









接下来,这个商品详情页缓存架构,缓存预热问题和解决方案,缓存热点数据可能导致整个系统崩溃的问题,以及解决方案
缓存相关的「热」:预热、热数据
在解决方案和架构设计中,会引入大数据的实时计算的技术 storm。为什么要引入这个 storm,难道必须是 storm 吗?我们后面去讲解那个解决方案的时候再说
缓存架构和 storm 的关系
因为有些热点数据相关的一些实时处理的一些方案,比如快速预热,热点数据的实时感知和快速降级,全部要用到 storm
因为我们可能需要实时的去计算出热点缓存数据,我们的业务场景是亿级流量、高并发、大量的请求过来 ,这个时候,你要做一些实时的计算,那么必须涉及到分布式的一些技术,才能处理高并发,大量的请求,目前在时候计算的领域,最成熟的大数据的技术,就是 storm。
大公司里的很多 java 工程师,都是会用一些大数据的一些技术的,比如 storm、hbase、zookeeper、hive、spark, 因为在大公司里,容易遇到一些复杂的挑战和场景,比如高并发、海量数据的场景
java 系统与大数据的关系
大数据不仅仅只是大数据工程师要关注的东西, 大数据也是 Java 程序员在构建各类系统的时候一种全新的思维,以及架构理念, 比如 Storm、Hive、Spark、ZooKeeper、HBase、Elasticsearch 等等
举例说明:
-
Storm:实时计算
实时缓存热点数据统计 -> 缓存预热 -> 缓存热点数据自动降级
-
Hive:数据仓库
Hadoop 生态栈里面,比如做一个数据仓库的系统,高并发访问下,海量请求日志的批量统计分析,日报周报月报,接口调用情况,业务使用情况,等等
我所知,在一些大公司里面,是有些人是将海量的请求日志打到 hive 里面,做离线的分析,然后反过来去优化自己的系统
-
Spark:离线批量数据处理
比如从 DB 中一次性批量处理几亿数据,清洗和处理后写入 Redis 中供后续的系统使用,大型互联网公司的用户相关数据
-
ZooKeeper:分布式系统的协调
分布式锁,分布式选举->高可用 HA 架构,轻量级元数据存储
如:用 java 开发了分布式的系统架构,你的整套系统拆分成了多个部分,每个部分都会负责一些功能, 互相之间需要交互和协调;
服务 A 说:我在处理某件事情的时候,服务 B 你就别处理了
服务 A 说:我一旦发生了某些状况,希望服务 B 你立即感知到,然后做出相应的对策
-
HBase:海量数据的在线存储和简单查询,替代 MySQL 分库分表,提供更好的伸缩性
如:java 底层对应的是海量数据,然后要做一些简单的存储和查询,同时数据增多的时候要快速扩容
这种场景下 mysql 分库分表就不太合适了,mysql 分库分表扩容,还是比较麻烦的
-
Elasticsearch:海量数据的复杂检索以及搜索引擎的构建
支撑有大量数据的各种企业信息化系统的搜索引擎,电商/新闻等网站的搜索引擎,等等
比用 mysql 的 like "%xxxx%",更加合适一些,性能更加好
总结:
-
nginx、zookeeper、lua 主要讲解基于他们的一些架构和解决方案的设计,不会细讲
-
redis 花了很大的篇幅是因为高并发高可用底层是他来支撑,值得花时间来细讲
一个重点:数据库 + 缓存双写,多级缓存架构 重点理解方案设计和架构思想
-
storm 和 hystrix 比较重要
热数据处理和缓存雪崩需要依赖这两个技术;造就了系统可用性和稳定性
-
zookper 主要讲解了分布式锁,redis 也可做,所以不细讲
-
lua 脚本语言,自己查资料了解
storm 在做热数据这块,如果要做复杂的热数据的统计和分析,在亿级流量、高并发的场景下,我还真觉得,最合适的技术就是 storm,没有其他(成熟、稳定)
缓存架构、热数据相关的架构设计中最重要的唯一的可选技术 storm 会好好的去讲一下
后续会讲解 hystrix:提供分布式系统高可用性,限流、熔断、降级等措施;后续会讲解缓存雪崩方案,复杂的限流措施
接下来就讲解 stom 到底是什么?
mysq、hadoop 与 strom
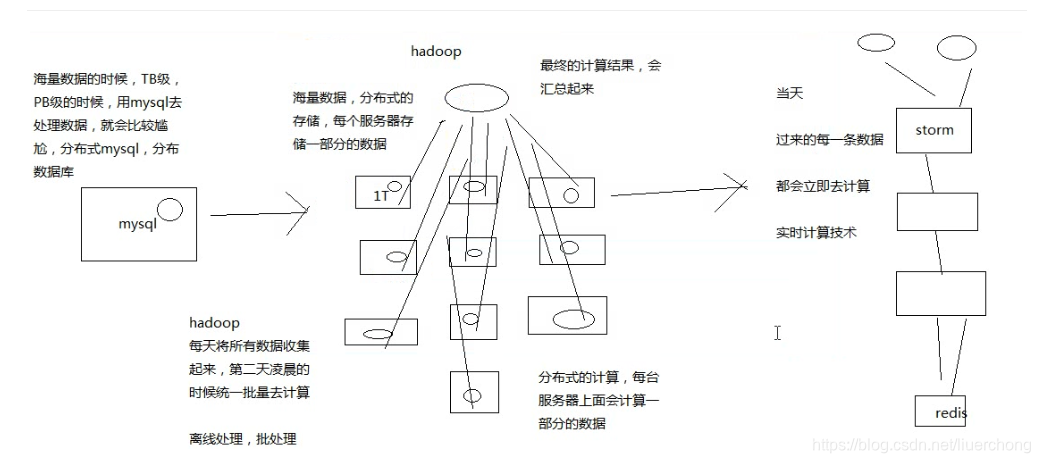
-
mysql:事务性系统,面临海量数据的尴尬
先不考虑分布式 mysql,因为技术还不成熟,实现起来也比较复杂
-
hadoop:离线批处理
-
strom:实时计算
2、我们能不能自己搞一套 storm?
实时计算:来一条数据,我理解就算一条,来一条,算一条
唯一的坑:海量高并发大数据,高并发的请求数据,分布式的系统,流式处理的分布式系统
如果自己搞一套实时流系统出来,也是可以的,但是。。。。
-
花费大量的时间在底层技术细节上:如何部署各种中间队列、节点间的通信、容错、资源调配、计算节点的迁移和部署,等等
-
花费大量的时间在系统的高可用上问题上:如何保证各种节点能够高可用稳定运行
-
花费大量的时间在系统扩容上:吞吐量需要扩容的时候,你需要花费大量的时间去增加节点,修改配置、测试,等等
如 5万/s 扩容到 10万/s,需要大两岁时间去增加节点测试
国内国产的实时大数据计算系统,唯一做出来的,做得好的,做得影响力特别大,特别牛逼的,就是 JStorm,但是阿里技术实力,可以说是世界一流,国内顶尖的
JStorm 原本是用 clojure 编程语言写的,阿里用 Java 重新写了一遍;后来又开发了一个 Galaxy 流式计算的系统;百度,腾讯,也都自己做了,也能做得很好, 但是一个普通程序员想做出来就真的太难了
storm 的特点是什么?
-
支撑各种实时类的项目场景
实时处理消息以及更新数据库,基于最基础的实时计算语义和 API(实时数据处理领域);对实时的数据流持续的进行查询或计算,同时将最新的计算结果持续的推送给客户端展示,同样基于最基础的实时计算语义和 API(实时数据分析领域);对耗时的查询进行并行化,基于 DRPC,即分布式 RPC 调用,如单表 30 天数据,并行化每个进程查询一天数据,最后组装结果
总之 storm 在实时类项目场景的时候都能很好的去支撑
-
高度的可伸缩性
如果要扩容,直接加机器,调整 storm 计算作业的并行度就可以了,storm 会自动部署更多的进程和线程到其他的机器上去,无缝快速扩容
扩容起来,超方便
-
数据不丢失的保证
storm 的消息可靠机制开启后,可以保证一条数据都不丢
数据不丢失,也不重复计算
-
超强的健壮性
从历史经验来看,storm 比 hadoop、spark 等大数据类系统,健壮的多的多,因为元数据全部放 zookeeper,不在内存中,随便挂都不要紧
特别的健壮,稳定性和可用性很高
-
使用的便捷性:核心语义非常的简单,开发起来效率很高
用起来很简单,开发 API 还是很简单的
Storm 的集群架构
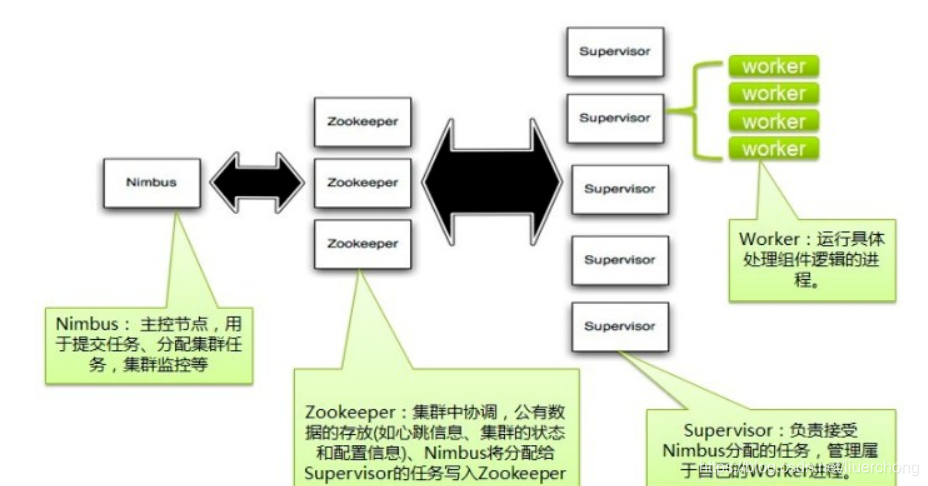
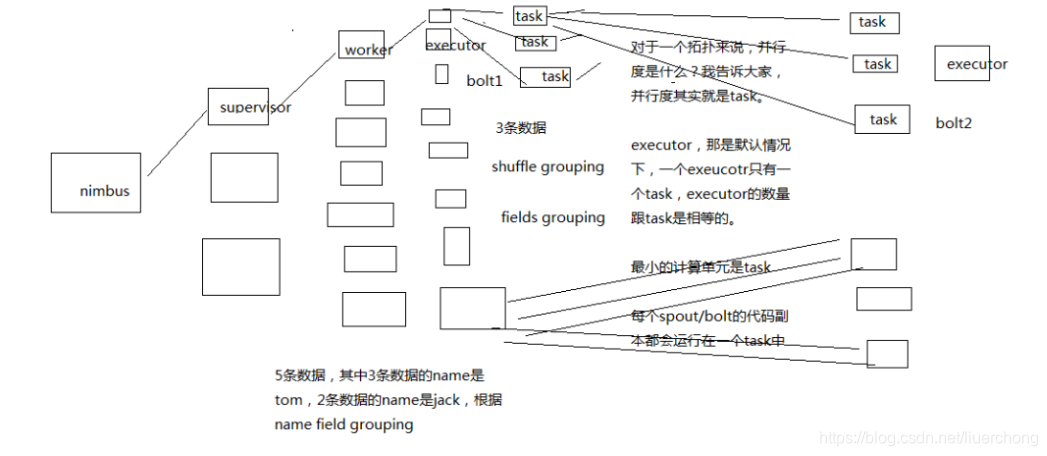
Nimbus、Supervisor、ZooKeeper、Worker、Executor、Task
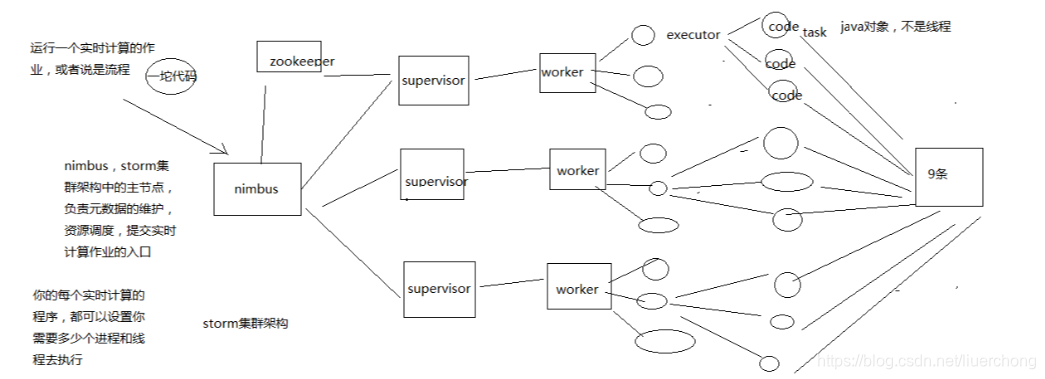
-
Nimbus:资源调度
-
Supervisor:相当于一台机器上的代理管家
-
ZooKeeper:用于存放 Nimbus 和 Supervisor 的调度元数据信息
-
Worker:根据配置可启动多个 worker 进程
-
Executor:根据配置可启动多个线程
-
Task:就是业务代码,不是线程,可能就是 stom 中你需要实现的业务代码
整体架构流程如图:一个事实计算作业启动后,Nimbus 通知 Supervisor 去启动 n 个 Worker,Worker 又启动 n 个 Executor,Executor 执行具体的 业务代码
Storm 的核心概念
Topology、Spout、Bolt、Tuple、Stream
-
Topology(拓扑):虚的抽象的概念
-
Spout:数据源代码组件
可以理解为:用 java 实现一个 Spout 接口,在该代码中尝试去数据源获取数据,如 mysql、kafka
-
Bolt:业务处理代码组件
可以理解为:spout 会将数据传送给 bolt,各种 bolt 还可以串联成一个计算链条,同样是实现一个 bolt 接口
一堆 spout + bolt,就会组成一个 topology(拓扑),也可以叫做一个实时计算作业;
一个拓扑涵盖数据源获取/生产 + 数据处理的所有的代码逻辑
-
Tuple:一条数据
每条数据都会被封装在 tuple 中,在多个 spout 和 bolt 之间传递
-
Stream:一个流
虚的抽象的概念,源源不断过来的 tuple,就组成了一条数据流
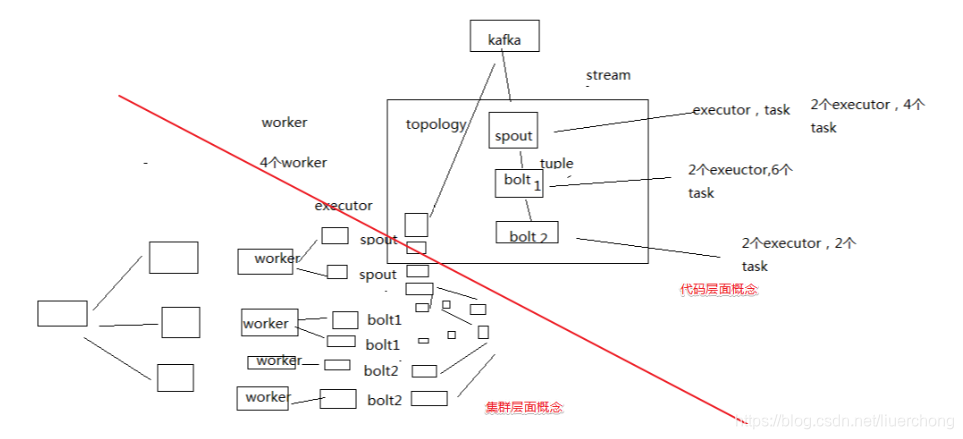
了解了核心的基本概念之后,上图清晰的示意了他们是怎么配合工作的, 业务代码层面的概念通过配置,被调度到具体的机器上的集群概念中去执行
对于 java 工程师来说,达到的一个效果如下:
-
对 storm 的核心的基本原理要清楚:集群架构、核心概念、并行度和流分组
-
掌握最常见的 storm 开发范式
spout 消费 kafka,后面跟一堆 bolt,bolt 之间设定好流分组的策略, bolt 中填充各种代码逻辑
-
了解如何将 storm 拓扑打包后提交到 storm 集群上去运行
-
掌握如何能够通过 storm ui 去查看你的实时计算拓扑的运行现状
如果你所在公司有大数据团队并且维护了一个 storm 集群,那么掌握如何开发和部署即可, 如果没有,那么你就需要去深入学习下 storm 了。如果你的场景不是特别复杂, 整个数据量也不是特别大,其实自己主要研究一下,怎么部署 storm 集群也可以,
Storm 的并行度以及流分组是重要的一个概念。
用一句话讲清楚什么是并行度,什么是流分组, 你自己随便设想一个拓扑结果出来, 几个 spout,几个 bolt,各种流分组情况下,数据是怎么流向的,要求具体画出集群架构中的流向, worker,executor,task,supervisor,数据是怎么流转的;
那么这里一句话总结:
-
并行度:Worker->Executor->Task,没错,是 Task
默认情况下,一个 Executor 对应一个 Task
简单说就是 task 越多,并行度越高
-
流分组:Task 与 Task 之间的数据流向关系
一个拓扑中,可以有很多 Spout + Bolt,那么 bolt1 的数据流向 bolt2 的时候的一个策略 就是流分组
流分组策略:
-
Shuffle Grouping:随机发射,负载均衡
-
Fields Grouping:根据一个或多个字段进行分组
那一个或者多个 fields 如果值完全相同的话,那么这些 tuple,就会发送给下游 bolt 的其中固定的一个 task
你发射的每条数据是一个 tuple,每个 tuple 中有多个 field 作为字段
比如 tuple 3 个字段,name,age,salary
{"name": "tom", "age": 25, "salary": 10000}-> tuple -> 3个 field,name,age,salary -
All Grouping:广播分发
-
Global Grouping:选择其中一个 task 最小的 id 分发
-
None Grouping:与 shuffle 类似
-
Direct Grouping:指定一个 task id 发送
-
Local or Shuffle Grouping: 只在本地同一个进程(worker)中国随机分发
最常用的是前两种
-
手敲 WordCount 程序
编写代码
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.TimeUnit;
import java.util.logging.Logger;
/**
* <pre>
* 需求:统计一些句子中单词出现的次数
* </pre>
*
*/
public class WordCountTopology {
/**
* 定义一个数据源;这里直接伪造一个假数据
*/
public static class RandomSentenceSpout extends BaseRichSpout {
private static Logger logger = Logger.getLogger(RandomSentenceSpout.class.getName());
private Random random;
private SpoutOutputCollector collector;
private String[] sentences;
/**
* <pre>
* 对 spout 进行初始化工作
* 比如:创建一个线程池、创建一个数据库连接、构造一个 httpclient
* </pre>
*
* @param collector 数据写出对象
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
random = new Random();
this.collector = collector;
sentences = new String[]{"the cow jumped over the moon",
"an apple a day keeps the doctor away",
"four score and seven years ago",
"snow white and the seven dwarfs",
"i am at two with nature"};
logger.info("RandomSentenceSpout open");
}
/**
* <pre>
* 本类(Spout)最终会运行在 task 中,某个 worker 进程的某个 executor 线程内部的某个 task 中
* 该 task 会负责无限循环调用 nextTuple 方法
* 就可以达到不断的发射最新的数据,形成一个数据流
* </pre>
*/
@Override
public void nextTuple() {
Utils.sleep(2000);
String sentence = this.sentences[random.nextInt(this.sentences.length)];
System.err.println("RandomSentenceSpout sentence:" + sentence);
collector.emit(new Values(sentence));
}
/**
* <pre>
* 定义发射出去的每个 tuple 中的每个 field 的名称是什么?
* 这里只有一个值,只需要写一个字段名称
* </pre>
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
}
/**
* <pre>
* 定义一个 bolt ,用于对数据的加工,
* 这里拆分接收到的句子,拆分成一个一个的单词
* </pre>
*/
public static class SplitSentence extends BaseRichBolt {
private OutputCollector collector;
/**
* 该类初始化方法,这里可以拿到发射器
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* 每接收到一条数据,就会调用该方法,进行加工处理
*/
@Override
public void execute(Tuple input) {
String sentence = input.getStringByField("sentence");
for (String word : sentence.split(" ")) {
// 拆分成一个一个单词之后,再发射出去
collector.emit(new Values(word));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 定义发数据的字段名称
declarer.declare(new Fields("word"));
}
}
/**
* 在定义一个 bolt ,用于对单词的统计
*/
public static class WordCount extends BaseRichBolt {
private OutputCollector collector;
/**
* 用来存储每个单词的统计数量
*/
private Map<String, Integer> counts;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.counts = new HashMap<>();
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = counts.get(word);
if (count == null) {
count = 1;
counts.put(word, count);
}
counts.put(word, ++count);
System.err.println(Thread.currentThread().getName() + "WordCount word:" + word + ", count :" + count);
collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("wordk", "count"));
}
}
public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException, InterruptedException {
// 构建拓扑,也就是手动定义业务流程
// 其他的提交到 storm 集群后,由 storm 去调度在哪些机器上启动你所定义的 拓扑
TopologyBuilder builder = new TopologyBuilder();
// id、spout、并发数量
builder.setSpout(RandomSentenceSpout.class.getSimpleName(),
new RandomSentenceSpout(), 2);
builder.setBolt(SplitSentence.class.getSimpleName(),
new SplitSentence(), 5)
// 默认是一个 executor 一个 task
// 这里设置 5 个 executor,但是 task 设置了 10 个,相当于 每个 executor 2 个 task
.setNumTasks(10)
// 配置该 bolt 以何种方式从哪里获取数据
.shuffleGrouping(RandomSentenceSpout.class.getSimpleName());
builder.setBolt(WordCount.class.getSimpleName(),
new WordCount(), 5)
.setNumTasks(10)
// 配置按字段形式去 SplitSentence 中获取数据
// 相同的单词始终都会被发射到同一个 task 中去
.fieldsGrouping(SplitSentence.class.getSimpleName(), new Fields("word"));
// 上面代码配置有点像是主动获取数据,实际上是被动接受吗?
Config conf = new Config();
conf.setDebug(false);
if (args != null && args.length > 0) {
// 表示在命令行中运行的,需要提交的 storm 集群中去
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
} else {
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
TimeUnit.SECONDS.sleep(10);
cluster.shutdown();
}
}
}
运行后输出日志
RandomSentenceSpout sentence:snow white and the seven dwarfs
Thread-28-WordCount-executor[6 6]WordCount word:snow, count :2
Thread-22-WordCount-executor[7 7]WordCount word:the, count :2
Thread-18-WordCount-executor[8 8]WordCount word:and, count :2
Thread-28-WordCount-executor[6 6]WordCount word:white, count :2
Thread-18-WordCount-executor[8 8]WordCount word:dwarfs, count :2
Thread-28-WordCount-executor[6 6]WordCount word:seven, count :2
RandomSentenceSpout sentence:an apple a day keeps the doctor away
Thread-18-WordCount-executor[8 8]WordCount word:a, count :2
Thread-22-WordCount-executor[7 7]WordCount word:an, count :2
Thread-28-WordCount-executor[6 6]WordCount word:apple, count :2
Thread-22-WordCount-executor[7 7]WordCount word:day, count :2
Thread-28-WordCount-executor[6 6]WordCount word:keeps, count :2
Thread-22-WordCount-executor[7 7]WordCount word:the, count :3
Thread-28-WordCount-executor[6 6]WordCount word:doctor, count :2
Thread-28-WordCount-executor[6 6]WordCount word:away, count :2
RandomSentenceSpout sentence:an apple a day keeps the doctor away
Thread-18-WordCount-executor[8 8]WordCount word:a, count :3
Thread-22-WordCount-executor[7 7]WordCount word:an, count :3
Thread-28-WordCount-executor[6 6]WordCount word:apple, count :3
Thread-22-WordCount-executor[7 7]WordCount word:day, count :3
Thread-28-WordCount-executor[6 6]WordCount word:keeps, count :3
Thread-22-WordCount-executor[7 7]WordCount word:the, count :4
Thread-28-WordCount-executor[6 6]WordCount word:doctor, count :3
Thread-28-WordCount-executor[6 6]WordCount word:away, count :3
RandomSentenceSpout sentence:snow white and the seven dwarfs
Thread-18-WordCount-executor[8 8]WordCount word:and, count :3
Thread-28-WordCount-executor[6 6]WordCount word:snow, count :3
Thread-22-WordCount-executor[7 7]WordCount word:the, count :5
Thread-28-WordCount-executor[6 6]WordCount word:white, count :3
Thread-18-WordCount-executor[8 8]WordCount word:dwarfs, count :3
Thread-28-WordCount-executor[6 6]WordCount word:seven, count :3
RandomSentenceSpout sentence:the cow jumped over the moon
Thread-22-WordCount-executor[7 7]WordCount word:the, count :6
Thread-28-WordCount-executor[6 6]WordCount word:cow, count :2
Thread-28-WordCount-executor[6 6]WordCount word:jumped, count :2
Thread-22-WordCount-executor[7 7]WordCount word:over, count :2
Thread-22-WordCount-executor[7 7]WordCount word:the, count :7
Thread-22-WordCount-executor[7 7]WordCount word:moon, count :2
RandomSentenceSpout sentence:the cow jumped over the moon
Thread-22-WordCount-executor[7 7]WordCount word:the, count :8
Thread-28-WordCount-executor[6 6]WordCount word:cow, count :3
Thread-22-WordCount-executor[7 7]WordCount word:over, count :3
Thread-28-WordCount-executor[6 6]WordCount word:jumped, count :3
Thread-22-WordCount-executor[7 7]WordCount word:the, count :9
Thread-22-WordCount-executor[7 7]WordCount word:moon, count :3从上面的输出日志来看,Thread-28-WordCount-executor[6 6] 中每次都是处理 snow, 这里需要注意下,应该这样说,snow 每次都在 28-6-6 上被处理,因为当单词种类大于 maxtask 配置的时候, 其实一个 task 会处理多个单词的,但是能保证相同的单词一定会落在同一个线程中

















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









