







前言
本文主要对词性标注、依存句法分析、语义依存分析这三个任务,进行简单的调用code实现。
词性标注(POS)
词性标注(Part-of-speech tagging),词性标注是用适当的词性标记句子中每个单词的任务。是为给定句子中的每个单词分配给定标签集中的词性标签。就是对句子中的词进行分类和标注的过程,实际上是一个多分类任务。我们根据词在句法结构或语言形式中的成分,通过词性分类给每个词赋予相应的词性。
即判断句子中的每个单词是名词、动词、形容词还是其他词性。
词性标注是自然语言处理中的一项基本任务,在语音识别、信息检索等诸多领域都有应用。词性标注的常用方法是使用序列标注模型,例如 RNN 或 transformer。序列标注模型以一个单词序列作为输入,输出将是一个 POS 标签序列,其中每个 POS 标签都是对输入序列中相应单词的预测。
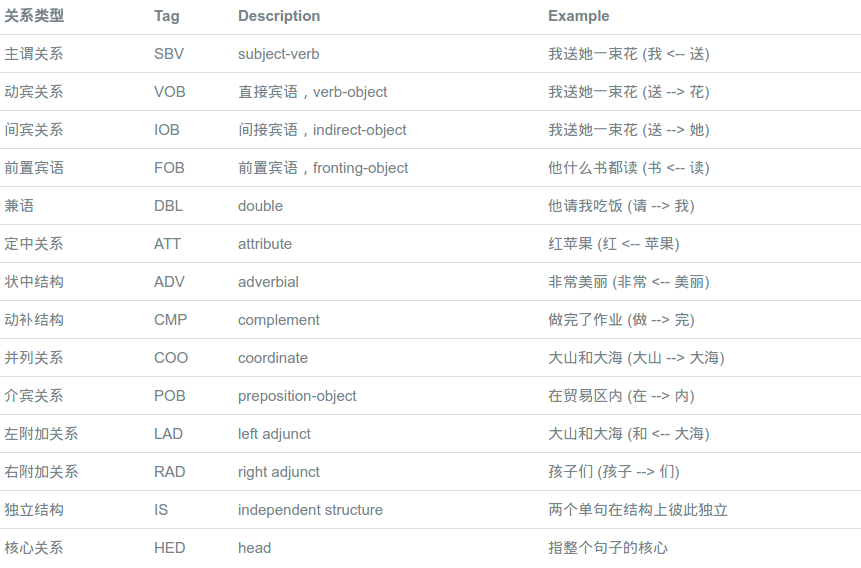
依存句法分析(DP)
依存句法分析(Dependency Parsing, DP) 通过分析语言单位内成分之间的依存关系揭示其句法结构。依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。
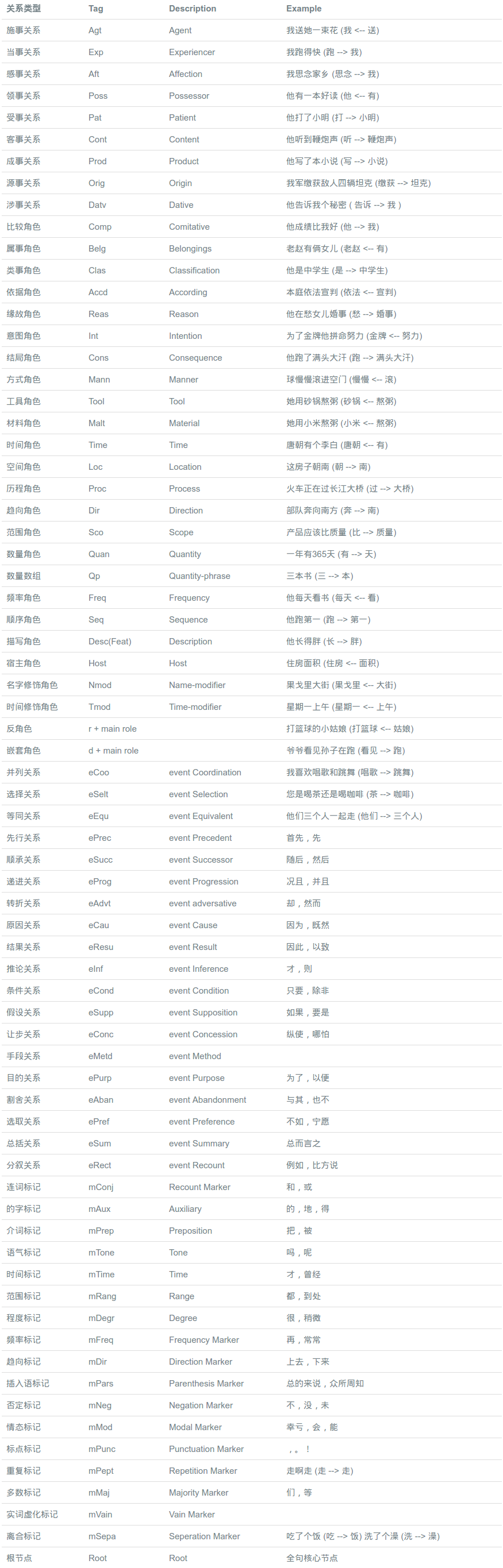
语义依存分析(SDP)
语义依存分析 (Semantic Dependency Parsing, SDP) 分析句子各个语言单位之间的语义关联,并将语义关联以依存结构呈现。语义依存分析目标是跨越句子表层句法结构的束缚,直接获取深层的语义信息。语义依存分析不受句法结构的影响,将具有直接语义关联的语言单元直接连接依存弧并标记上相应的语义关系。
语义依存对句子语义信息的刻画更加完整全面。
实践
Standford CoreNLP
【需安装JAVA1.8+,需下载模型】
安装:pip install stanfordcorenlp
国内源安装:
pip install stanfordcorenlp -i https://pypi.tuna.tsinghua.edu.cn/simple
from stanfordcorenlp import StanfordCoreNLP
##读取stanford-corenlp所在的目录
nlp = StanfordCoreNLP(r'stanford-corenlp-4.4.0')
sentence = "Check for common UAC bypass weaknesses on Windows systems to be aware of the risk posture and address issues where appropriate"
print('Part of Speech:', nlp.pos_tag(sentence))
# Stanford parser基本上是一个词汇化的概率上下文无关语法分析器,同时也使用了依存分析。
print(nlp.parse(sentence)) # 句法依存分析
print(nlp.dependency_parse(sentence)) # 依存分析
NLTK
【需下载模型】
安装:pip install nltk
国内源安装:pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
基于词的角度来分析词性
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
text ="Check for common UAC bypass weaknesses on Windows systems to be aware of the risk posture and address issues where appropriate"
# 分词
text_list = nltk.word_tokenize(text)
#去掉标点符号
english_punctuations = [',', '.', ':', ';', '?', '(', ')', '[', ']', '&', '!', '*', '@', '#', '$', '%']
text_list = [word for word in text_list if word not in english_punctuations]
# 去掉停用词
# stops = set(stopwords.words("english"))
# text_list = [word for word in text_list if word not in stops]
out_text = nltk.pos_tag(text_list)
print(out_text)
基于句的角度来分析词性
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
sentences = nltk.sent_tokenize(text)
# print(sentences)
data = []
for sent in sentences:
data = data + nltk.pos_tag(nltk.word_tokenize(sent))
print(data)
# for word in data:
# if 'NNP' == word[1]:
# print(word)
spaCy
【需下载模型】
工业级别自然语言处理,在最新的spaCy版本中,包含了经过训练的“管道”,同时支持全球近60种语言表计划和基于NLP的训练,具备有最先进的速度和神经网络模型,用于标记、解析、命名实体识别、文本分类等,诸如使用 BERT 等预训练转换器进行多任务学习,以及训练后的系统打包、部署和工作流管理。
安装:pip install spaCy
国内源安装:pip install spaCy -i https://pypi.tuna.tsinghua.edu.cn/simple
下载不了模型,需要python -m spacy download en_core_web_sm。
import spacy
from spacy import displacy
# eng_model = spacy.load('en')
eng_model = spacy.load("en_core_web_sm")
sentences_token = eng_model(text)
print(sentences_token)
for s in sentences_token:
print(s, s.pos_,s.tag_) # 词性分析
print(s.dep_) # 句法依存分析
# print(displacy.render(sentences_token)) #可视化标记
词性介绍表
CC 并列连词 NNS 名词复数 UH 感叹词
CD 基数词 NNP 专有名词 VB 动词原型
DT 限定符 NNP 专有名词复数 VBD 动词过去式
EX 存在词 PDT 前置限定词 VBG 动名词或现在分词
FW 外来词 POS 所有格结尾 VBN 动词过去分词
IN 介词或从属连词 PRP 人称代词 VBP 非第三人称单数的现在时
JJ 形容词 PRP$ 所有格代词 VBZ 第三人称单数的现在时
JJR 比较级的形容词 RB 副词 WDT 以wh开头的限定词
JJS 最高级的形容词 RBR 副词比较级 WP 以wh开头的代词
LS 列表项标记 RBS 副词最高级 WP$ 以wh开头的所有格代词
MD 情态动词 RP 小品词 WRB 以wh开头的副词
NN 名词单数 SYM 符号 TO to
ROOT:要处理文本的语句 IP:简单从句 NP:名词短语
VP:动词短语 PU:断句符,通常是句号、问号、感叹号等标点符号
LCP:方位词短语 PP:介词短语
CP:由‘的’构成的表示修饰性关系的短语 DNP:由‘的’构成的表示所属关系的短语
ADVP:副词短语 ADJP:形容词短语
DP:限定词短语 QP:量词短语
NN:常用名词 NR:固有名词
NT:时间名词 PN:代词
VV:动词 VC:是
CC:表示连词 VE:有
VA:表语形容词 AS:内容标记(如:了)
VRD:动补复合词 CD: 表示基数词
DT: determiner 表示限定词 EX: existential there 存在句
FW: foreign word 外来词 IN: preposition or conjunction, subordinating 介词或从属连词
JJ: adjective or numeral, ordinal 形容词或序数词
JJR: adjective, comparative 形容词比较级
JJS: adjective, superlative 形容词最高级
LS: list item marker 列表标识 MD: modal auxiliary 情态助动词
PDT: pre-determiner 前位限定词 POS: genitive marker 所有格标记
PRP: pronoun, personal 人称代词 RB: adverb 副词
RBR: adverb, comparative 副词比较级 RBS: adverb, superlative 副词最高级
RP: particle 小品词 SYM: symbol 符号
TO:”to” as preposition or infinitive marker 作为介词或不定式标记
WDT: WH-determiner WH限定词
WP: WH-pronoun WH代词
WP$: WH-pronoun, possessive WH所有格代词
WRB:Wh-adverb WH副词
关系表示
abbrev: abbreviation modifier,缩写
acomp: adjectival complement,形容词的补充;
advcl: adverbial clause modifier,状语从句修饰词
advmod: adverbial modifier状语
agent: agent,代理,一般有by的时候会出现这个
amod: adjectival modifier形容词
appos: appositional modifier,同位词
attr: attributive,属性
aux: auxiliary,非主要动词和助词,如BE,HAVE SHOULD/COULD等到
auxpass: passive auxiliary 被动词
cc: coordination,并列关系,一般取第一个词
ccomp: clausal complement从句补充
complm: complementizer,引导从句的词好重聚中的主要动词
conj: conjunct,连接两个并列的词。
cop: copula。系动词(如be,seem,appear等),(命题主词与谓词间的)连系
csubj: clausal subject,从主关系
csubjpass: clausal passive subject 主从被动关系
dep: dependent依赖关系
det: determiner决定词,如冠词等
dobj: direct object直接宾语
expl: expletive,主要是抓取there
infmod: infinitival modifier,动词不定式
iobj: indirect object,非直接宾语,也就是所以的间接宾语;
mark: marker,主要出现在有“that” or “whether”“because”, “when”,
mwe: multi-word expression,多个词的表示
neg: negation modifier否定词
nn: noun compound modifier名词组合形式
npadvmod: noun phrase as adverbial modifier名词作状语
nsubj: nominal subject,名词主语
nsubjpass: passive nominal subject,被动的名词主语
num: numeric modifier,数值修饰
number: element of compound number,组合数字
parataxis: parataxis: parataxis,并列关系
partmod: participial modifier动词形式的修饰
pcomp: prepositional complement,介词补充
pobj: object of a preposition,介词的宾语
poss: possession modifier,所有形式,所有格,所属
possessive: possessive modifier,这个表示所有者和那个’S的关系
preconj: preconjunct,常常是出现在 “either”, “both”, “neither”的情况下
predet: predeterminer,前缀决定,常常是表示所有
prep: prepositional modifier
prepc: prepositional clausal modifier
prt: phrasal verb particle,动词短语
punct: punctuation,这个很少见,但是保留下来了,结果当中不会出现这个
purpcl: purpose clause modifier,目的从句
quantmod: quantifier phrase modifier,数量短语
rcmod: relative clause modifier相关关系
ref: referent,指示物,指代
rel: relative
root: root,最重要的词,从它开始,根节点
tmod: temporal modifier
xcomp: open clausal complement
xsubj: controlling subject 掌控者
中心语为谓词
subj — 主语
nsubj — 名词性主语(nominal subject) (同步,建设)
top — 主题(topic) (是,建筑)
npsubj — 被动型主语(nominal passive subject),专指由“被”引导的被动句中的主语,一般是谓词语义上的受事 (称作,镍)
csubj — 从句主语(clausal subject),中文不存在
xsubj — x主语,一般是一个主语下面含多个从句 (完善,有些)
中心语为谓词或介词
obj — 宾语
dobj — 直接宾语 (颁布,文件)
iobj — 间接宾语(indirect object),基本不存在
range — 间接宾语为数量词,又称为与格 (成交,元)
pobj — 介词宾语 (根据,要求)
lobj — 时间介词 (来,近年)
中心语为谓词
comp — 补语
ccomp — 从句补语,一般由两个动词构成,中心语引导后一个动词所在的从句(IP) (出现,纳入)
xcomp — x从句补语(xclausal complement),不存在
acomp — 形容词补语(adjectival complement)
tcomp — 时间补语(temporal complement) (遇到,以前)
lccomp — 位置补语(localizer complement) (占,以上)
— 结果补语(resultative complement)
中心语为名词
mod — 修饰语(modifier)
pass — 被动修饰(passive)
tmod — 时间修饰(temporal modifier)
rcmod — 关系从句修饰(relative clause modifier) (问题,遇到)
numod — 数量修饰(numeric modifier) (规定,若干)
ornmod — 序数修饰(numeric modifier)
clf — 类别修饰(classifier modifier) (文件,件)
nmod — 复合名词修饰(noun compound modifier) (浦东,上海)
amod — 形容词修饰(adjetive modifier) (情况,新)
advmod — 副词修饰(adverbial modifier) (做到,基本)
vmod — 动词修饰(verb modifier,participle modifier)
prnmod — 插入词修饰(parenthetical modifier)
neg — 不定修饰(negative modifier) (遇到,不)
det — 限定词修饰(determiner modifier) (活动,这些)
possm — 所属标记(possessive marker),NP
poss — 所属修饰(possessive modifier),NP
dvpm — DVP标记(dvp marker),DVP (简单,的)
dvpmod — DVP修饰(dvp modifier),DVP (采取,简单)
assm — 关联标记(associative marker),DNP (开发,的)
assmod — 关联修饰(associative modifier),NP|QP (教训,特区)
prep — 介词修饰(prepositional modifier) NP|VP|IP(采取,对)
clmod — 从句修饰(clause modifier) (因为,开始)
plmod — 介词性地点修饰(prepositional localizer modifier) (在,上)
asp — 时态标词(aspect marker) (做到,了)
partmod– 分词修饰(participial modifier) 不存在
etc — 等关系(etc) (办法,等)
中心语为实词
conj — 联合(conjunct)
cop — 系动(copula) 双指助动词????
cc — 连接(coordination),指中心词与连词 (开发,与)
其它
attr — 属性关系 (是,工程)
cordmod– 并列联合动词(coordinated verb compound) (颁布,实行)
mmod — 情态动词(modal verb) (得到,能)
ba — 把字关系
tclaus — 时间从句 (以后,积累)
— semantic dependent
cpm — 补语化成分(complementizer),一般指“的”引导的CP (振兴,的)
总结
以上只是对词性标注、依存句法分析、语义依存分析进行了简单的实践,并没有深入进行分析总结。
以上是我个人在学习过程中的记录所学,希望对正在一起学习的小伙伴有所帮助!!!
如果对你有帮助,希望你能一键三连【关注、点赞、收藏】!!!
参考链接
CoreNLP
stanfordcorenlp · PyPI
Stanford Core NLP用法
Release History - CoreNLP (stanfordnlp.github.io)
The Stanford Natural Language Processing Group
stanfordnlp/corenlp-english-extra at main (huggingface.co)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











