









1,词向量
传统方法是使用类似于WordNet或《同义词词林》的方式来表示词语之间的关系(上下位、同义词、相似度等),
但是这种方法存在很大局限性(人工、新词、主观误差等),所以这里提出词向量的方法表示单词。
其实就是找到一种映射关系,将单词编码为更小的“词空间”中的一个向量。可以知道,一定存在一个远小于总词汇量的
N维空间可以编码所有的单词。这样可以通过计算两个词向量之间的“距离”来表示其相似度。
最简单的就是one-hot编码,如果辞典中共V个单词,那么就把每个单词编码为一个|V|*1的向量,且仅其索引位置设为1,其余元素均为0.
这样虽然简单,但是每个单词之间相互独立,词向量之间的距离都是0,没有办法计算词语之间的相似度信息。而且空间维数过高。
2,基于SVD奇异值分解的词向量表示方法
2.1,单词-文档矩阵
认为出现在同一篇文档中的单词是相关的。若|V|表示单词数目,|M|表示文档数目,则词-文档共现矩阵X大小为|V|*|M|。
矩阵中每个元素Xij表示第i个单词在文档j中出现的次数。
2.2,基于窗口的词-词共现矩阵
对于单词i而言,如果单词j在其窗口内出现则计数+1.词-词共现矩阵X大小为|V|*|V|的对称矩阵,窗口长度一般取5-10之间。
其实就是将文档缩小到窗口大小进行遍历。讲义中提了一个例子在此不再赘述。
2.3,对共现矩阵X进行SVD奇异值分解。
首先观察X的对角元素,根据我们想得到的百分比进行截断(根据百分比求k值)。
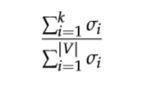
然后对X进行奇异值分解,等式右边三个矩阵分别为U,S,V。U就是我们想要的词向量:
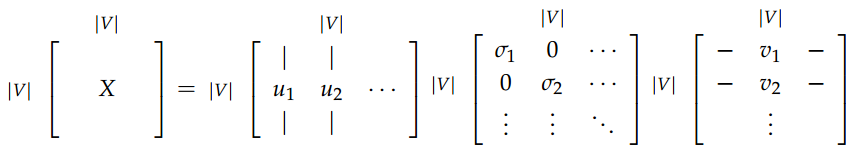
最后进行k截断降维:
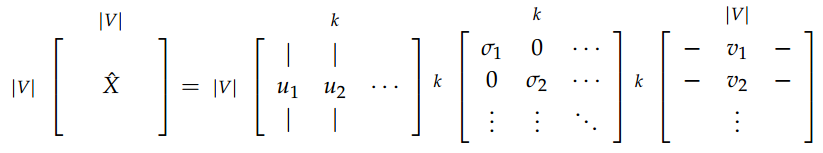
从上图我们可以看出,经过k阶段之后,U矩阵实现了降维的目的。这样U中的|V|个k维行向量就分别表示|V|个单词的词向量了。
但是这种方法也存在很多问题,比如矩阵维度会经常变化(新词、语料库)、矩阵的稀疏性、维度很高、计算SVD很浪费时间、词频不平衡等等。
为了更好地解决上述问题,可以采用下面提到的基于迭代的方法。
3,基于迭代的词向量表示方法
前面都是直接根据全局数据计算共现矩阵,接下来尝试建立一个逐样本迭代训练的方法,并得到每个单词基于上下文的条件概率。
3.1,统计语言模型
一个句子(分词序列)的概率为:
P(w1,w2,w3…wn)
假设各单词出现完全独立,可以得到一元语言模型:
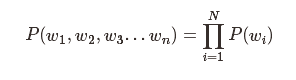
但往往一个词的出现都与其上下文有着紧密的关系,所以我们得到二元语言模型(2-gram):
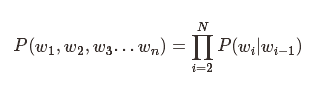
这就是我们常说的n-gram模型,n一般取3最好。太大了只会更复杂,而效果提升有限。
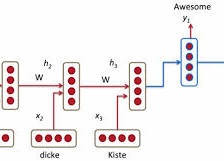
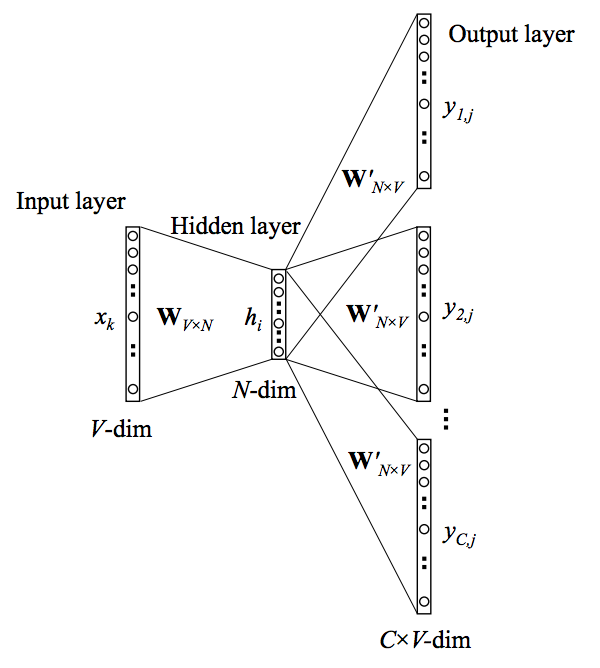
3.2,连续词袋模型(CBOW)
其实就是以上下文求出其中心词的概率,就叫做连续词袋模型。
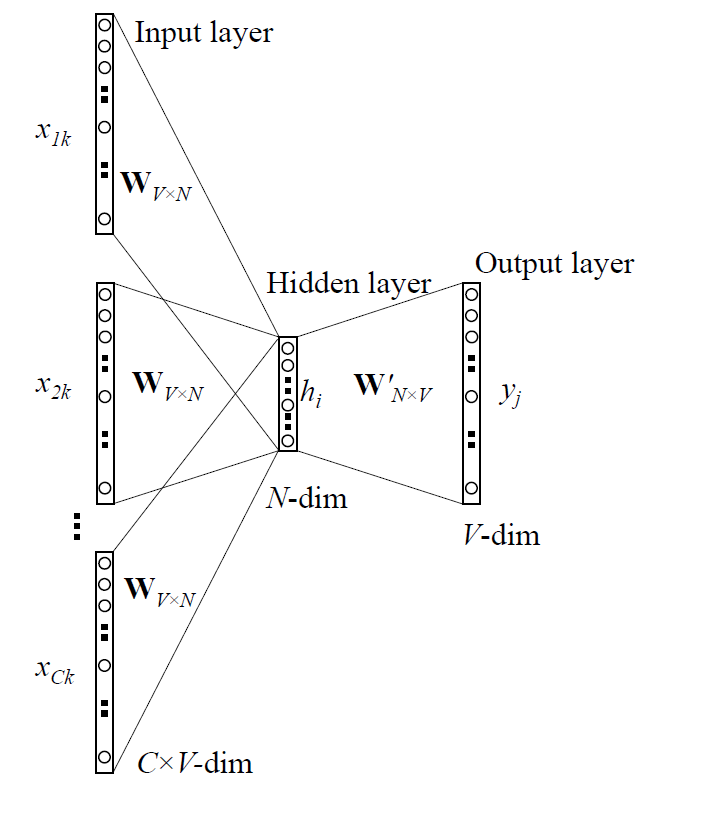
如上图所示,其实如果对NNLM模型有过了解的话,这里只不过是把隐层去掉了而已~~
不难发现其流程如下所示:
1,把大小为C的上下文中的每个单词用one-hot向量表示 (x(i−C),…,x(i−1),x(i+1),…,x(i+C));
2,分别用W与每个one-hot向量相乘,得到上下文对应的输入向量,例如 x(i−C)的输入向量u(i−C)=W(1)x(i−C)
3,将输入向量求平均h=(u(i−C)+u(i−C+1)+…+u(i+C))/2C
4,生成得分向量z=W’*h
5,利用softmax函数将得分转换成概率y^=softmax(z)
可以使用交叉熵来评判得分的好坏,所以损失函数为: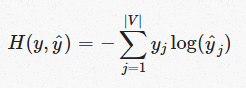
由于目标向量为one-hot向量,这里假设第i维是1,所以上述损失函数可以简化为: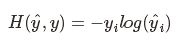
所以只有当预测结果yj=1时,H=0即损失函数为0。如果预测结果不正确,那么H=-log(yj)。所以问题转化为最小化损失函数:
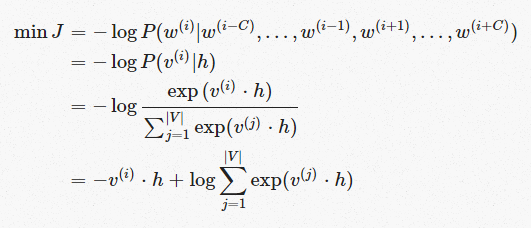
分别对v和h使用梯度下降法求偏导即可。
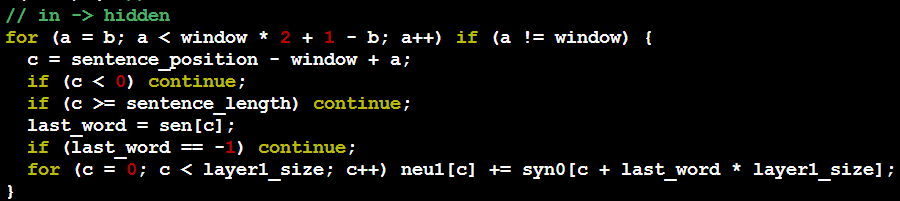
这里引入一下word2vec中的代码,来更方便的理解:
从输入层到隐层所进行的操作实际就是上下文向量的加和,具体的代码如下。其中 sentence_position 为当前 word 在句子中的下标。以一个具体的句子 A B C D为例,第一次进入到下面代码时当前 word 为 A,sentence_position 为 0。b 是一个随机生成的 0 到 window-1 的词,整个窗口的大小为(2*window + 1 – 2*b),相当于左右各看 window-b 个词。可以看出随着窗口的从左往右滑动,其大小也是随机的 3(b=window-1)到 2*window+1(b=0)之间随机变通,即随机值 b 的大小决定了当前窗口的大小。代码中的 neu1 即为隐层向量,也就是上下文(窗口内除自己之外的词)对应 vector 之和。
3.3, Skip-Gram模型
与CBOW类似,Skip-Gram是使用当前词预测窗口长度内其他词,即将输入输出与CBOW调换。
其步骤为:
1,输入one-hot向量x
2,x的输入向量表示为u(i)=W*x
3,因为只有一个输入所以不需要像CBOW一样对向量进行平均:h=u(i)
4,生成得分向量z=W’*h
5,利用softmax函数将得分转换成概率y^=softmax(z)
其他原理和思想都与CBOW类似(损失函数、求导等)。














 961
961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









