







文章目录
一、RNN(循环神经网络)
1.1 了解人的记忆原理
人脑在受到语言刺激的时候,对后续的字、词、句具有预测功能。从生物神经网络的角度来理解,大脑中的语言模型在某一场景下对当前所输入的信息是有先后顺序区分的。
我们的大脑并不是简单的数据存储,而是链式的、有顺序的存储。 这种存储很节省空间,对于中间状态的序列,我们的大脑并没有选择直接记住,而是存储了计算方法。当我们需要取值时,直接将具体的数据输入,通过计算获得相应的结果。
举个例子来说,当大脑获得“我爱天安”的信息后,大脑的语言模型会自动预测后一个字为“门”,而不是“全、静”等字。

上图中的处理逻辑并不是说完“我爱天安"之后进入大脑来处理,而是每个字都在脑子里进行着处理,将每个字分别裁开,在语言模型中就形成了一个循环神经网络。

1.2 RNN原理及运行过程
在传统的神经网络中,我们假设所有的输入(包括输出)之间是相互独立的。对于很多任务来说,这样做的结果并不好。比如你想预测一个序列中的下一个词,你最好能知道哪些词在它前面。RNN之所以循环的,是因为它针对系列中的每一个元素。都执行相同的操作,每一个操作都依赖于之前的计算结果。
换一种方式思考,可以认为RNN记忆了到当前为止已经计算过的信息。理论上RNN可以利用任意长的序列信息,但实际中只能回顾之前的几步。

▶ U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层权重矩阵,权重矩阵W就是隐藏层上一次的值作为这一次的输入的权重。RNN在所有时刻中共享相同的参数U、V、W。 这反映了在每一步中都在执行相同的任务,只是用了不同的输入。这极大地减少了需要学习到参数的个数。
▶ Xt是t时刻的输入,例如,Xt是句子中第二个词的one-hot编码向量。一个箭头表示对该向量做一次变换。
▶ St是对应t时刻隐藏状态,是网络的记忆单元。St通过前一步的隐藏状态和当前状态的输入得到:St = f(U Xt + W St-1), 例如tanh和ReLU. St-1 通常用来计算第一个隐藏状态,会被0全部初始化。
▶ Ot是t时刻的输出。例如,如果想要预测句子中的下一个词,那么它就是会包含词表中所有词的一个概率向量, Ot = softmax(V St).
▶ RNN可以被看做是同一神经网络的多次赋值,每个神经网络模块会把消息传递给下一个。上一次提取的输出特征和当前层的输入一起输入到当前网络,从而影响当前层的输出结果。
1.3 RNN的多种结构
N-to-N
假设输入为X=(x1, x2, x3, x4),每个x是一个单词的词向量。
为了建模序列问题,RNN引入了隐状态h(hidden state)的概念,h可以对序列形状的数据提取特征,接着再转换为输出。先从h1的计算开始看:

h2的计算和h1类似。要注意的是,在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点,一定要牢记。

依次计算剩下来的(使用相同的参数U,W,b)

这里为了方便起见,只画出序列长度为4的情况,实际上,这个计算过程可以无限地持续下去。得到输出值的方法就是直接通过h进行计算:

正如之前所说,一个箭头就表示对对应的向量做一次类似于f(Wx+b)的变换,这里的这个箭头就表示对h1进行一次变换,得到输出y1。剩下的输出类似进行(使用和y1同样的参数V和c):

这就是最经典的RNN结构,它的输入是x1, x2, ……xn,输出为y1, y2, …yn,也就是说,输入和输出序列必须要是等长的。由于这个限制的存在,经典RNN的适用范围比较小,但也有一些问题适合用经典的RNN结构建模,如:
计算视频中每一帧的分类标签。因为要对每一帧进行计算,因此输入和输出序列等长。输入为字符,输出为下一个字符的概率。这就是著名的Char RNN,Char RNN可以用来生成文章,诗歌,甚至是代码,非常有意思)。
N-to-One
处理的问题输入是一个序列,输出是一个单独的值而不是序列,应该怎样建模呢?实际上,我们只在最后一个h上进行输出变换就可以了:

应用:这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段视频并判断它的类别等等。
One-to-N
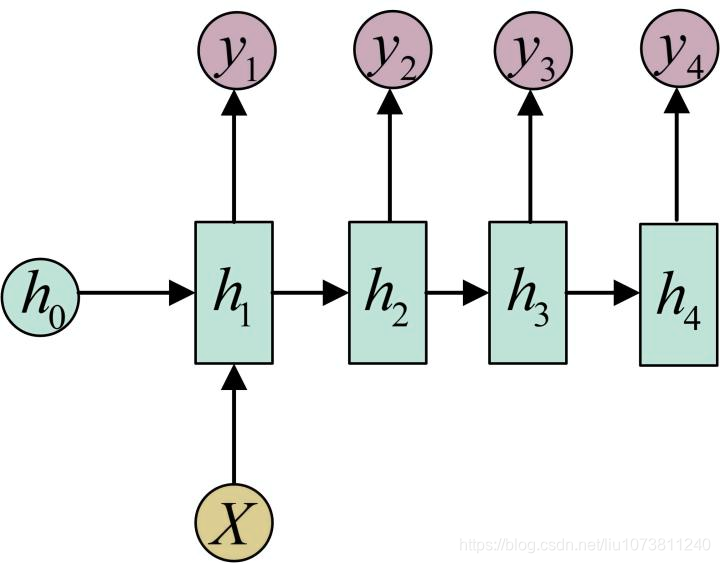
还有一种结构是把输入信息X作为每个阶段的输入:

下图省略了一些X的圆圈,是一个等价表示:

应用:
从图像生成文字(image caption),此时输入的X就是图像的特征,而输出的y序列就是一段句子,就像看图说话等从类别生成语音或音乐等.
1.4 RNN网络的训练
训练RNN和训练传统神经网络相似,同样要使用反向传播算法,但会有一些变化。因为参数在网络的所有时刻是共享的,每一次的梯度输出不仅依赖于当前时刻的计算结果,也依赖于之前所有时刻的计算结果。例如,为了计算t=4时刻的梯度,需要反向传播3步,并把前面的所有梯度加和。这被称作随时间的反向传播(BPTT)。
普通用BPTT训练的RNN对于学习,长期依赖(相距很长时间的依赖)是很困难的,因为这里存在梯度消失或爆炸问题。当然也存在一些机制来解决这些问题,特定类型的RNN(如LSTM)就是专门设计来解决这些问题的。

1.5 RNN和CNN的比较
相同点
- 传统神经网络的扩展
- 前向计算产生结果,反向计算模型更新。
- 每层神经网络横向可以与多个神经元共存,纵向可以有多层神经神经网络连接。
不同点
-
CNN空间扩展,神经元与特征卷积;RNN时间扩展,神经元与多个时间输出计算。
-
RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出。
-
CNN网络层数可以高达1000多层,RNN深度有限。
小结
CNN如同眼睛一样,正是目前机器用来识别对象的图像处理器。相应地,RNN则是用于解析语言模式的数学引擎,就像耳朵和嘴巴。
二、RNN代码实现
github地址:https://github.com/liu1073811240/RNN

















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









