查看默认的存储引擎 | SHOW VARIABLES LIKE ‘storage_engine’ |
常用引擎
| 引擎 | 优缺点 | 存储位置 |
|---|---|---|
| InnoDB存储引擎 (默认) | 读写效率低,占用的空间较大,支持事物处理,也支持外键,支持奔溃修复和并发控制 | |
| MyISAM存储引擎 | 占用空间小,插入数据、读取数据速度快 ,不支持事物,不支持事物的完整性和安全性 | 表结构在frm,表数据在MYD,索引在MYI |
| MEMORY存储引擎 | 存在内存中,速度快,提高效率,服务器就需要足够的内存,默认哈希索引;在出现异常时,影响数据完整性,安全性较低,生命周期短,且不能建立较大的表11 |
表的常用操作
| 表操作 | 代码 |
|---|---|
| 查看数据库下的数据表 | SHOW TABLES |
| 查看指定表的表结构 | DESC tbl_name;或 DESCRIBE tbl_name;或 SHOW COLUMNS FROM tbl_name |
| 查看表的详细信息 | SHOW CREATE TABLE tbl_name; |
| 向表中插入记录 | INSERT tbl_name VALUES(数据1, 数据2, …) |
| 查询表中所有记录 | SELECT * FROM tbl_name; |
| 字符所占用的空间 | SELECT LENGTH(‘字符’) |
| 字符的长度 | SELECT CHAR_LENGTH(‘字符’) |
| 修改表名 | ALTER TABLE tbl_name RENAME [TO|AS] new_name RENAME TABLE tbl_name TO new_name |
| 删除数据表 | DROP TABLE [IF EXISTS] tbl_name[,tbl_name…] |
建表通用格式:
CREATE TABLE [IF NOT EXISTS] tbl_name(
字段名 字段类型 [UNSIGNED|ZEROFILL] [NOT NULL] [DEFAULT 默认值] [[PRIMARY] KEY|UNIQUE [KEY]] [AUTO_INCREMENT]
);ENGINE=INNODB CHARSET=UTF8 AUTO_INCREMENT=100;
| 字段操作 | 代码 |
|---|---|
| 添加字段 | ALTER TABLE tbl_name ADD 字段名称 字段类型 [完整性约束条件] [FIRST|AFTER 字段名称] |
| 删除字段 | ALTER TABLE tbl_name DROP 字段名称 |
| 修改字段类型、属性、位置 | ALTER TABLE tbl_name MODIFY 字段名称 字段类型 [完整性约束条件] [FIRST|AFTER 字段名称] 没有重写的部分不保留之前的设定,而是恢复默认值 |
| (比上面能多) 修改字段名称 | ALTER TABLE tbl_name CHANGE 旧字段名称 新字段名称 字段类型 [完整性约束条件] [FIRST|AFTER 字段名称] |
| 添加默认值 | ALTER TABLE tbl_name ALTER 字段名称 SET DEFAULT 默认值 |
| 删除默认值 | ALTER TABLE tbl_name ALTER 字段名称 DROP DEFAULT |
| 修改表的存储引擎 | ALTER TABLE tbl_name ENGINE=存储引擎名称 |
| 约束条件操作 | 代码 |
|---|---|
| 添加主键 | ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] PRIMARY KEY[index_type] (字段名称,…) |
| 删除主键 | ALTER TABLE tbl_name DROP PRIMARY KEY 若该字段还是自增长的,则需要用MODIFY去掉自增长(MODIFY只能去除主键以外的属性) |
| 添加唯一 | ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY] [索引名称](字段名称,…) |
| 删除唯一 | ALTER TABLE tbl_name DROP {INDEX|KEY} index_name |
| 修改自增长值用语句 | ALTER TABLE tbl_name AUTO_INCREMENT=数字 |
# 选中一个表,完成多个操作
ALTER TABLE test4
ADD sex ENUM('男','女','保密') NOT NULL DEFAULT '保密',
ADD age INT UNSIGNED NOT NULL DEFAULT 100 AFTER fav,
ADD grade SET('A','B','C') FIRST ;
DROP fav;
SELECT * FROM test4;
数据操作
| 插入数据方式 | 代码 | 说明 |
|---|---|---|
| 不指定具体的字段名 | INSERT [INTO] tbl_name VALUES|VALUE(值…) | 需要按照建表时的字段给每个都赋值,一次插入多条记录时用VALUES |
| 列出指定字段 | INSERT [INTO] tbl_name(字段名称1,…) VALUES|VALUE(值1,…) | 值和字段需要一一对应 |
| 同时插入多条记录 | INSERT [INTO] tbl_name(字段名称…) VALUES(值…),(值…)… | 只需一个VALUES |
| 通过SET形式插入记录 | INSERT [INTO] tbl_name SET 字段名称=值,… | |
| 将查询结果插入到表中 | INSERT [INTO] tbl_name[(字段名称1,…)] SELECT 字段名称1,… FROM tbl_name [WHERE 条件] | 字段数量应匹配 |
| 更新数据方式 | 代码 | 说明 |
|---|---|---|
| 更新 | UPDATE tbl_name SET 字段名称=值,… [WHERE 条件][ORDER BY 字段名称][LIMIT 限制条数] | 若不加where条件,表中该字段所有值都被更新 LIMIT这里不能设置偏移量 |
UPDATE cms_user SET age=age-3 where id>3;
UPDATE cms_user SET age=DEFAULT where user_name='A';
UPDATE cms_user SET age=age+5 where username LIKE '____' ORDER BY sex DESC LIMIT 3;
| 删除数据方式 | 代码 | 说明 |
|---|---|---|
| 按条件删除 | DELETE FROM tbl_name [WHERE 条件][ORDER BY 字段名称][LIMIT 限制条数] | 不加条件的话,所有条件会被删掉,但不会重置AUTO_INCREMENT的值 LIMIT没有偏移量的参数 |
| 彻底清空数据表 | TRUNCATE [TABLE] tbl_name | 会重置AUTO_INCREMENT |
当你不再需要该表时, 用 DROP TABLE IF EXISTS tbl_name;当你仍要保留该表,但要删除所有记录时, 用 TRUNCATE tbl_name;当你要删除部分记录时(always with a WHERE clause), 用 delete.
数据查询操作
SELECT select_expr [, select_expr …]
\qquad
[
\qquad\qquad
FROM table_references
\qquad\qquad
[WHERE 条件]
\qquad\qquad
[GROUP BY {col_name | position} [ASC | DESC], … 分组]
\qquad\qquad
[HAVING 条件 对分组结果进行二次筛选]
\qquad\qquad
[ORDER BY {col_name | position} [ASC | DESC], …排序]
\qquad\qquad
[LIMIT 限制显示条数]
\qquad
]
| select_expr 查询表达式 | 代码 |
|---|---|
| 每一个表达式表示想要的一列,必须至少有一列,多个列之间以逗号分隔,会按照字段顺序进行显示 | SELECT 字段名称1,… FROM tbl_name; |
| *表示所有列,tbl_name.*可以表示命名表的所有列 | SELECT tbl_name.* FROM tbl_name; |
| 可以使用[AS]alias_name为表赋予别名 | SELECT alias_name.字段名称1,… FROM tbl_name AS alias_name; |
| 可以使用[AS]alias_name给字段起别名 | SELECT 字段名称1 AS 别名1’,… FROM cms_admin; |
若查询的不在一个库则用 db_name.tbl_name
SELECT a.id,a.password FROM cms_admin AS a;

SELECT id AS '编号', email AS '邮箱' FROM cms_admin;

SELECT 1,2,3,4,id,password FROM cms_admin;

| where条件 | 代码 | 示例 |
|---|---|---|
| 比较 | = ,<,<=,>,>=,!=,<>,!>,!<,<=>(表示等号,可检测是否为NULL) | WHERE 字段名称 <=>NULL |
| 是否为空值 | IS NULL,IS NOT NULL | WHERE 字段名称 IS NULL |
| 指定范围 | BETWEEN AND(闭区间), NOT BETWEEN AND | WHERE 字段名称 BETWEEN a AND b |
| 指定集合 | IN ,NOT IN | WHERE 字段名称 IN (属性1,…) note:会忽略属性的大小写 |
| 匹配字符(模糊查询) | LIKE,NOT LIKE %表示0个1个任意多个字符,_表示1个任意字符 | WHERE 字段名称 LIKE ‘正则表达式’; |
| 多个查询条件 | AND, OR |
| GROUP BY查询结果分组 | 代码 | 说明 |
|---|---|---|
| GROUP BY分组 | GROUP BY 字段名称1,… (字段位置也可) | 只会显示每组的第一条记录 注意:所有列必须是聚合列 |
| 配合GROUP_CONCAT()得到分组详情 | SELECT *,GROUP_CONCAT(详细字段名称) FROM tbl_name GROUP BY 字段 名称; | 只有括号内的字段名会显示全部记录,其他字段只显示第一条记录 |
| 配合聚合函数 [COUNT(),MAX(),MIN(),AVG(),SUM()] | SELECT COUNT(*),MAX(字段名称),… FROM cms_user; | COUNT(*)#表示统计所有记录,统计若为字段,则不统计NULL |
| 配合WITH ROLLUP记录上面所有记录的总和 | 加在末尾 | 显示各个字段的属性计数,或者聚合函数得到一列数的聚合函数 |
#GROUP_CONCAT
SELECT proId,sex,GROUP_CONCAT(username),GROUP_CONCAT(`password`) FROM cms_user
GROUP BY sex;

#聚合函数,GROUP_CONCAT
SELECT id,sex,GROUP_CONCAT(username) AS users,COUNT(*) AS total FROM cms_user GROUP BY sex;
SELECT COUNT(*) AS total FROM cms_user; #统计表中所有记录
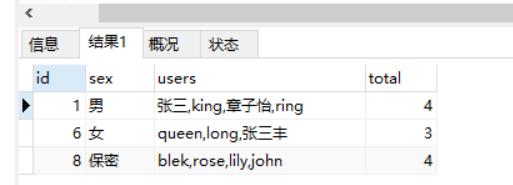

#聚合函数
SELECT id,sex,GROUP_CONCAT(username) AS users,
COUNT(*) AS total,
MAX(age) AS max_age,
MIN(age) AS min_age,
AVG(age) AS avg_age,
SUM(age) AS sum_age
FROM cms_user GROUP BY sex;

#WITH ROLLUO
SELECT id,sex,GROUP_CONCAT(username) AS users,
COUNT(*) AS total,
MAX(age) AS max_age,
MIN(age) AS min_age,
AVG(age) AS avg_age,
SUM(age) AS sum_age
FROM cms_user GROUP BY sex
WITH ROLLUP;
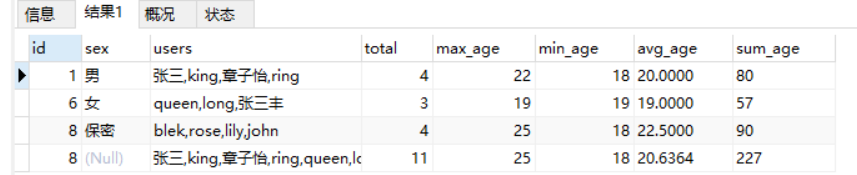
| HAVING子句 | 代码 | 示例 |
|---|---|---|
| 通过HAVING子句对分组结果进行二次筛选 | 只能在GROUP BY 之后 HAVING 字段名 条件 | 只能使用在分组之后才有意义 |
SELECT sex,GROUP_CONCAT(username) AS users,
COUNT(*) AS group_total,
MIN(age) AS min_age
FROM cms_user GROUP BY sex
HAVING COUNT(*)>3;

SELECT sex,GROUP_CONCAT(username) AS users,
COUNT(*) AS group_total,
MIN(age) AS min_age
FROM cms_user GROUP BY sex
HAVING COUNT(*)>3 AND MAX(age)>23;

| ORDER BY | 代码 | 说明 |
|---|---|---|
| 通过ORDER BY对查询结果排序 | SELECT * FROM tbl_name ORDER BY 字段名称1,… DESC; | DESC降序,ASC升序为默认 |
| ORDER BY 和RAND随机排列 | SELECT * FROM tbl_name ORDER BY RAND(); |
SELECT * FROM cms_user ORDER BY age,id DESC; #按照年龄升序,id降序排列

| LIMIT限制查询结果显示条数 | 代码 | 说明 |
|---|---|---|
| LIMIT 显示条数 | SELECT * FROM tbl_name LIMIT 显示条数; | |
| LIMIT 偏移量,显示条数 | SELECT * FROM tbl_name LIMIT 偏移量,显示条数 | 结果点的偏移量是从0开始 |
LIMIT是实现分页的核心
SELECT sex, GROUP_CONCAT(username),
COUNT(*) AS group_total,
MAX(age) AS max_age,
AVG(age) AS avg_age
FROM cms_user
GROUP BY proId
ORDER BY MIN(age) DESC
LIMIT 0,2;
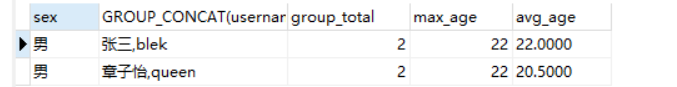
连接查询
连接查询是将两个或两个以上的表按某个条件连接起来,从中选取需要的数据。当不同的表中存在相同意义的字段时,可以通过该字段连接这几个表。
内连接查询
JOIN,CROSS JOIN, INNER JOIN都是一个意思
- step1:明确要查的内容,具体到表的字段
- step2:写查询语句 (表1和表2可交换)
SELECT 别名1.字段1,别名1.字段2,…别名2.字段1,别名2.字段2,…
FROM 表名1 AS 别名1
JOIN 表名2 AS 别名2
ON 连接条件
JOIN 表名3 AS 别名3
ON 连接条件 - step3:加上筛选条件、分组;
- step4:就显示了新表
SELECT a.id,a.username,p.proName,COUNT(*) AS group_total
FROM cms_user AS a
JOIN provinces AS p
ON a.proId=p.id
WHERE a.id>2
GROUP BY p.proName;

SELECT n.id,n.title,n.content,c.cateName,c.cateDesc,a.username,a.role
FROM cms_news AS n
JOIN cms_cate as c
ON n.cId=c.id
JOIN cms_admin as a
on n.aId=a.id;

外连接查询
| 外连接 | 说明 | 代码 |
|---|---|---|
| 左外连接 | 显示左表的全部记录及右表符合连接条件的记录 | LEFT [OUTER] JOIN |
| 右外连接 | 显示右表的全部记录以及左表符合条件的记录 | RIGHT [OUTER] JOIN |
匹配失败则为NULL
外键操作
- 外键是表的一个特殊字段。保持数据的一致性和完整性。
- 被参照的表是主表,外键所在字段的表为子表。外键依赖于数据库中已存在的表的主键。
- 外键的作用是建立该表与其父表的关联关系。父表中对记录做操作时,子表中与之对应的信息也应有相应的改变。可以实现一对一或一对多的关系。
- 父表和子表必须使用相同的存储引擎InnoDB,而且禁止使用临时表。
- 创建:建表时创建外键,通过ALTER语句添加、删除外键
外键列和参照列必须具有相似的数据类型。其中数字的长度或是否有符号位必须相同;而字符的长度则可以不同。 - 外键列和参照列必须创建索引。如果外键列不存在索引的话,MySQL将自动创建索引。删除外键时索引不会被删除。
创建外键
- 必须先有主表,在创建子表时,字段后加上
[CONSTRAINT 子表_fk_主表] FOREIGN KEY(字段名称) REFERENCES 父表(字段名称)
note:
[CONSTRAINT 子表_fk_主表] :指定外键名称 - 通过ALTER语句,要注意外键在子表和主表是否已经一一对应
ALTER TABLE 子表名称 ADD [CONSTRAINT 子表_fk_主表] FOREIGN KEY(字段名称) REFERENCES 主表名称(字段名称)
删除外键
ALTER TABLE 子表名称 DROP FOREIGN KEY 外键名称
指定父表变化后对子表的反应
| 外键约束的参照操作 | 说明 | 代码 |
|---|---|---|
| CASCADE | 从父表删除或更新且自动删除或更新子表中匹配的行。 | ON DELETE CASCADE ON UPDATE CASCADE |
| SET NULL | 从父表删除或更新行,并设置子表中的外键列为NULL。如果使用该选项,必须保证子表列没有指定NOT NULL。 | N DELETE SET NULL ON UPDATE SET NULL |
| RESTRICT(默认) | 拒绝对父表的删除或更新操作。 | |
| NO ACTION | 标准SQL的关键字,在MySQL中与RESTRICT相同。 |
-- 创建员工表employee(子表)
-- id ,username ,depId
CREATE TABLE IF NOT EXISTS employee(
id SMALLINT UNSIGNED AUTO_INCREMENT KEY,
username VARCHAR(20) NOT NULL UNIQUE,
depId TINYINT UNSIGNED,
FOREIGN KEY(depId) REFERENCES department(id) ON DELETE CASCADE ON UPDATE CASCADE
)ENGINE=INNODB;
联合查询
| 联合查询 | 说明 |
|---|---|
| UNION | 去掉相同记录 |
| UNION ALL | 简单的合并到一起 |
要保证查询的字段数目要相同,对应位置的字段合并
SELECT username,age FROM employee UNION SELECT username,age FROM cms_user;
SELECT username,age FROM employee UNION ALL SELECT username,age FROM cms_user;
子查询
子查询是将一个查询语句嵌套在另一个查询语句中。内层查询语句的查询结果,可以作为外层查询语句提供条件。
子查询是先查询的内容,而且一定要放在括号中
| 子查询的情况 | 粗略代码 | 子查询代码 |
|---|---|---|
| 使用[NOT]IN的子查询 | SELECT 字段名称1,… FROM 表1; SELECT 字段名称2,… FROM 表2 WHERE 字段名称3 IN(表1中字段名称1的属性); | SELECT 字段名称2,… FROM 表 2 WHERE 字段名称 3 IN(SELECT 字段名称1,… FROM 表1); |
| 使用比较运算符的子查询 | SELECT 字段名称1,… FROM 表1 WHERE 满足条件; SELECT 字段名称2,… FROM 表2 WHERE 字段名称3 比较运算符(表1中字段名称1的属性); | SELECT 字段名称2,… FROM 表 2 WHERE 字段名称 3 比较运算符(SELECT 字段名称1,… FROM 表1WHERE 满足条件); |
| 使用[NOT]EXISTS的子查询 | SELECT 字段名称1,… FROM 表名称 WHERE EXISTS(子查询语句) | 子查询语句为真(非空),才会查询外层的语句 |
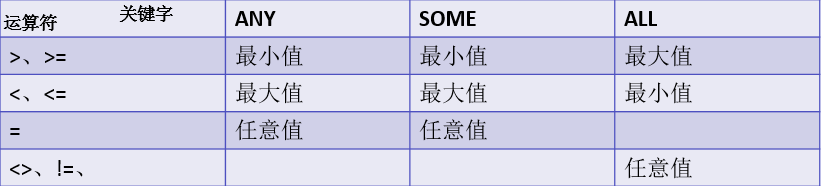
| 使用ANY|SOME或者ALL的子查询 | 需要配合比较运算符 =相当于IN,<>相当于NOT IN |
#由[NOT] IN引发的子查询
SELECT id FROM department;
SELECT id,username FROM employee WHERE depId IN(1,2,3,4);
SELECT id,username FROM employee WHERE depId IN(SELECT id FROM department);
#比较运算符
SELECT level FROM scholarship WHERE id=1;
SELECT id,username FROM student WHERE score>=90;
SELECT id,username FROM student WHERE score>=(SELECT level FROM scholarship WHERE id=1);
#使用[NOT]EXISTS的子查询
SELECT * FROM department WHERE id=5;
SELECT id,username FROM employee WHERE EXISTS(SELECT * FROM department WHERE id=5);#没有id=5
SELECT id,username FROM employee WHERE EXISTS(SELECT * FROM department WHERE id=4);
#使用ANY\|SOME或者ALL的子查询
-- 查询所有获得奖学金的学员
SELECT id,username,score FROM student WHERE score>=ANY(SELECT level FROM scholarship);
SELECT id,username,score FROM student WHERE score>=SOME(SELECT level FROM scholarship);
-- 查询所有学员中获得一等奖学金的学员
SELECT id,username,score FROM student WHERE score >=ALL(SELECT level FROM scholarship);
-- 查询学员表中没有获得奖学金的学员
SELECT id,username,score FROM student WHERE score<ALL(SELECT level FROM scholarship);
| 写入查询结果 | 代码 | 说明 |
|---|---|---|
| 插入查询结果 | INSERT [INTO] tbl_name [(字段名称1,…)] SELECT 另一张表的字段名称1,… FROM 另一张表; | 导入字段需要对应位置 |
| 创建数据表同时将查询结果写入到数据表 | CREATE TABLE [IF NOT EXISTS] tbl_name( 字段名称1… )另一张表的字段名称1,… FROM 另一张表; | 需要导入的字段名称要与原表中的一致,不一致要用AS起同名,否则就会增加字段 |
正则表达式
| 模式字符 | 含义 | 代码示例 | :说明 |
|---|---|---|---|
| ^ | 匹配字符开始的部分 | WHERE username REGEXP ‘^t’ | 不区分大小写,下都同 |
| $ | 匹配字符串结尾的部分 | WHERE username REGEXP ‘g$’ | 同上 |
| . | 代表任意字符 | WHERE username REGEXP ‘r…g’; | 类似LIKE 中的_ |
| [字符集合] | 匹配字符集合中的任意一个字符 | WHERE username REGEXP ‘[lto]’ | 字符集中字符匹配上一个即可 |
| [^字符集合] | 匹配除了字符集合以外的任意一个字符 | WHERE username REGEXP '[^lto] | 还可用[a-k]表示a到k的字符 |
| S1|S2|S3 | 匹配S1,S2,S3中任意一个子字符串 | WHERE username REGEXP ‘ng|qu’ | |
| * | 表示0个1个或者多个*前出现的字符 | WHERE username REGEXP ‘que*’ | *前字符是指e不是que |
| + | 表示1个或者多个+前出现的字符 | WHERE username REGEXP ‘que+’ | 至少要出现1次+同上 |
| String{N} | {}前的字符至少出现N次 | WHERE username REGEXP ‘que{3}’ | {}前字符是指e不是que |
| String{M,N} | {}前的字符至少出现M次,最多出现N次 | WHERE username REGEXP ‘que{1,3}’ | 同上 |
更多可参考链接
运算符
可放在字段名中
算数运算符
能实现字符的自动转换

比较运算符
得到的结果只有真or假,1为真,0为假

逻辑运算
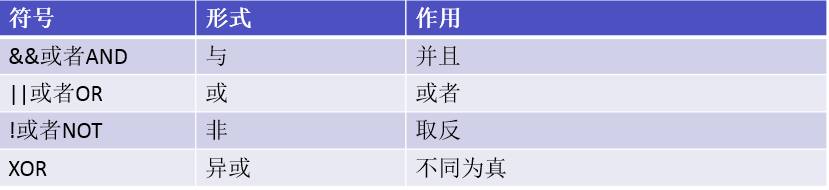


运算符的优先级
可以通过括号()改变优先级

MySQL中的函数
数学函数
















 9517
9517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









