






 文章介绍了如何使用Python库pdfplumber和pandas从PDF文件中提取单词和释义,通过定义函数处理不正常行和正常行,最终实现单词数据的提取和整合。
文章介绍了如何使用Python库pdfplumber和pandas从PDF文件中提取单词和释义,通过定义函数处理不正常行和正常行,最终实现单词数据的提取和整合。
pdf提取:链接:https://pan.baidu.com/s/1jEXQ7Z1UzSgwgxOSBeIZog
提取码:acqz
–来自百度网盘超级会员V6的分享
python库安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pdfplumber
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
前言
最近看到一份3500单词的PDF文件,用Python将它处理一下,把里面的单词与意思提炼出来,然后可以按照自己想编排的顺序编排单词,最终可以导出属于自己的单词本。
一、原始数据
环境配置的话,python版本随意,用到两个主要的库,pdfplumber, pandas。
打开12345.pdf这个文件可以看到1-35页都是两栏排版,而且每一页中会有不同数量的单词的拓展词汇或释义占一栏的两行,也就是说在某些行中会出现只有中文释义+单词的情况,这里将这种行定义为“不正常行”,否则为正常行。但我们需要抓住一个最突出的特征就是每一个单词后面都跟着一个音标,那么正常行会有两组’[]‘,而不正常行只有一组’[]',利用这个特征就可以很方便的对该PDF单词本的单词及释义进行提取。
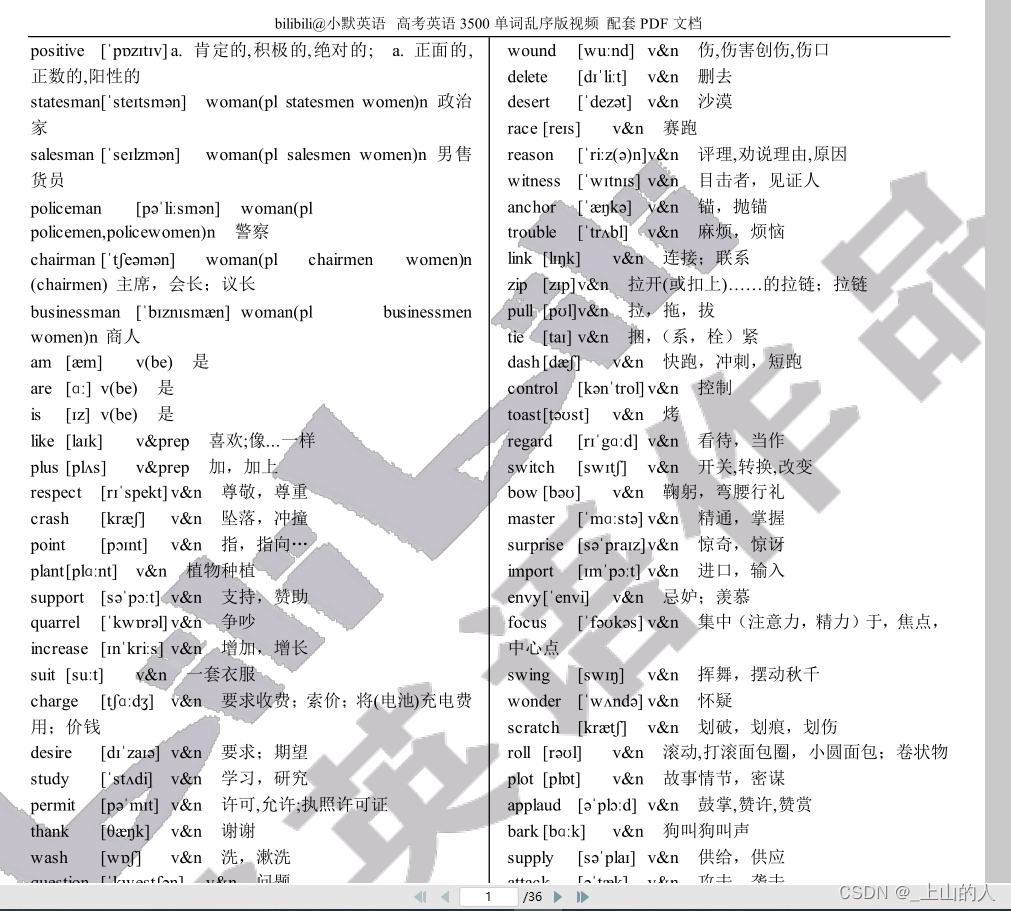
二、具体操作
1.引入库
代码如下(示例):
import pdfplumber
import pandas as pd
2.定义函数
这里需要定义几个后面步骤需要用到的函数
代码如下(示例):
def is_Chinese(word):#判断字符是否为汉字
for ch in word:
if '\u4e00' > ch or ch > '\u9fff':
return False
return True
#在h中查找num字符,并返回其下标
def find_integer(h,num):
k=[]
for i in range(len(h)):
if h[i]==num:
k.append(i)
return k
3.数据读取
a=[]#创建一个空列表,用于存储每页的单词数据,因为这里是按页读取的
with pdfplumber.open("123456.pdf") as pdf:
for page in pdf.pages:
text = page.extract_text()#提取文本
a.append(text)
print(a)
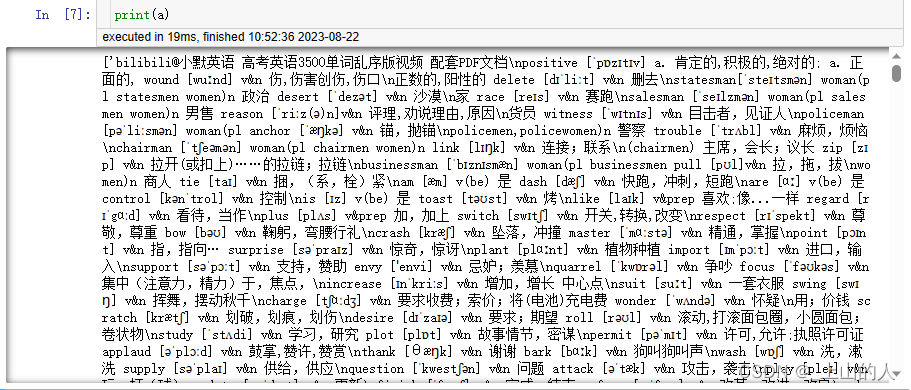 这里我们可以看一下a[0], a[1]的内容以及a的长度,a[0],a[1]分别为第一页和第二页的数据,a的长度为36,说明数据提取正确,没有遗漏。同时注意到每一行的结尾都有一个’\n’字符,所以后续可以用这个字符作为标志,对每一行进行划分。
这里我们可以看一下a[0], a[1]的内容以及a的长度,a[0],a[1]分别为第一页和第二页的数据,a的长度为36,说明数据提取正确,没有遗漏。同时注意到每一行的结尾都有一个’\n’字符,所以后续可以用这个字符作为标志,对每一行进行划分。
len(a)
a[0]
a[1]


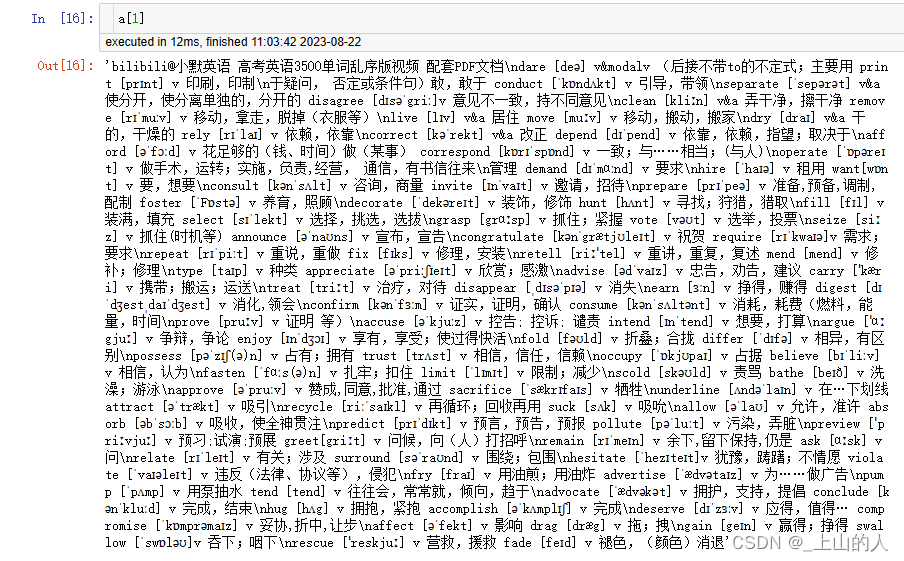
4.对每一行进行划分
先对第一页的单词进行提取,后续可以将提取第一页单词的操作写一个循环。运行下面代码后可以得到下图的结果
#每一行进行分隔
p=a[0]#将第一页的数据提取出来
u=['']#创建一个数组,第一个元素为空字符
k=''#空字符
o=''#空字符
b=0
for i in range(len(p)):
o=o+p[i]#将第i个字符加到字符后
if p[i]=='\n':#用于判断是否遇到回车符
u[b]=u[b]+o#将o添加到数组u的最后一个空字符串元素中
u.append(k)#在u后面增加一个空字符串元素
b=b+1#行索引加1
o=''#清空o
if i==len(p)-1:
u[b]=u[b]+o
#u.append(k)
u=u[1:]
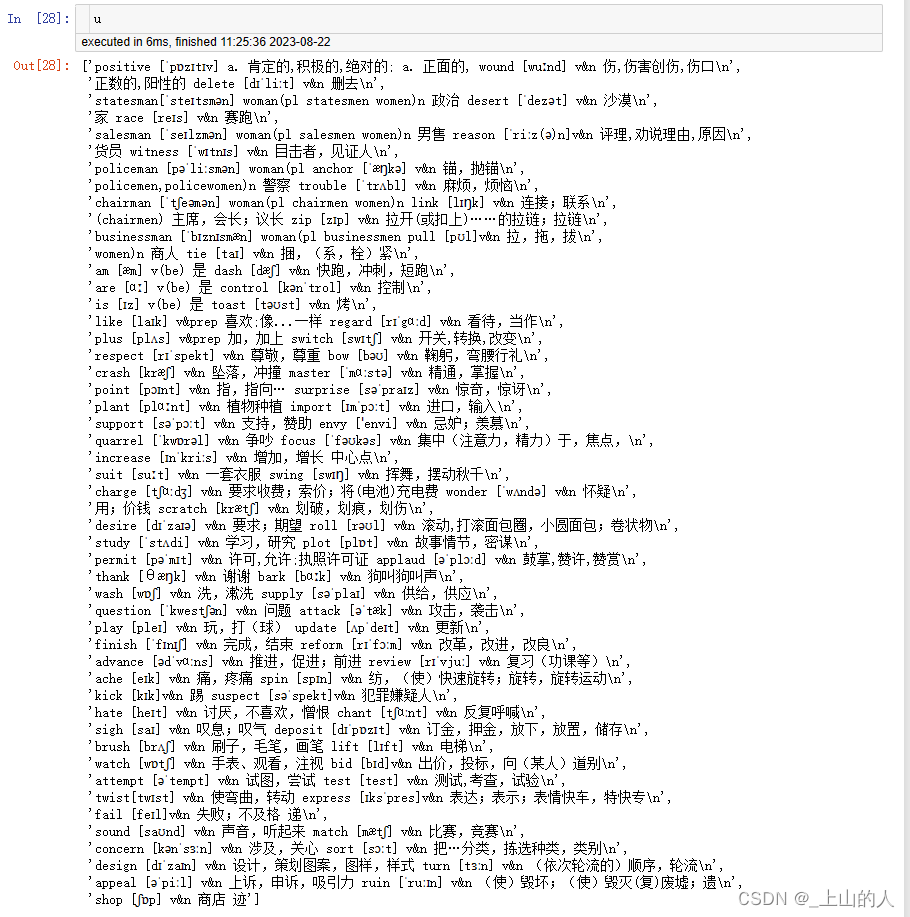
5.不正常行的提取
对前面定义的不正常行进行提取并分割,这里首先要确定哪些是正常行,哪些不是正常行,代码如下:
#计算每一行中'['与']'的总数,总数为4的为正常行,总数为2的为不正常行
kk=[]
for i in range(len(u)):
x=0
for j in range(len(u[i])):
if u[i][j]==u[1][15] or u[i][j]==u[1][23]:
x=x+1
kk.append(x)

如图所示,2为不正常行。进行分割,代码如下:
#对不对称的进行分割
oo=[]
zz=[]
for i in range(len(u)):
if kk[i]==2:
qq=''
for j in range(len(u[i])):
qq=qq+u[i][j]
if j<len(u[i])-1:
if (is_Chinese(u[i][j]) and u[i][j+1]==' ') or (u[i][j]==')' and u[i][j+1]==' ') or (u[i][j]==')' and u[i][j+1]==' '):
oo.append(qq)
qq=''
zz.append(qq)
yy_=zz#存储右边栏的不正常行字符
zz_=oo#存储左边栏的不正常行字符
输出结果:

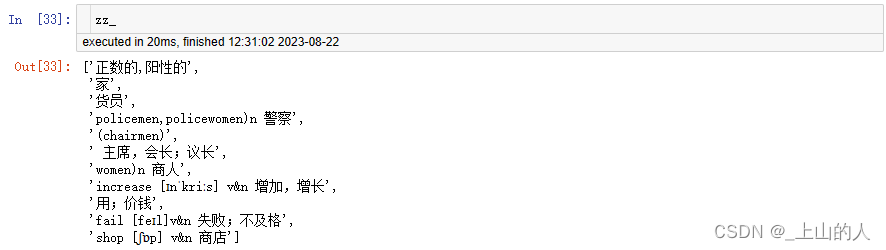
6.对正常行进行划分
正常行进行划分主要找出每一行左右栏的分割标志,代码如下:
yy_all=[]
zz_all=[]
for i in range(len(u)):
if kk[i]==4:
x_=0
m=0
for j in range(len(u[i])):
if u[i][j]==biaoshi1 or u[i][j]==biaoshi2:
x_=x_+1
if x_==3:
m=j-1
break
while (u[i][m]==' 'and (ord(u[i][m-1])<=122 and ord(u[i][m-1])>=65)) or ((ord(u[i][m-1])<=122 and ord(u[i][m-1])>=65) and (ord(u[i][m-1])<=122 and ord(u[i][m-1])>=65)):
m=m-1
m=m-1
qq=''
for j in range(len(u[i])):
qq=qq+u[i][j]
if j==m:
zz_all.append(qq)
qq=''
yy_all.append(qq)
输出结果如下:
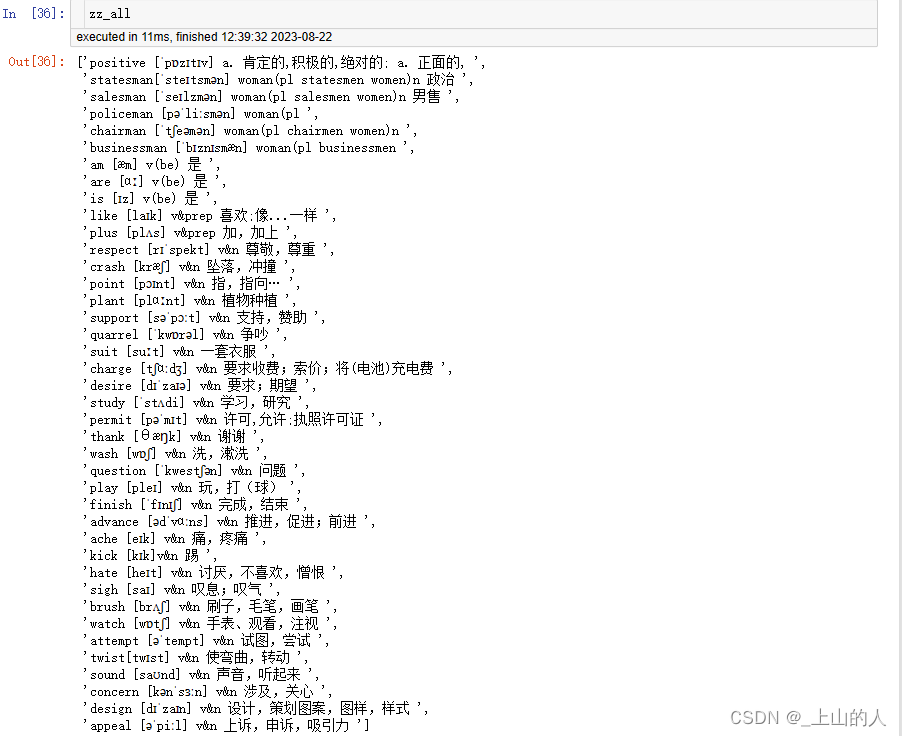

7.不正常行与正常行的融合
需要生成左栏单词和右栏单词,对不正常行和正常行数据进行融合,代码如下:
index1=[]
index2=[]
zzz=zz_all
yyy=yy_all
aa=0
bb=0
kli=0
mk=0
mkk=0
for i in range(len(kk)):
if kk[i]==4 and kk[i+1]==2:
index1.append(i)
for i in range(len(kk)):
if kk[i]==4:
index2.append(i)
#对左栏的正常行与不正常行进行融合
for i in range(len(index1)):
pp1=find_integer(index2,index1[i])
x_=0
for j in range(len(zz_[aa])):
if zz_[aa][j]==u[1][15] or zz_[aa][j]==u[1][23]:
x_=x_+1
if x_!=2:
zzz[pp1[0]+mk]=zzz[pp1[0]+mk]+zz_[aa]
aa=aa+1
if x_==2:
zzz.insert(pp1[0]+mk+1,zz_[aa])
aa=aa+1
mk=mk+1
输出结果如下:
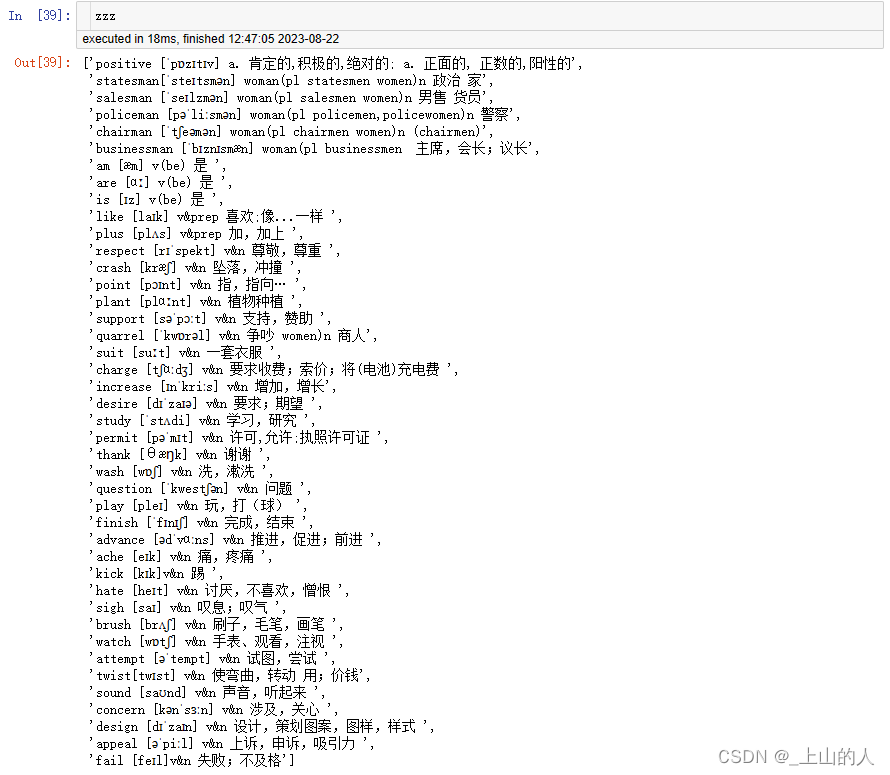
#对右栏正常行与不正常行进行融合
for i in range(len(index1)):
pp1=find_integer(index2,index1[i])
xx_=0
if len(yy_)!=0:
for j in range(len(yy_[bb])):
if yy_[bb][j]==biaoshi1 or yy_[bb][j]==biaoshi2:
xx_=xx_+1
if xx_!=2:
yyy[pp1[0]+mkk]=yyy[pp1[0]+mkk]+yy_[bb]
bb=bb+1
if xx_==2:
yyy.insert(pp1[0]+mkk+1,yy_[bb])
bb=bb+1
mkk=mkk+1
这样可以输出第一页进行重新排版后,所有的左栏单词和右栏单词数据
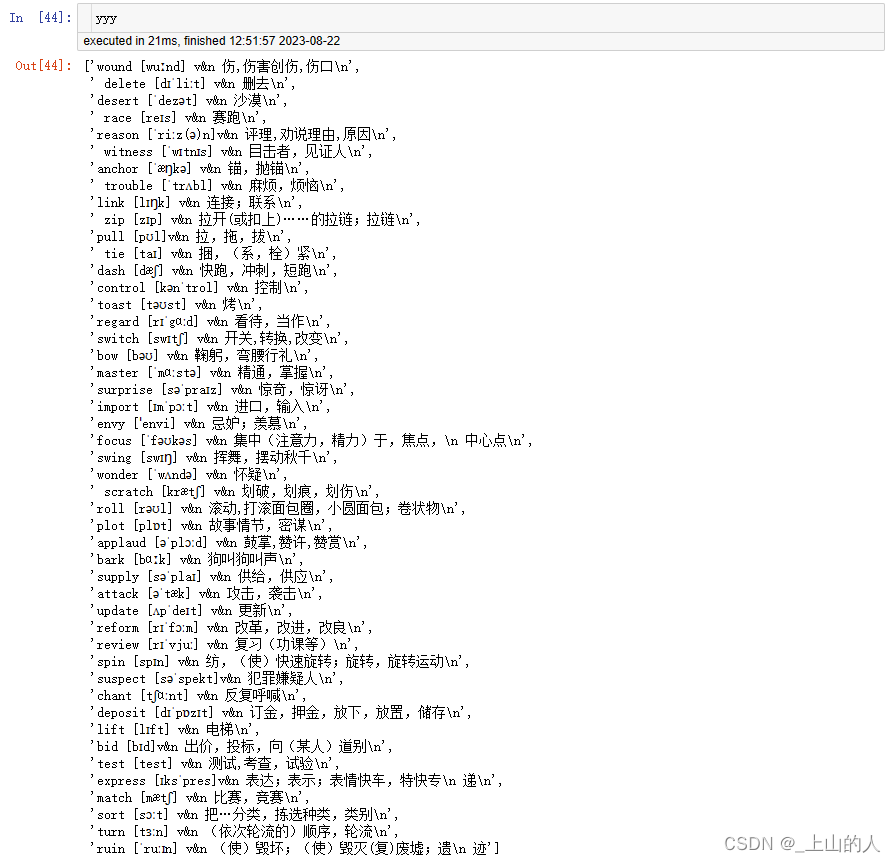
然后对右栏数据进行微调:
for i in range(len(yyy)):
yyy[i]=yyy[i].replace('\n','')
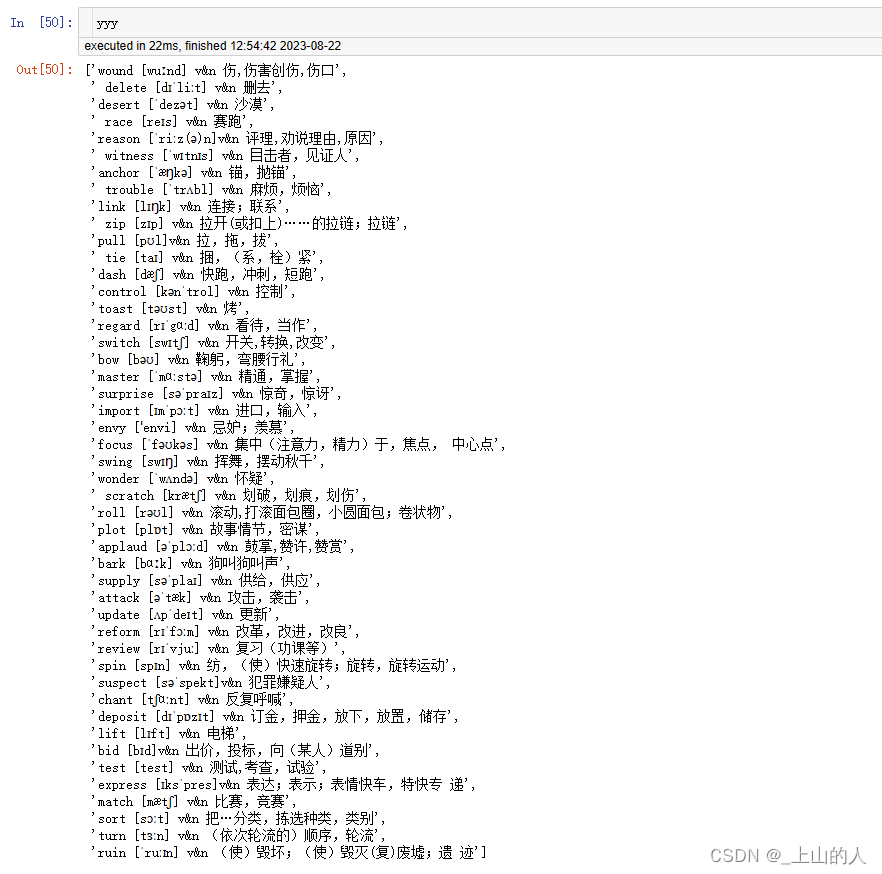
8.小结
这里通过对第一页数据进行提取,成功将每个单词的拼写,发音,词性,拓展,释义都提取至数组中的一个字符串元素,可以方便后续进行操作。
三.1-35行数据提取与处理
通过提取第一页数据,可以得到我们想要的相关信息,根据同样的道理,写一个循环就可以得到1-35页。代码如下:
#主文件程序main
#读取数据
biaoshi1=u[1][15]
biaoshi2=u[1][23]
a=[]
azz=[]
ayy=[]
with pdfplumber.open("123456.pdf") as pdf:
for page in pdf.pages:
text = page.extract_text()#提取文本
a.append(text)
#print(text)
for hhhhh in range(len(a)):
#每一行进行分隔
p=a[hhhhh]
u=['']
k=''
o=''
b=0
for i in range(len(p)):
o=o+p[i]
if p[i]=='\n':
u[b]=u[b]+o
u.append(k)
b=b+1
o=''
if i==len(p)-1:
u[b]=u[b]+o
#u.append(k)
u=u[1:]
#区分出一个单词占一行还是占一列
#kk为4时为单词和释义在同一行,kk为2时单词和释义不在同一行需要进行处理
kk=[]
for i in range(len(u)):
x=0
for j in range(len(u[i])):
if u[i][j]==biaoshi1 or u[i][j]==biaoshi2:
x=x+1
kk.append(x)
#对不对称的进行分割
oo=[]
zz=[]
for i in range(len(u)):
if kk[i]==2:
qq=''
for j in range(len(u[i])):
qq=qq+u[i][j]
if j<len(u[i])-1:
if (is_Chinese(u[i][j]) and u[i][j+1]==' ') or (u[i][j]==')' and u[i][j+1]==' ') or (u[i][j]==')' and u[i][j+1]==' '):
oo.append(qq)
qq=''
zz.append(qq)
yy_=zz
zz_=oo
#对正常行进行分割
yy_all=[]
zz_all=[]
for i in range(len(u)):
if kk[i]==4:
x_=0
m=0
for j in range(len(u[i])):
if u[i][j]==biaoshi1 or u[i][j]==biaoshi2:
x_=x_+1
if x_==3:
m=j-1
break
while (u[i][m]==' 'and (ord(u[i][m-1])<=122 and ord(u[i][m-1])>=65)) or ((ord(u[i][m-1])<=122 and ord(u[i][m-1])>=65) and (ord(u[i][m-1])<=122 and ord(u[i][m-1])>=65)):
m=m-1
m=m-1
qq=''
for j in range(len(u[i])):
qq=qq+u[i][j]
if j==m:
zz_all.append(qq)
qq=''
yy_all.append(qq)
index1=[]
index2=[]
zzz=zz_all
yyy=yy_all
aa=0
bb=0
kli=0
mk=0
mkk=0
for i in range(len(kk)-1):
if kk[i]==4 and kk[i+1]==2:
index1.append(i)
for i in range(len(kk)):
if kk[i]==4:
index2.append(i)
for i in range(len(index1)):
pp1=find_integer(index2,index1[i])
x_=0
if len(zz_)!=0:
for j in range(len(zz_[aa])):
if zz_[aa][j]==biaoshi1 or zz_[aa][j]==biaoshi2:
x_=x_+1
if x_!=2:
zzz[pp1[0]+mk]=zzz[pp1[0]+mk]+zz_[aa]
aa=aa+1
if x_==2:
zzz.insert(pp1[0]+mk+1,zz_[aa])
aa=aa+1
mk=mk+1
print(hhhhh)
#对右边部分进行调整与处理
for i in range(len(index1)):
pp1=find_integer(index2,index1[i])
xx_=0
if len(yy_)!=0:
for j in range(len(yy_[bb])):
if yy_[bb][j]==biaoshi1 or yy_[bb][j]==biaoshi2:
xx_=xx_+1
if xx_!=2:
yyy[pp1[0]+mkk]=yyy[pp1[0]+mkk]+yy_[bb]
bb=bb+1
if xx_==2:
yyy.insert(pp1[0]+mkk+1,yy_[bb])
bb=bb+1
mkk=mkk+1
#去掉右边列的回车符号
for i in range(len(yyy)):
yyy[i]=yyy[i].replace('\n','')
azz.append(zzz)
ayy.append(yyy)
这里需要注意第一、二行的biaoshi1=u[1][15],biaoshi2=u[1][23],这里需要先将提取第一页的程序运行一边,然后再将第一页提取出来的u[1]15和u[1]23赋值给biaoshi1和biaoshi2,因为常规的’[‘,’]'会出错。
会打印如下结果:
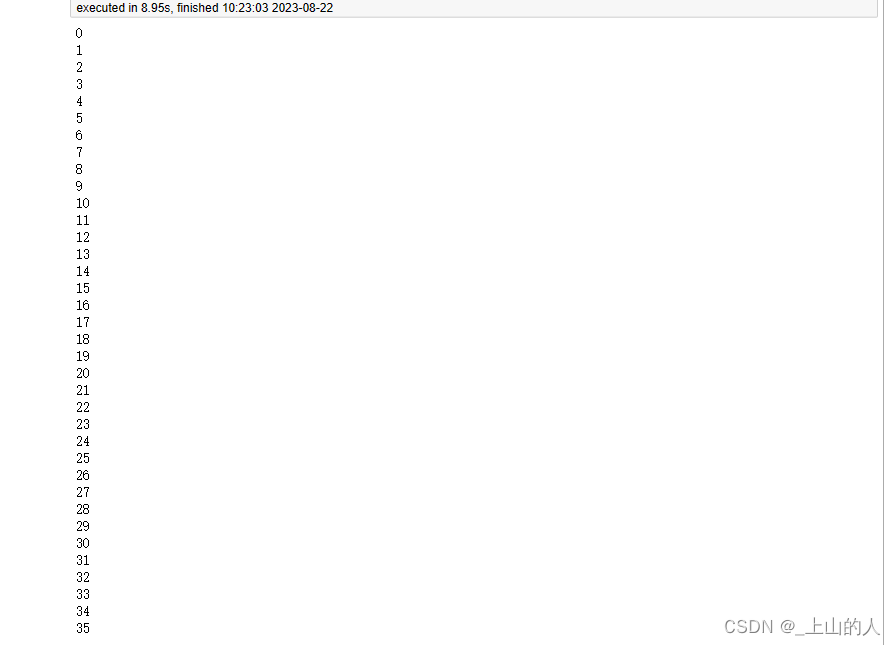
说明1-35所有数据都提取成功。
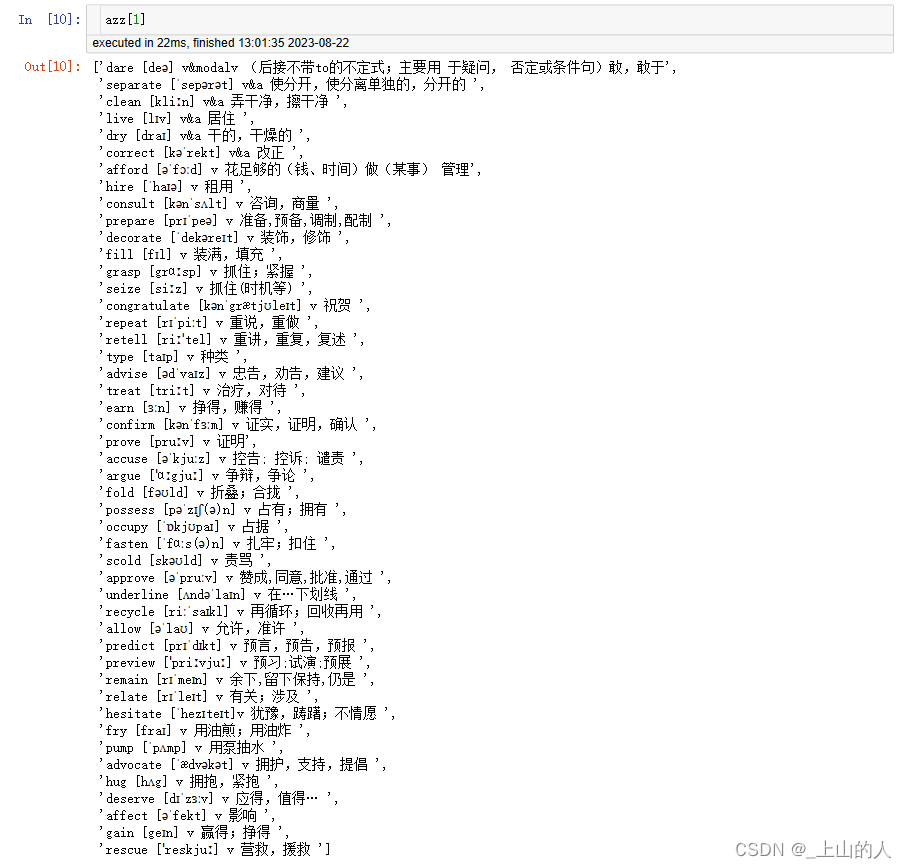
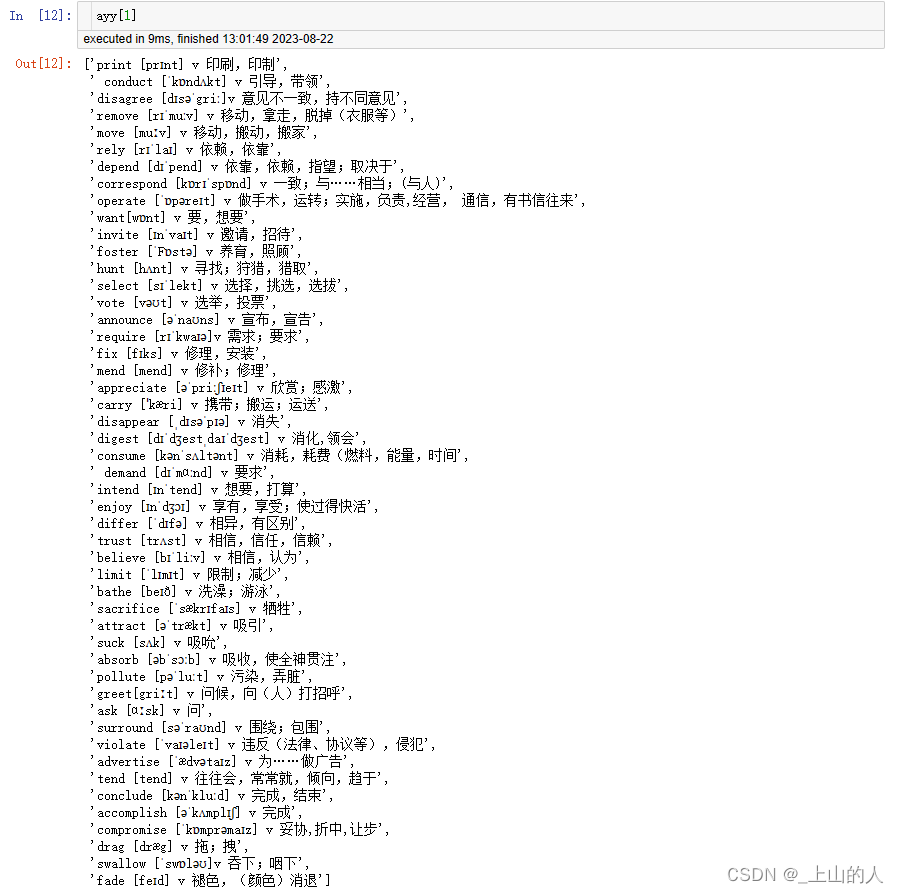
PDF中第二页的单词如下:

说明打印正确。
总结
本文简单的对一个pdf中的单词数据进行提取,但并没有进行单词顺序重构,单词后缀、词性的归类,这些工作可以留给各位亲爱的读者去完成,这样自己就能够根据不同的分类方法或者顺序构建自己的单词记忆库。此文章中的代码均为原创,代码的一些逻辑由于时间原因没有详细注释,不过这都是我经过debug的,当最后能够输出1-35时,说明代码没有问题,且数据提取正确。各位大佬觉得还可以就支持一下python小白,点个赞!收藏!加关注!非常感谢。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









