







0.论文介绍:
对GIST特征进行哈希,然后通过hashcode进行检索和分类。作者介绍了基于机器学习的几种方法:BoostSSC,和RBM,通过实验,可以看出来,做这提出来的方法在LabelMe和webImages两个数据集上相比于LSH获得了较好的结果。
1.BoostSSC
把原空间的数据,嵌入到hamming空间中,原始数据之间的距离使用带有权重的hamming距离来替代。
图像可以使用
M
维的向量表示
那么两个图像之间的距离可以使用带有权重的hamming距离来代替:
D(i,j)=∑Mn=1αn|hn(xi)−hn(xj)|
其中
αn,hn(xi)
都是使用Boosting 方法学出来的值。
对于Boosting 学习参数的过程:
对于两张图像
xi,xj
如果
j∈N(xj)
N(xj)
表示
xi
的近邻点。
那么认为这两张图片构成了正样本。这样就完成了带有标签的数据的准备。
下面对于Boosting学习过程中的损失函数进行介绍:
其中 ek 表示的是单位向量,所以 eTkxi 表示的是获得 xi 第K个分量。 Tn 表示的是一个阈值。所以要最小化如下的二次损失:
其中 K 表示的是所有的训练数据图像对。
作者说学习的目的是为了学到Hamming 距离的度量机制,所以设置所有的
当学习过程完成之后,对于图片可以认为是通过上述学习获得一个
M
bits 的hashcode,对于hashcode 的每一维可以使用上述的一个公式,
作者在训练(学习的过程当中)训练的数据对是150000图相对。
2.Restricted Boltzmann Machines
受限波尔兹曼机类似于后来的较浅层的神经网络
对于一个含有隐藏层的网络,可见层的一个单元
v
和隐藏层
有如下的能量公式:
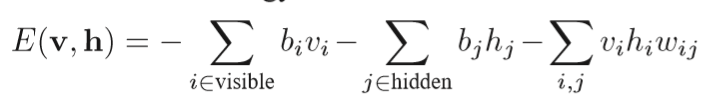
其中
wij
是权重,
bi,bj
是偏置项。
根据这个能量公式可以得到这个可见层
v
向量出现的概率
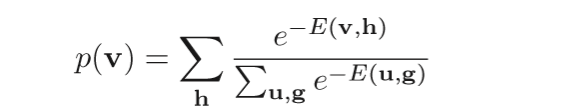
对于可见层和隐藏层的关系,可以看到有如下的条件概率分布
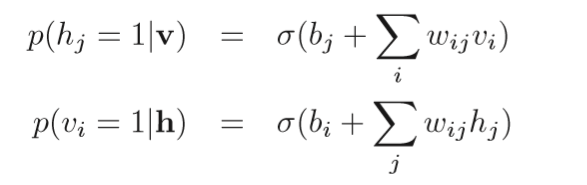
其中
通过上述的条件概率分布可以选择出现最大的一个,所以上述公式当中的所有的参数
wij,bi,bj
可以使用gibbs采样作为转移,并通过隐马尔科夫过程获得收敛。
后面的实验当中作者使用了多个受限玻尔兹曼机来叠加在一起来获得多层的网络,每个隐藏层在输出之后作为下一个受限玻尔兹曼机可见层的输入数据。
3.实验
数据集:
LabelMe:22000张图片
Web image dataset:12.9 million图片
输入特征使用GIST特征。
3.1 hashcode的长度的影响
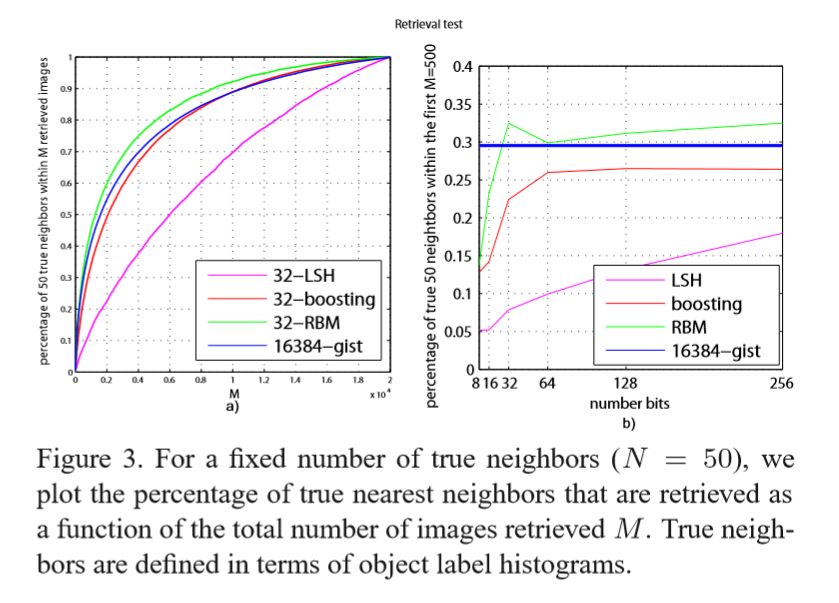
在固定最近邻点
N=50
的情况下,检索M个点的返回结果当中是实际近邻点的个数。
其中距离的定义为直方图距离,直方图相交。
从上面的图中可以看出随着hashcode长度的增加,检索的特征的个数为M =500,看出来RBM的实验结果比其他几种方法要好。其实最后的检索的效果是趋于稳定的。RBM最好的性能是在hashcode为30的时候。
从检索特征的个数来看,RBM好于其他的几种方法。随着检索特征的增加,最后趋向于一个暴力搜索的过程。
3.2 Web image retrieval
12.9 million= 12900000 的web 图像
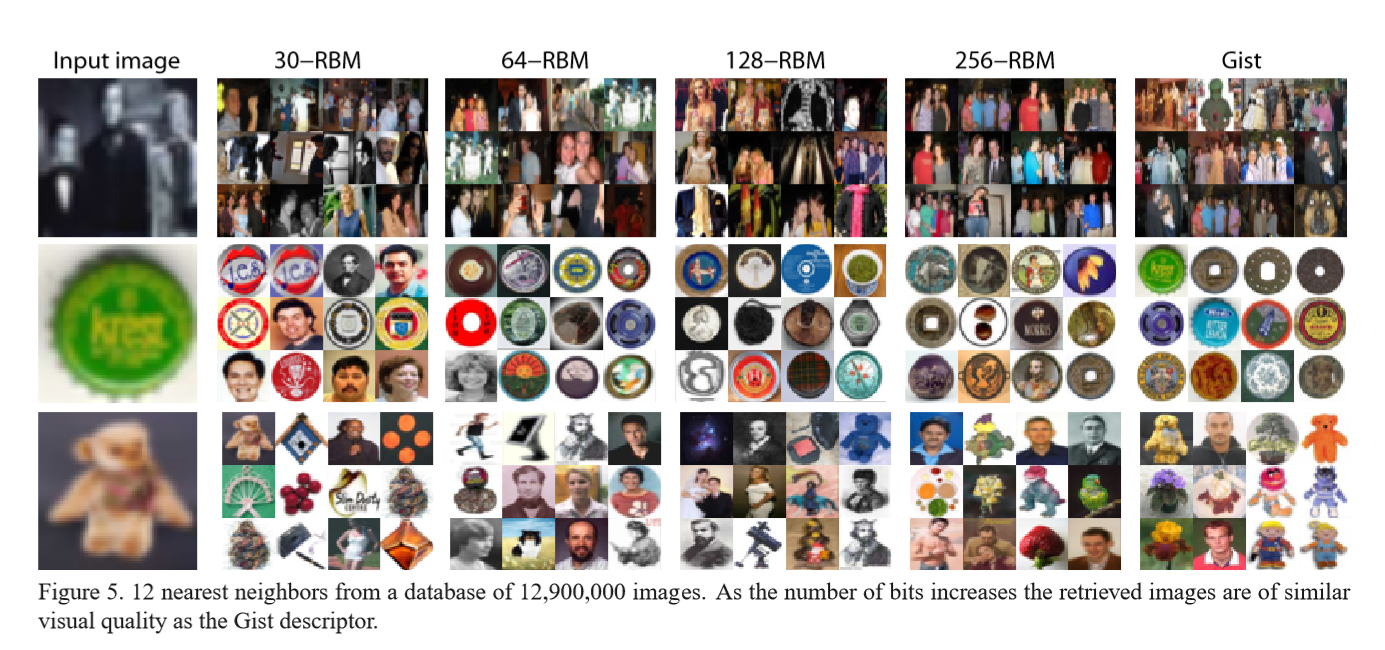
从这个不同hashcode 长度的检索的实验结果来看,可以得出来,随着hashcode 长度的增加,检索的效果也是越来越好,但是也会出现检索时间的问题。下面给出,不同hashcode长度的检索结果。
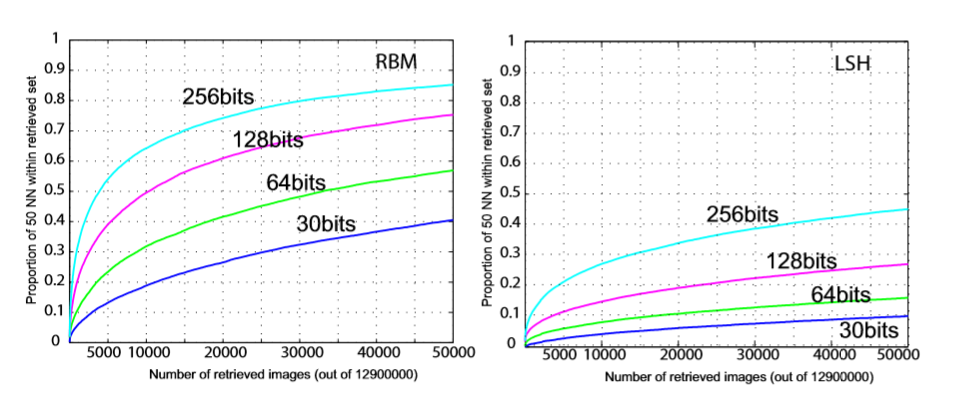
可以看出来,RBM相比与LSH获得相同的近邻点,所需要检索更少的图像。
3.3检索速度比较
随着hashcode长度的增加所需要的检索时间也是增加的所以,所以作者给出了检索速度的实验结果:
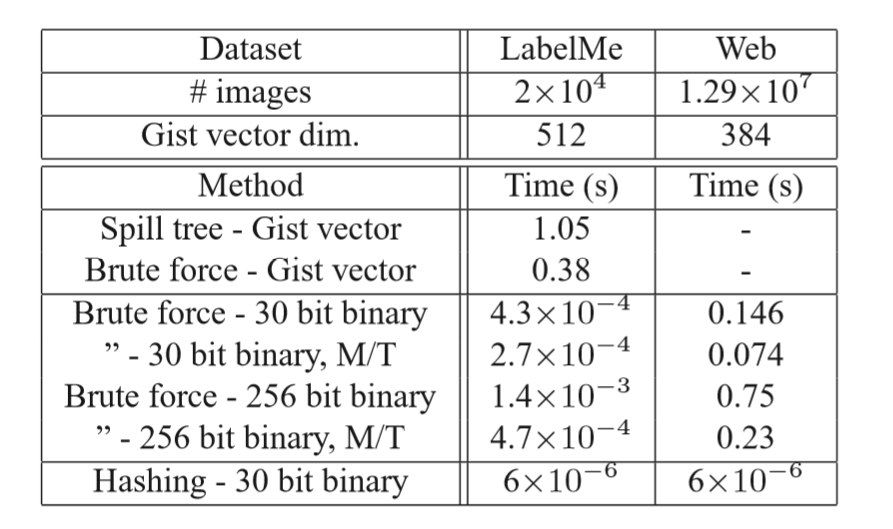
LabelMe数据集:检索1000近邻点的时间kd-tree大约是3ms/image
会检索到17%的真实的近邻点。RBM需要6us/image 并且可以检索到48%的实际近邻点。kd-tree不能用于web image数据集,因为数据集太大。不能完全放在内存当中。
3.4hashcode关于识别的实验
在Web image数据集上实现分类任务。
分类的方法:找到最近邻的500张图片中类别数目最多的那一类作为查询图片的分类结果。作者给出了在这个数据集上person类别是实验结果:
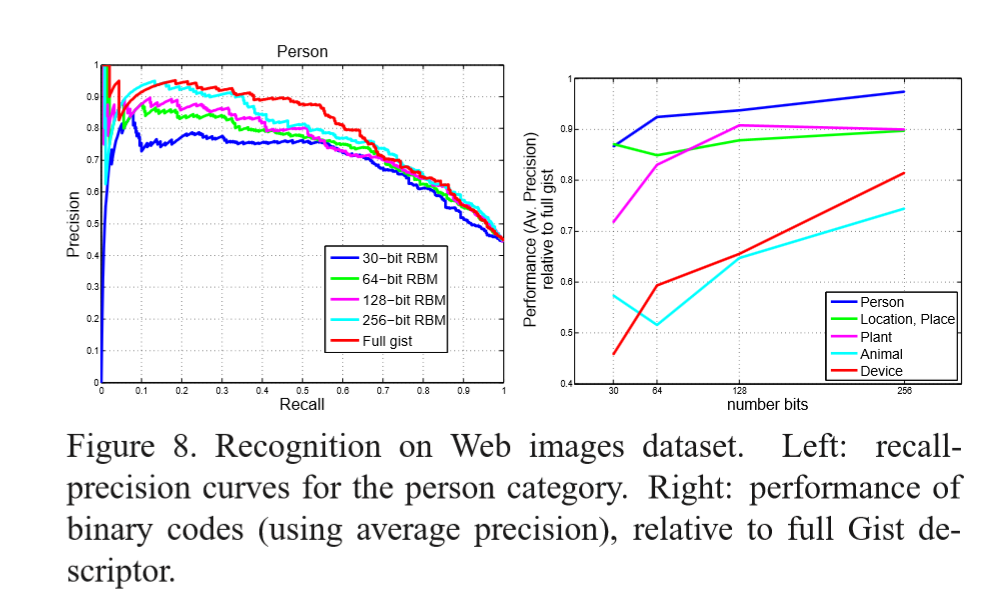
可以看出来,RBM hashcode的长度越长所表现出来的结果越好,当然最好的结果是GIST特征的暴力搜索。
右边的图可以看出来,相对于GIST所有维度的特征,进行分类,作者给出不同hashcode长度的相对于full GIST分类的结果。随着hashcode长度的增加,分类的结果也是越来越好。
4.总结
对于搜索引擎,有的时候简单的算法可能会起到很好的效果。作者提出基于机器学习的方法,在特定的数据集上学习到hashcode,通过hashcode来进行检索或者分类任务。这样可以减少数据所占用的内存。从而达到比较好的效果。














 3324
3324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









