









 本文深入分析HanLP中基于感知机的人名性别预测模块,探讨感知机算法原理及其实现细节,包括模型训练、评估过程及优化方法。
本文深入分析HanLP中基于感知机的人名性别预测模块,探讨感知机算法原理及其实现细节,包括模型训练、评估过程及优化方法。
【Hanlp源码分析】基于感知机实现人名性别预测
本文是分析github中著名的开源NLP工业级代码——hanlp的实现细节,其作者是何晗。
0.总结
Get to the points first. The article comes from LawsonAbs!
- part1:感知机算法简介
- part2:【Hanlp源码分析】基于感知机实现人名性别预测
1.什么是感知机算法?
-
属于监督学习算法
比如在后面给出的实战代码中,我们给出了人名对应的性别,会根据这个预测是否准确去完成一次更新操作。 -
属于迭代式算法
每次读入一个样本,执行预测,将预测结果与正确答案进行对比,计算误差,根据误差更新模型参数。
2.有什么用途?
- 可以用于问题分类
3.有什么利弊?
-
模型过于简单
参数较少的模型就容易出现 “不拟合” 的情况,同时,也会因为数个偏离点而对迭代更新的参数有很大的影响。从而难以准确的预测结果,造成较大偏差。 -
迭代偏差
这里说的迭代偏差是因为我们总是倾向于取最后一次迭代的模型。
每次迭代都产生一个模型,而且每个模型的对应的每个参数不一定相同。如果我们单纯的取最后一次迭代产生的模型作为“最优模型”的话,很有可能是 “补了西墙,拆了东墙”。
3.怎么改进?
针对上面叙述的问题,对应的改进方法有投票感知机和平均感知机,分别简单叙述一下。
3.1 投票感知机
3.1.1 思想
每次迭代都会产生一个不同参数的模型,那么这些模型间的准确率就不一样,把这个准确率称之为权重。根据各个模型的权重可以得到每个模型的加权平均值。根据各个模型的加权平均值与参数相乘,得到最终的一个模型。
3.1.2 缺点
- 计算开销大
- 存储开销大
3.2 平均感知机
3.2.1 思想
每次迭代都会产生一个不同参数的模型,最后得到的模型就取每次迭代模型的一个平均。【这个平均其实指的是模型参数的平均】【《自然语言处理入门》这本书中讲的是:取多个模型权重的平均。我不是很理解。】
3.2.2 特点
- 好实现
- 借助一定的方法【累积参数和,而不是傻傻的每迭代一次就算一次平均】,可以避免存储中间模型,可以以更少内存得到最终的模型
下面开始讲第二部分,分析感知机算法中最简单的【朴素感知机】的代码实现。因为原作者用的是Java,所以会涉及到一些Java的语法知识。后期我会造出 python 版的轮子。
4.主要类
4.1 NameGenderClassification
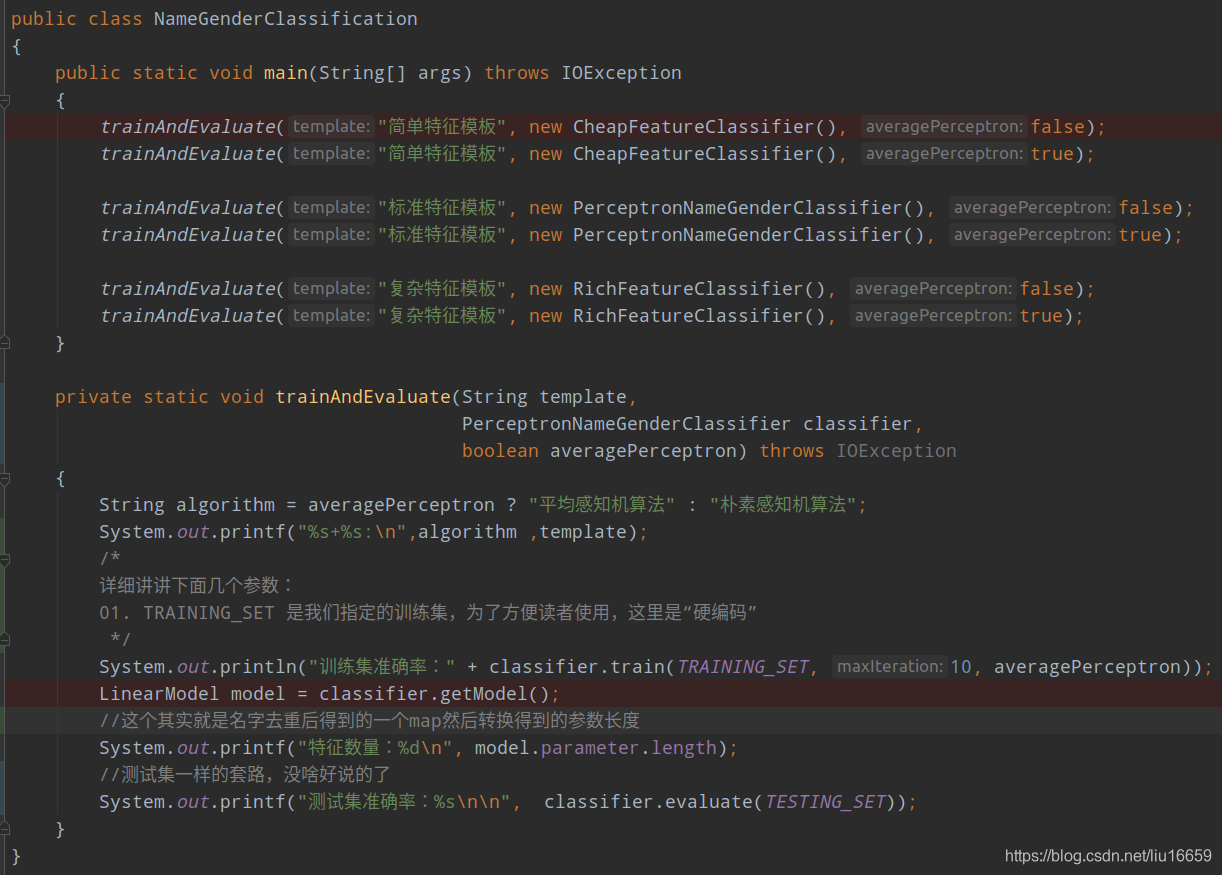
main() 是入口函数, trainAndEvaluate()中会训练模型【classifier.train(…)】,会将得到的模型进行效果评估【classifier.evaluate(…)】。
4.2 PerceptronClassifier
这个抽象类中实现了 上述的 train方法。如下所示:
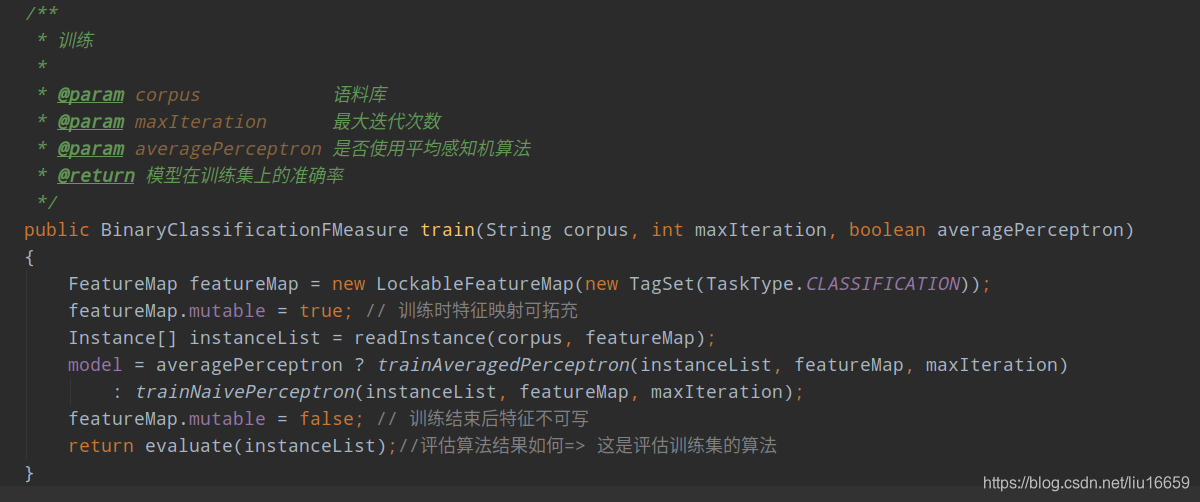
这里主要做了几件事儿:
- 初始化一个特征字典(
featureMap),这个就是将人名中除去姓氏的名字做一个映射。 - 读取语料库【
reandInstance(corpus,featureMap)】
这是很重要的一部分内容,其关键问题是:如何把语料库信息转换为数据信息? 下面慢慢谈。
(1)corpus是语料库的地址,为了便于测试,这里我用了一个自己编辑的语料库做训练集。内容如下:

这里传入featureMap的原因就是因为在读取语料库时 将特征写入Map中。在看如何将语料信息转换为数据信息之前,有必要了解一下 类Instance中的定义,这里的Instance就代表是语料库中的一行数据。
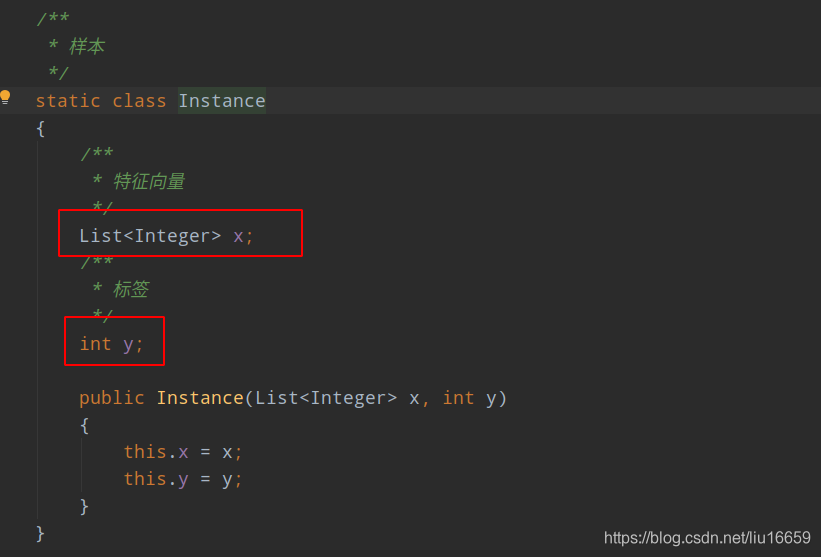
这里的Instance包含两个属性:
(1)特征向量
(2)标签【即应该得到的正确分类结果】
这里的特征向量存在方式很特别。通常的文字转向量采用的编码方式有one-hot编码,但是这里采用的是记录下标的方式。这样做是为了减少内存开销,加速计算。
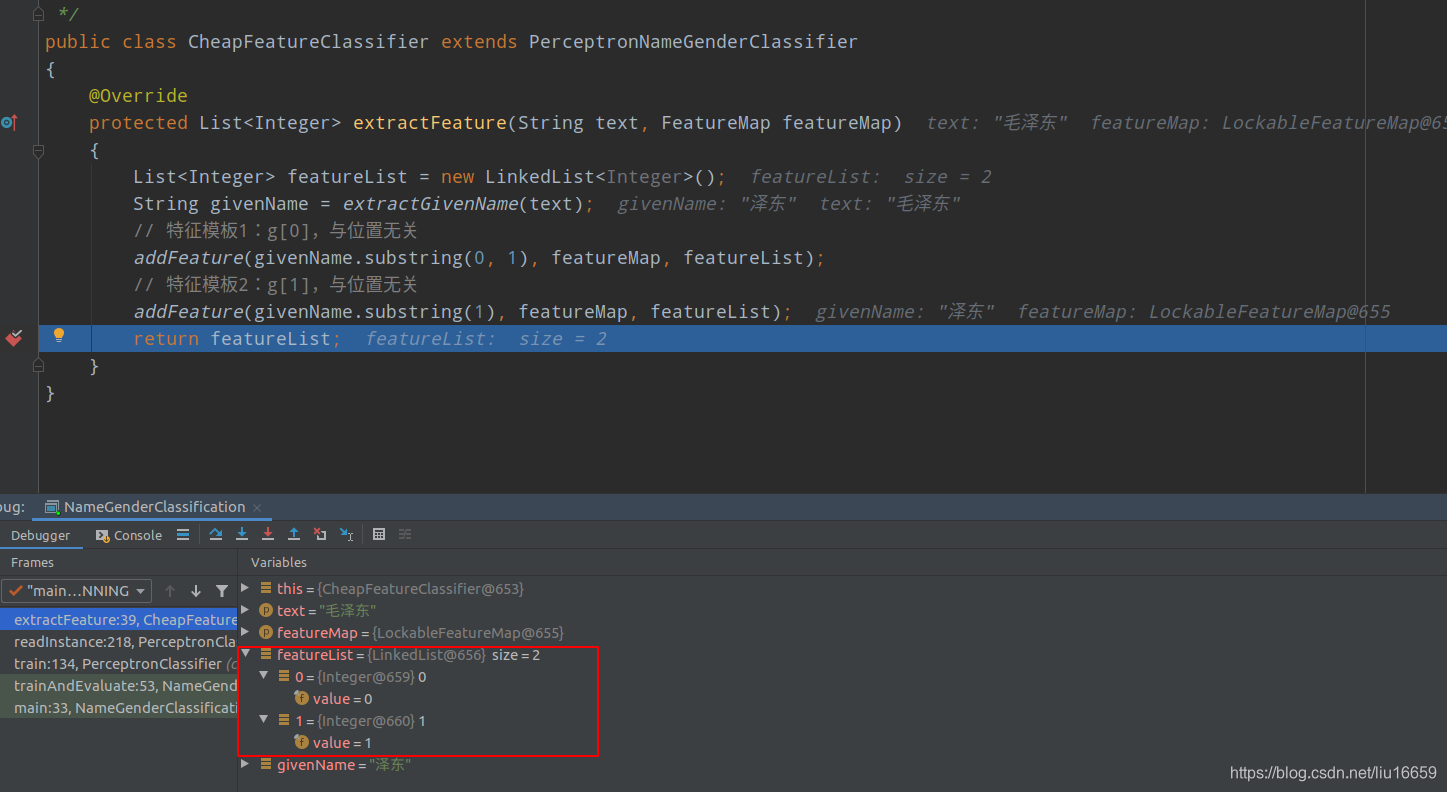
下面我以上面的语料库举个例子:由 “范仲淹,男”这行数据,可以得到一个两个特征=> 仲和淹。因为它们都是第一次出现,所以就直接放到featureMap中,得到的就是0和1,因为范仲淹是男性,所以最终得到的Instance实例就是x=[0,1], y=-1。其中x是一个LinkedList型的对象。
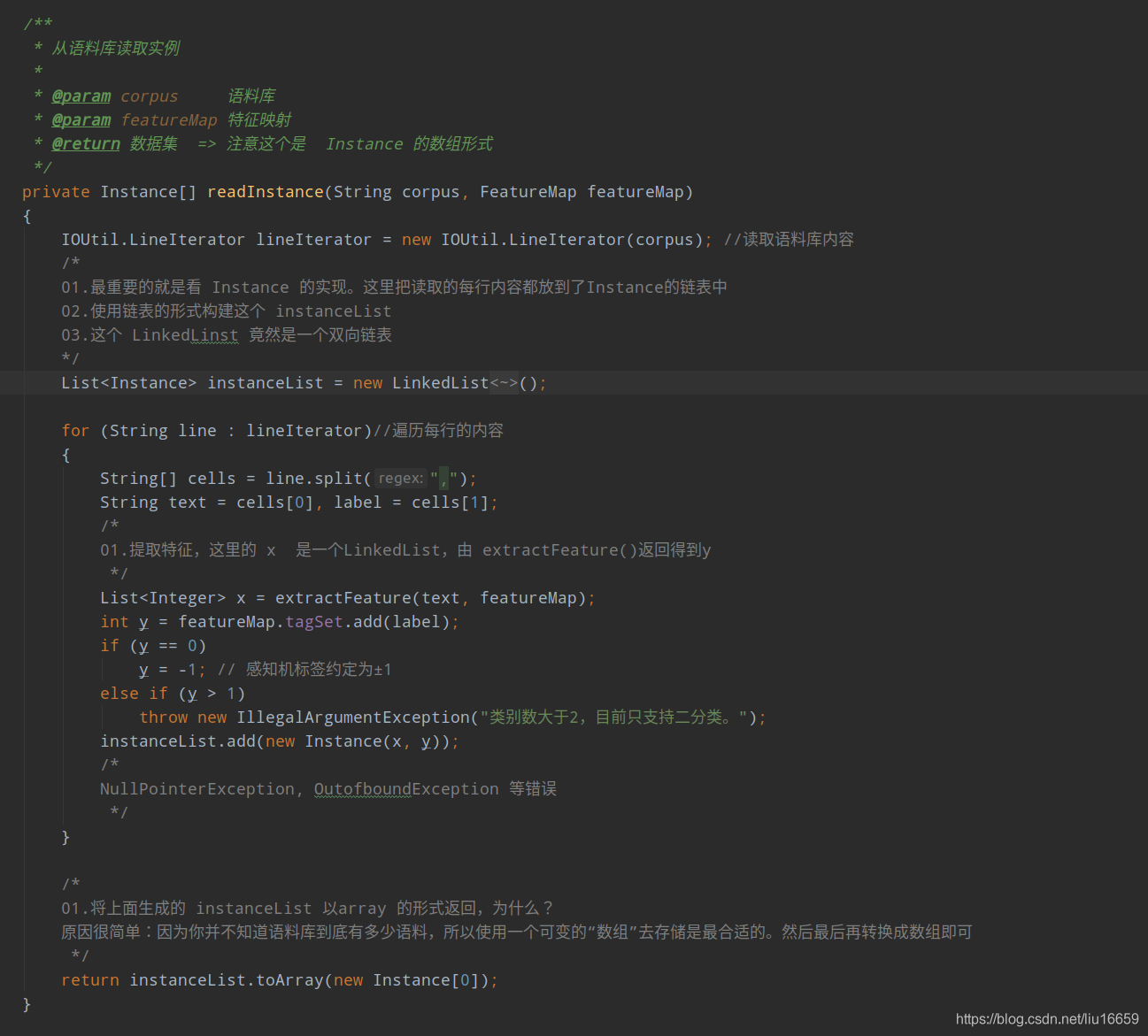
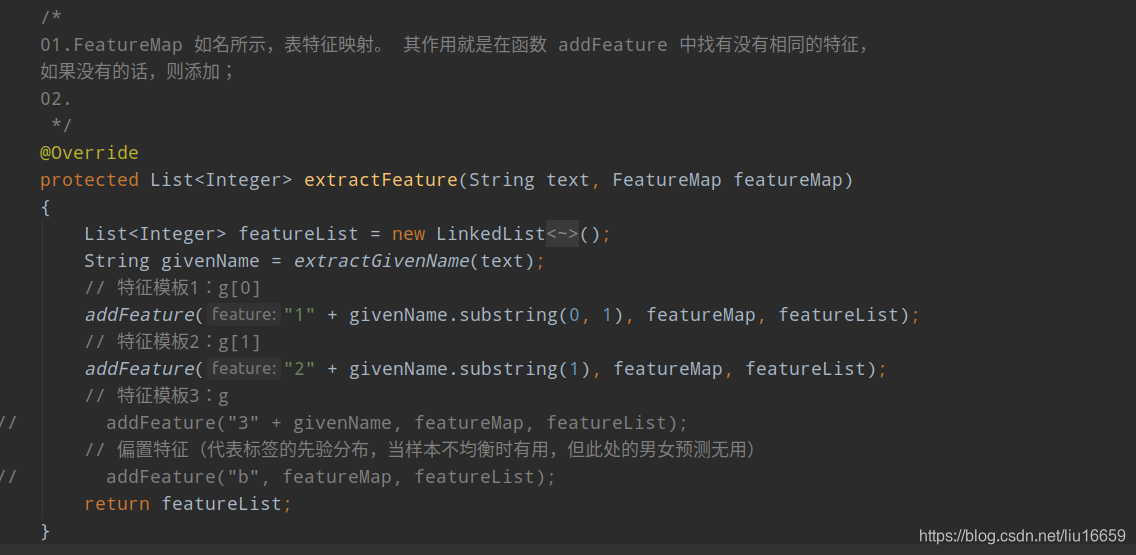
featureList中的值如下所示:仲对应0,淹对应1…后面同样的道理。
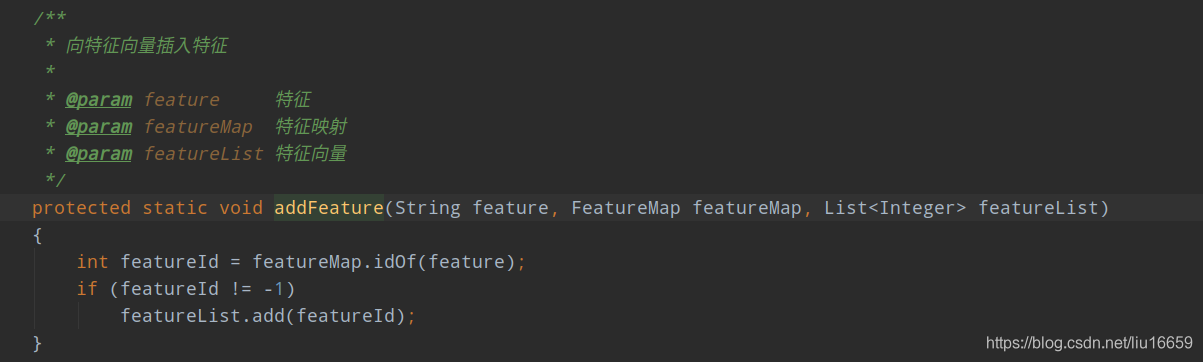
 其中会调用的几个方法如下:
其中会调用的几个方法如下:
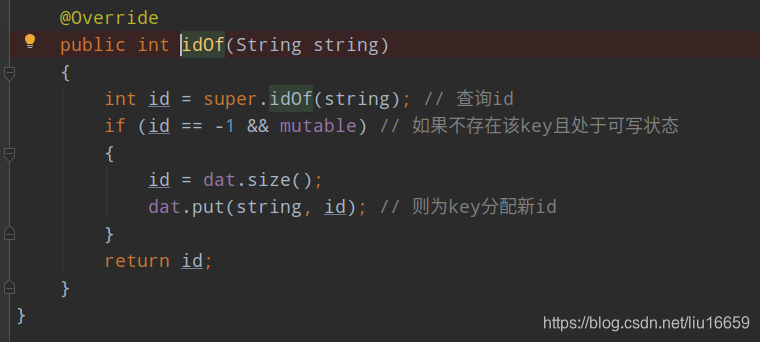
注意到 readInstance 方法返回的是一个 Instance 的数组。如果用Instance[] instArray = new Instance[200]; //直接使用 Instance[] 去直接生成一个数组将显得有写生硬且浪费。
- 根据参数
averagePerceptron选择是进行何种训练方式?我这里就分析朴素感知机,其他的都很相似,除了平均感知机做了一个简单的内存和计算优化,也没啥的。
这里是最主要的内容。下面我们慢慢谈。
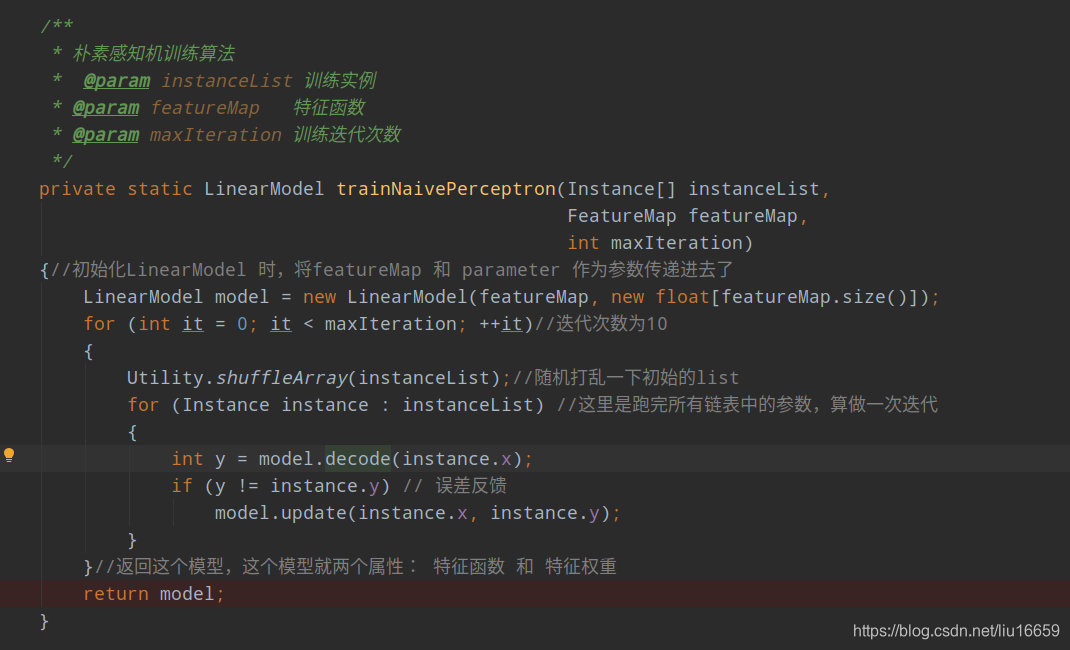 这里的感知机机制就是:
这里的感知机机制就是: y=w*x + b。提炼一下就得到y = wx,因为代码中存储的特征是下标值【其实际含义是:该值下标对应的值为1】,所以直接采用y+=parameter[f]的这种形式就可以得到一个模拟结果。数组parameter[] 的初始值赋为0。代码如下:
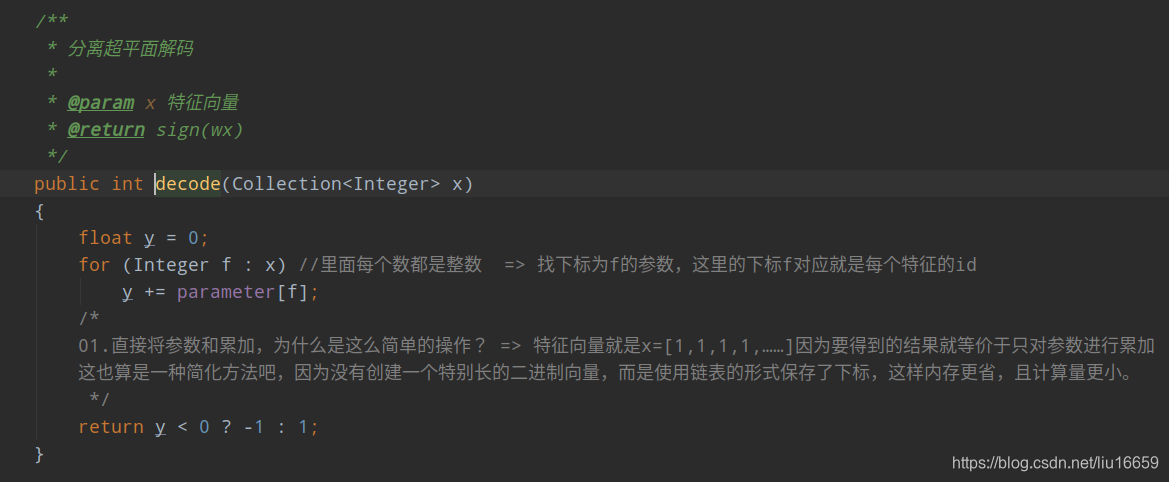 如果预测结果部队,则需要对该预测过程涉及到的参数进行更新:
如果预测结果部队,则需要对该预测过程涉及到的参数进行更新:
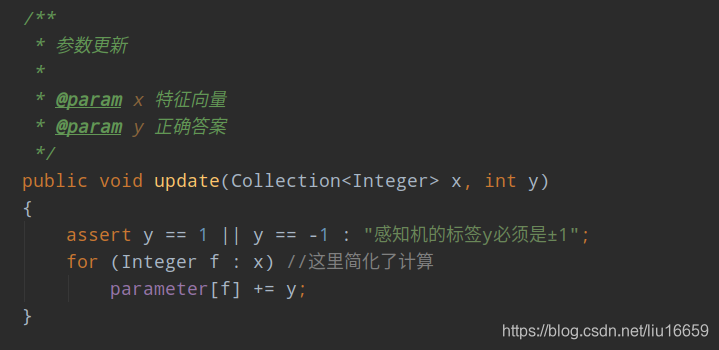
这里的更新过程也是结合了相关的推导进行了简化。因为只有预测错了才会对参数进行更新。分类讨论一下:
当预测结果为-1,而正确结果为1时,因为特征向量x的值不可变,且其恒为正,所以我们可以将w的值变大,从而得到一个更大结果值,所以可以直接进行parameter[f]+=y操作;
相应的,当预测结果为1时,可得到相反的结论。
- 最后评价这个模型的效果【
evaluate(instanceList)】
跑出的结果如下所示:
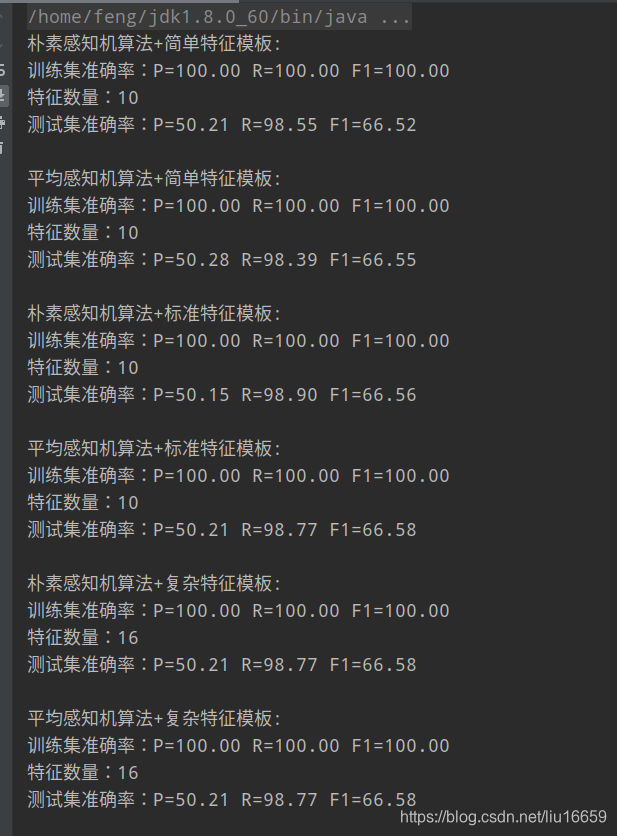
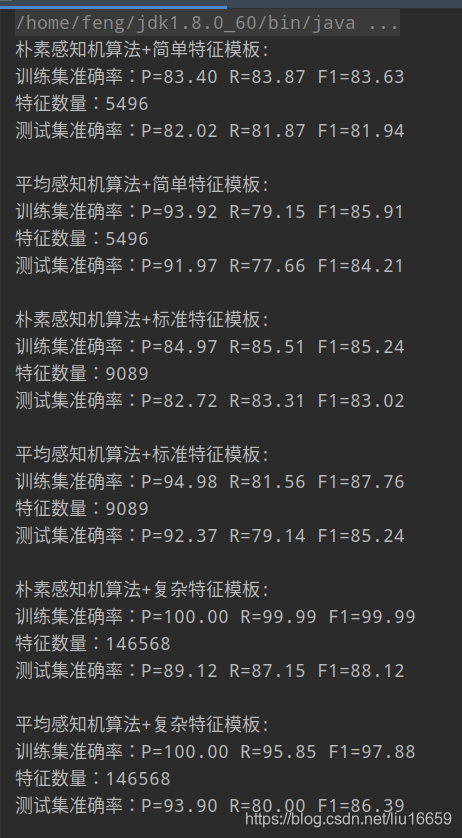
因为训练集合就一点儿数据,所得到的准确率很低,当将训练集换成正常的语料库之后,可以得到一个很好的预测效果:


















 1521
1521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











