







文章目录:
1.1 存储不同类型的数据项,把不同类型的数据结合合成一个整体用来描述某一对象
1.2 struct 语句定义了一个包含多个成员的新的数据类型
2.5 给union的某个成员赋值后,该union的其他成员就变成未定义状态
2.6 同struct一样,联合默认访问权限也是公有的,并且,也具有成员函数
2.7 C++中union类型定义后使用时可以省去union
3.2 用途与定义:若某变量只能取有限几个整数值,把他们一一列举出来定义为枚举类型(限定变量的取值)
3.3 枚举数据类型是一种由程序员定义的数据类型,其合法值是与它们关联的一组命名整数常量。符号常量是整数值,它本身不是字符串
3.4 绝大多数程序员都会釆用枚举数据类型名字首字母大写的形式
3.7 虽然没有要求按升序排列赋给的整数值,但一般默认是这样
3.8 因为枚举数据类型的符号名称与整数值相关联,所以它们可以在 switch 语句中使用
4.3 精简长类型名,简化C++构体变量的定义,用 typedef 定义别名
1.c++结构体struct
1.1 存储不同类型的数据项,把不同类型的数据结合合成一个整体用来描述某一对象
1.2 struct 语句定义了一个包含多个成员的新的数据类型
1.3 结构体必须先定义类型,后定义它的变量
struct point { int x; int y; }; struct point pt; // C : 定义结构体变量 pt point pt; // C++ : 可省略struct1.4 结构体大小(Bytes)用sizeof查看
定义结构体变量: struct student // 类型名 student { unsigned int ID ; char name[20] ; bool sex ; date birthday; // 定义结构体变量 int score[35] ; } stud1, stud2 ; // 定义2个结构体变量 //这里也可以这样定义结构体 //student stud1; //student stud2; student *sp; // 定义结构体指针 student st1[3]; // 定义结构体数组(一维) student st2[3][4]; // 定义结构体数组(二维) 无名结构体类型: struct // 省略类型名:无名结构体 { unsigned int ID ; char name[20] ; bool sex ; date birthday; // 定义结构体变量 int score[35] ; } stud;1.5 结构体变量的初始化:定义变量时赋值
student John = // 定义变量并初始化 { 326, "John", 0, {1992,5,15}, {85,90,80}}; student Joe = John; //赋值类型相同1.6 访问结构体的变量用“.”或者"->"
Joe = John; // 赋值 John.ID = 215; John.birthday.year = 1990; John.birthday.month = 8; John.score[0]=95; John.score[1]=85; John.score[2]=75;1.7 结构体数组及其初始化
struct student //类型名 { unsigned int ID ; string name ; bool sex ; date birthday ; int score[3] ; } stu[100]; //结构体数组 student stu[4] = //一维数组 { 101, "张三", 1, {1992,3,5}, {85,95,90}, 102, "李四", 0, {1992,6,8}, {90,87,82}, 103, "王五", 1, {1993,1,8}, {80,80,85}, 104, "赵六", 0, {1992,9,2}, {75,80,90} };1.8 结构体指针
int main() { struct date{int year,mouth,day}; date day; *p=&day; cout<<"输出(年月日)"<<endl; cin>>day.year>>day.month>>day.day; cout<<"日期:"<<p->year<<"/"<<p->month<<"/"<<p->day; cout<<endl; system("pause"); return 0; } void printBook( struct Books *book ); struct Books { char title[50]; char author[50]; char subject[100]; int book_id; };1.9 结构体作为函数参数
void printBook( struct Books book ); // 声明一个结构体类型 Books struct Books { char title[50]; char author[50]; char subject[100]; int book_id; };
2.c++共用体union
2.1 共用体表示几个变量共用一个内存位置(各成员共享一段内存空间),在不同的时间保存不同的数据类型和不同长度的变量。所以一个联合变量的长度等于其成员中最长的那个成员的长度
2.2 在 union中,所有的共用体成员共用一个空间,并且只能储存其中一个成员变量的值达到节省空间的目的(还有一个节省空间的类型:位域)
2.3 共用体变量中各成员从第一个单元开始分配存储空间,所以各成员的内存地址是相同的
2.4 能够存储不同的数据类型,但只能同时存储其中的一种类型,即在任意时刻只有一个数据成员可以有值
共用体:共用体只能存储int、long或double
这里例举一下结构体:可以同时存储int、long和double
union uninType { int fourByte; char oneByte[4]; }; //创建这种类型的变量 uninType Test1; uninType Test2;2.5 给union的某个成员赋值后,该union的其他成员就变成未定义状态
虽然共用体数据可以在同一内存空间中存放多个不同类型的成员,但在某一时刻只能存放其中的一个成员,起作用的是最后存放的成员数据,其他成员不起作用,如引用其他成员,则数据无意义。 例如,对data类型共用体变量,有以下语句: x.a=100; strcpy(x.n,"zhangsan"); x.f=90.5; 则只有x.f是有效的,x.a与x.n目前数据是无意义的,因后面的赋值语句将前面共用体数据覆盖了2.6 同struct一样,联合默认访问权限也是公有的,并且,也具有成员函数
2.7 C++中union类型定义后使用时可以省去union
union myu liu; // C中定义了一个liu类型的变量 myu liu; // C++中定义了一个liu类型的变量2.8 共用体变量的初始化
定义了共用体变量后,即可使用它。若需对共用体变量初始化,只能对它的第一个成员赋初始值。 例如: union data x={"zhangsan"}; 是正确的, union data x={"zhangsan",12,40000, 78,5}; 是错误的。2.9 定义共用体及定义该数据变量
(1)先定义共用体类型,再定义该类型数据 例如: union data { char n[10]; int a; double f; }; union data x,y[10]; (2)在定义共用体类型的同时定义该类型变量 例如: union data { char n[10]; int a; double f; }x,y[10]; (3)不定义共用体类型名,直接定义共用体变量 例如: union { char n[10]; int a; double f; }x,y[10];2.10共用体和结构体的区别
共用体和结构体都是由多个不同的数据类型成员组成, 但在任何同一时刻, 共用体只存放了一个被选中的成员, 而结构体的所有成员都存在。
对于共用体的不同成员赋值, 将会对其它成员重写, 原来成员的值就不存在了, 而对于结构体的不同成员赋值是互不影响的。
3.c++枚举enum
3.1 枚举类型:有限个整型符号常量枚举常量的集合
3.2 用途与定义:若某变量只能取有限几个整数值,把他们一一列举出来定义为枚举类型(限定变量的取值)
默认情况下,编译器设置第一个枚举量为 0,下一个为 1,以此类推
若某变量只能取有限几个整数值,把它们一一列举出来 定义为枚举类型:限定变量的取值好风格 例如: enum weekday // 类型名 { Sun, Mon, Tue, Wed, Thu, Fri, Sat } ; // 枚举常量 weekday day ; // 定义枚举变量day day 取值:只能取枚举常量值之一 不能取代表的整数值! 枚举常量依次对应一个整数(0开始):0,1,2,3,4,5,6 内存存储:符号常量的整数值 各种运算3.3 枚举数据类型是一种由程序员定义的数据类型,其合法值是与它们关联的一组命名整数常量。符号常量是整数值,它本身不是字符串
3.4 绝大多数程序员都会釆用枚举数据类型名字首字母大写的形式
3.5 定义类型时:可指定每个枚举常量的整数值
enum Department { factory = 1, sales = 2, warehouse = 4 };3.6 为枚举符号赋值,则它们必须是整数
以下赋值语句将产生错误: enum Department { factory = 1.1, sales = 2.2, warehouse = 4,4 }; //错误3.7 虽然没有要求按升序排列赋给的整数值,但一般默认是这样
enum Colors { red, orange, yellow = 9, green, blue }; 在该示例中,命名常量 red 将被赋值为 0,orange 将为 1,yellow 将为 9,green 将为 10,blue 将为 11 enum Rooms { livingroom = 1, den, bedroom, kitchen }; 在该示例中,livingroom 被赋值为 1,den 将为 2,bedroom 将为 3,kitchen 将为 43.8 因为枚举数据类型的符号名称与整数值相关联,所以它们可以在 switch 语句中使用
4.c++类型别名typedef
4.1 给已定义的类型取一个别名
语法:typedef 已定义类型名 类型别名 ; 例如: typedef unsigned int UINT ; UINT x, y ;4.2 结构体结合别名
//第一种情况 struct MyStruct{ int data1; char data2; }; typedef struct MyStruct newtype; newtype a, b; //第二种情况 typedef struct MyStruct{ int data1; char data2; }newtype; newtype a, b; //第三种情况 typedef struct{ int data1; char data2; }newtype; newtype a, b;4.3 精简长类型名,简化C++构体变量的定义,用 typedef 定义别名
typedef struct point { int x; int y; } POINT, *pPOINT; POINT pt ; //变量 pPOINT p ; //指针 struct point { int x; int y; }; typedef struct point POINT, *pPOINT;4.4 定义指针
typedef int * pINT ; pINT pa, pb; //两个int指针4.5 为较复杂的定义/声明定义简单的别名
void (*func[2])(int *) ; // 怎么理解? 1 理解复杂声明/定义 右左法:找到变量名,先往右、后往左看,碰到圆括号就调转方向。看完括号就跳出,继续先右后左看...... 1.1 找到变量名 func,往右看[2] —— 数组 func[2] 1.2 往左看 * —— 指针:*func[2]是指针数组 1.3 跳出左边( ), 往右看(int *)——函数(形参int *) 1.4 往左看 void —— 函数无返回值 结论:func 是函数 + 指针数组 有2个函数指针 2.类型定义:逐个用别名替换复杂声明定义的一部分 typedef int (*FUN[2])(int *); //类型名 FUN
5.c++动态数据结构链表
5.1 什么是链表
链表是一种动态数据结构,用来处理大量同类型的数据 (注意:这些数据可作为一个整体来存储和读取)各个数据之间以特定方式前后相联接,形成链式结构5.2 什么是动态数据结构
1.静态数据结构(数组) 数组一旦定义,编译程序为其分配一片连续的内存空间,各元素依次存放(各元素内存地址连续)。数组长度一定(存放固定数目的元素)对数据进行删除、插入操作就非常烦琐 2.动态数据结构 同样用于处理大量同类型数据,但各个元素所在内存地址并不一定连续(由程序随机分配)动态数据结构中的数据元素以结点的形式存在对数据的删除、插入操作非常方便5.3 链表的形成方式
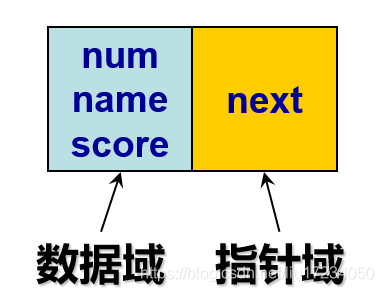
链表是由包含数据的多个结点前后连接形成的链式结构 1.结点: 每一个结点是一小片连续的、存放了数据的内存空间,是形成链表的基本单元 2.结点的构成: 每个结点由两方面内容组成: (1)数据域: 真正要处理的数据,可以是单个基本类型的数据,也可以是多个不同类型的数据共同构成。 (2)指针域: 一般用来存放另一结点的首地址,即指针域是用来指向另一个结点的(或者赋值为NULL,即不指向任何结点。)5.4 简单链表的形成
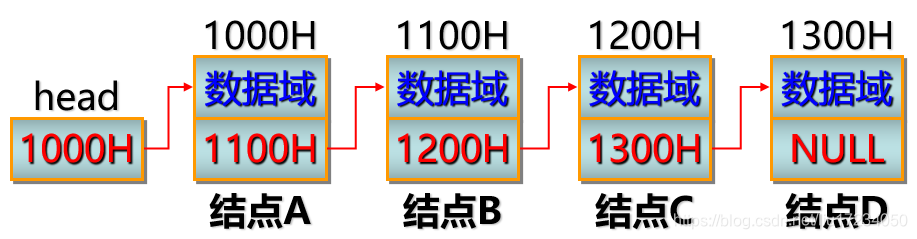
链表正是通过指针域将各个结点有机地联接成一个整体。设有A、B、C、D四个结点,按下图形成链表 注意 (1)head:设计的头部指针, 指向链表头结点 (2)NULL:尾部结点的指针域为空,不指向任何结点。 (3)前一节点的指针域存放下一结点的首地址5.5 如何用C/C++语言创建结点和简单链表(不适用)
建立方法:用包含指针项的结构体变量来构成结点。如: typedef struct student { int num; char name[5]; float score; struct student *next; }StuNode;//结点类型的定义 其中: 数据域 num , name , score 指针域 next(指向结构体类型的指针)构成可用下面的方法建立简单链表: struct student stu1,stu2,stu3,*head; //数据域赋值 stu1.num=1001; stu1.name=“Zhao”; stu1.score=99.0; stu2.num=1002; stu2.name=“Qian”; stu2.score=88.0; stu3.num=1003; stu3.name=“Wang” stu3.score=77.0; head=&stu1; //指针域赋值以形成链表 stu1.next=&stu2; stu2.next=&str3; stu3.next=NULL;用此种方法建立链表所存在的缺点: (1)事先必须定义确定个数的结构体变量(结点数量),缺乏灵活性,想要增加结点时,就必须修改程序 (2)所有结点都自始至终占据内存,而不是动态地进行存储空间的分配 故上述链表构成方法在实际上很少使用5.6 C/C++中的动态分配内存的方法
结点应该在需要时(如在现有链表中插入新结点)才建立(分配内存),被删除的结点,其所占用的内存应释放。为此必须使用C/C++语言的动态内存分配函数。 C:内存分配使用函数malloc(),例如: StuNode *pnew; pnew=(StuNode*)malloc(sizeof(StuNode)); 释放内存:free(pnew); C++:动态分配内存使用new,例如: StuNode *pnew=new StuNode; 释放内存:delete pnew;5.7 实用链表的构造方法(适用)
typedef struct student { int num; char name[5]; float score; struct student *next; }StuNode; StuNode *pnew=new StuNode;5.8 数据域、指针域
5.9 Head、pnew、pend
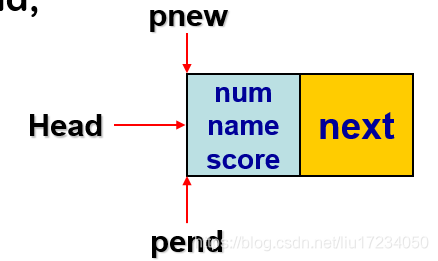
定义结点类型的指针Head,用以指向链表的头部; 定义结点类型的辅助指针pnew和pend,以完成链表的建立: StuNode *Head, *pnew , *pend;5.10 单链表的建立过程
第一步:建立第1个结点
pnew=new StuNode; //建立新结点 Head=pnew; //头指针指向第1个结点 pend=pnew; //辅助指针,指向当前表尾第二步:建立第2个结点
(1)pnew=new StuNode; (2)pend->next=pnew; (3)pend=pnew; //pend指向尾结点第三步:建立第3个结点
(1)pnew=new StuNode; (2)pend->next=pnew; (3)pend=pnew; //pend又指向尾部结点第四步:建立最后一个结点
(1)pnew=new StuNode; (2)pend->next=pnew; (3)pend=pnew; (4)pend->next=NULL5.11 如在A、C两结点之间插入结点B
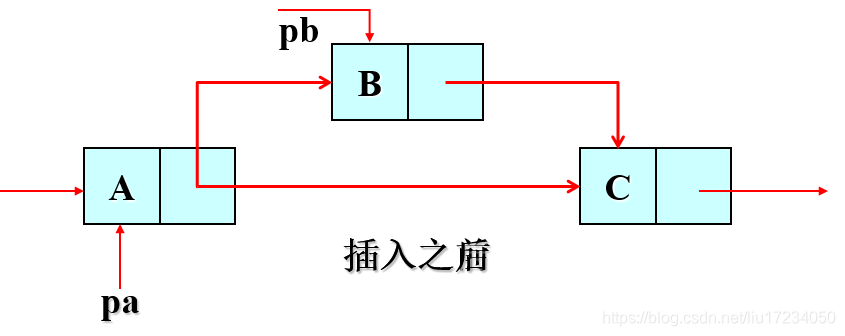
执行:pb->next=pa->next; 执行:pa->next=pb;5.12 插入结点位置在首位之间
两个辅助指针ps与pe相邻,从链表头部开始,移动到应该插入结点的地方再执行插入操作 //关键执行语句 ps=Head; pe=ps->next; while(pe->num<pnew->num) { ps=ps->next; pe=pe->next; } pnew->next=pe; ps->next=pnew;5.13 销毁链表
用于销毁链表(delete Nodes one by one)StuNode *DestroyList(StuNode *Head) { StuNode *pt; do { pt=Head; Head=Head->next; delete pt; }while(Head); return Head;


















 2809
2809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











