







第一:微服务注册中心的注册表如何更好的防止读写并发冲突?
首先介绍一下读写锁
代码使用
一、读写锁的介绍
本文我们来聊一下读写锁。所谓的读写锁,就是将一个锁拆分为读锁和写锁两个锁,然后加锁的时候,可以加写锁,也可以加读锁。
如下面代码所示:
private ReadWriteLock rwl = new ReentrantReadWriteLock();//定义读写锁
public Object getData(String key){
//使用读写锁的基本结构
rwl.readLock().lock();
Object value = null;
try{
value = cache.get(key);
if(value == null){
rwl.readLock().unlock();
rwl.writeLock().lock();
try{
// Recheck state because another thread might have
// acquired write lock and changed state before we did.
if(value == null){
value = "aaaa";//写入数据
}
}finally{
rwl.writeLock().unlock();
}
rwl.readLock().lock();
}
}finally{
rwl.readLock().unlock();
}
return value;
}
如果有一个线程加了写锁,那么其他线程就不能加写锁了,同一时间只能允许一个线程加写锁。
因为加了写锁就意味着有人要写一个共享数据,那同时就不能让其他人来写这个数据了。
如果有线程加了写锁,其他线程就不能加读锁了,因为既然都有人在写数据了,你其他人当然不能来读数据了!
如果有一个线程加了读锁,别的线程是可以同时加读锁的,因为只是有线程在读数据而已,此时别的线程也是可以来读数据的!
同理,如果一个线程加了读锁,此时其他线程是不可以加写锁的,因为既然有人在读数据,那就不能让你随意来写数据了!
我们知道一个微服务注册中心(可以是Eureka或者Consul或者你自己写的一个微服务注册中心)肯定会在内存中有一个服务注册表的概念。
这个服务注册表中存放了各个微服务注册时发送过来的自己的地址信息,里面保存了每个服务有多少个服务实例,每个服务实例部署在哪台机器上监听哪个端口号,主要是这样的一些信息
那现在问题来了,这个服务注册表的数据,其实是有人读也有人写的?
举个例子,比如有的服务启动的时候会来注册,此时就会修改服务注册表的数据,这个就是写的过程。
接着,别的服务也会来读这个服务注册表的数据,因为每个服务都需要感知到其他服务在哪些机器上部署。
所以,这个内存里的服务注册表数据,天然就是有读写并发问题的!可能会有多个线程来写,也可能会有多个线程来读!
如果你对同一份内存中的注册表数据不加任何保护措施,那么可能会有多线程并发修改共享数据的问题,可能导致数据错乱,
加上synchronized,直接让所有线程对服务注册表的读写操作,全部串行化。那不就可以保证内存中的服务注册表数据安全了吗?
因为这么搞的话,相当于是所有的线程读写服务注册表数据,全部串行化了。
其实我们所实现的就是在有人往服务注册表里写数据的时候,就不让其他人写了,同时也不让其他人读!
然后,有人在读服务注册表的数据的时候,其他人都可以随便同时读,但是此时不允许别人写服务注册表数据了!
想清楚了这点,我们就不应该暴力的加一个synchronized,让所有读写线程全部串行化,因为那样会导致并发性非常的低。
大家看看下面的图,我们想要的第一个效果:一旦有人在写服务注册表数据,我们加个写锁,此时别人不能写,也不能读。
如果有人在读数据呢?此时就可以让别人都可以读,但是不允许任何人写。
关键点来了,这样做有什么好处呢?
其实大部分时候都是读操作,所以使用读锁可以让大量的线程同时来读数据,不需要阻塞不需要排队,保证高并发读的性能是比较高的。
然后少量的时候是有服务上线要注册数据,写数据的场景是比较少的
此时写数据的时候,只能一个一个的加写锁然后写数据,同时写数据的时候就不允许别人来读数据了。
因此读写锁非常适合这种读多写少的场景的。
另外,我们能不能尽量在写数据期间还保证可以继续读数据呢?大量加读锁的时候,会阻塞人家写数据加写锁过长时间,这种情况能否避免呢?
可以的,采用多级缓存的机制,下面介绍
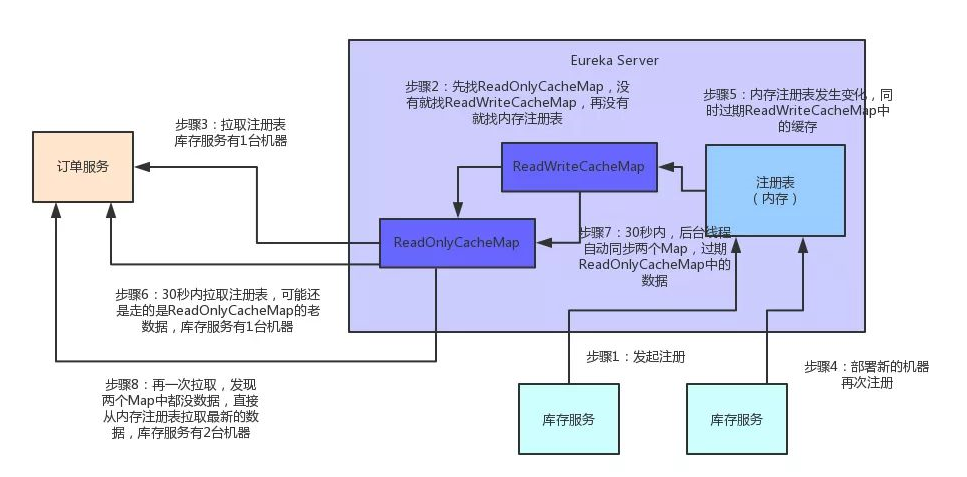
第二:Eureka注册表多级缓存架构有了解过吗?
假设Eureka Server部署在4核8G的普通机器上,那么基于内存来承载各个服务的请求,每秒钟最多可以处理多少请求呢?
-
单台4核8G的机器,处理纯内存操作,哪怕加上一些网络的开销,每秒处理几百请求也是轻松加愉快的。
-
而且Eureka Server为了避免同时读写内存数据结构造成的并发冲突问题,还采用了多级缓存机制来进一步提升服务请求的响应速度。
-
在拉取注册表的时候:
-
首先从ReadOnlyCacheMap里查缓存的注册表。
-
-
-
若没有,就找ReadWriteCacheMap里缓存的注册表。
-
-
-
如果还没有,就从内存中获取实际的注册表数据。
-
-
在注册表发生变更的时候:
-
会在内存中更新变更的注册表数据,同时过期掉ReadWriteCacheMap。
-
-
-
此过程不会影响ReadOnlyCacheMap提供人家查询注册表。
-
-
-
一段时间内(默认30秒),各服务拉取注册表会直接读ReadOnlyCacheMap
-
-
-
30秒过后,Eureka Server的后台线程发现ReadWriteCacheMap已经清空了,也会清空ReadOnlyCacheMap中的缓存
-
-
-
下次有服务拉取注册表,又会从内存中获取最新的数据了,同时填充各个缓存。
-
多级缓存机制的优点是什么?
-
尽可能保证了内存注册表数据不会出现频繁的读写冲突问题。
-
并且进一步保证对Eureka Server的大量请求,都是快速从纯内存走,性能极高。
为方便大家更好的理解,同样来一张图,大家跟着图再来回顾一下这整个过程:
第三:Nacos如何支撑阿里巴巴内部上百万服务实例的访问?
nacos和Eureka对比
public void register(InstanceInfo registrant, int leaseDuration, boolean isReplication) {
try {
// 加读锁
read.lock();
// 获得微服务组
Map<String, Lease<InstanceInfo>> gMap = registry.get(registrant.getAppName());
// 根据传入的id获得服务实例
Lease<InstanceInfo> existingLease = gMap.get(registrant.getId());
// 如果存在则赋值给registrant
if (existingLease != null && (existingLease.getHolder() != null)) {
Long existingLastDirtyTimestamp = existingLease.getHolder().getLastDirtyTimestamp();
Long registrationLastDirtyTimestamp = registrant.getLastDirtyTimestamp();
if (existingLastDirtyTimestamp > registrationLastDirtyTimestamp) {
registrant = existingLease.getHolder();
}
} else {
// 不存在,记录数量
synchronized (lock) {
if (this.expectedNumberOfRenewsPerMin > 0) {
this.expectedNumberOfRenewsPerMin = this.expectedNumberOfRenewsPerMin + 2;
this.numberOfRenewsPerMinThreshold =
(int) (this.expectedNumberOfRenewsPerMin * serverConfig.getRenewalPercentThreshold());
}
}
}
// 使用registrant创建Lease
// 会记录registrationTimestamp(服务注册时间)
// lastUpdateTimestamp(最后操作时间) duration(失效时间数)
Lease<InstanceInfo> lease = new Lease<InstanceInfo>(registrant, leaseDuration);
if (existingLease != null) {
// 设置恢复正常时的状态
lease.setServiceUpTimestamp(existingLease.getServiceUpTimestamp());
}
// 放入微服务组中
gMap.put(registrant.getId(), lease);
} finally {
read.unlock();
}Eureka是同步去注册的,注册时加读锁,Nacos注册时直接入队列,异步线程去进行注册,注册时使用CopyOnWrite空间换时间,提升注册并发
服务发现对比
Nacos获取服务实例直接取自ephemeralInstances,Eureka服务注册和发现时会加锁,为了降低锁竞争,有三级缓存
// 无过期时间,保存服务信息的对外输出数据结构,定时从二级缓存拉取注册信息
private final ConcurrentMap<Key, Value> readOnlyCacheMap = new ConcurrentHashMap<Key, Value>();
// 为了降低注册表registry读写锁竞争,降低读取频率,本质上是 guava 的缓存,包含定时失效机制
private final LoadingCache<Key, Value> readWriteCacheMap;
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry
= new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();读取顺序:只读缓存->读写缓存->真实数据
只读缓存的数据只会来源于读写缓存,而且没有提供主动更新API。
读写缓存是使用Guava实现的,本身设置了 guava 的失效机制,隔一段时间后自己自动失效。
定时更新一级缓存的时候,会读取二级缓存,如果二级缓存没有数据,也会触发load,拉取registry的注册数据。
第四:Nacos高并发异步注册架构知道如何设计的吗?
nacos服务注册流程
nacos的客户端已经搭建好了,那么客户端是怎么将服务注册到注册中心去的呢。
1、 如果对springboot自动配置原理有一定了解的话,那么第三方框架一般都会通过spi的方式来初始化自己包中的bean。比如mybatis与spring结合都会在/META-INFO/spring.factories下进行自动装配
2、 那么nacos是不是一样的也是基于这种方式来处理的呢,打开nacos客户端的依赖包,看到/META-INFO下面存在spring.factories
3、 打开spring.factories可以看到里面的确存在一些nacos的自动配置信息。
4、 那这些自动配置的类都是些什么意思呢,都起到了些什么作用呢,一个一个点击进去查看一下,点击第一个 com.alibaba.cloud.nacos.NacosDiscoveryAutoConfiguration发现当中对三个对象进行了装载NacosServiceRegistry、NacosRegistration、NacosAutoServiceRegistration
5、 NacosServiceRegistry是不是就是封装的nacos注册流程呢,点击进去查看,发现好像还真的是nacos客户端的注册流程:
NacosServiceRegistry.register()–>namingService.registerInstance()–>serverProxy(NamingProxy).registerService()–>NamingProxy.reqAPI()–>NamingProxy.callServer()–>HttpClient.request();
这样最终发现nacos客户端的最终是通过http去请求一个服务端的注册接口。
6、 从上面的nacos注册流程当中可以知道,其入口是NacosServiceRegistry中的register方法,那么register又是怎么调用的呢,这里里面需要涉及到spring的事件发布与订阅、springcloud当中对服务注册流程所制定的标准,只有对这方面的知识有了一定程度的了解才能知道使用nacos作为注册中心时客户端进行注册的整个流程,才能进一步的去学习并了解nacos的源码。
7、 那么对于作为小白的我对这些东西都不熟悉,都不知道,那我怎么才能搞懂nacos客户端的整个注册流程呢,idea的调试模式下为我们提供了强大的调用链路,我们只需要在NacosServiceRegistry的register()方法上打个断点。
8、 调试启动项目,这样idea的调试工具当中会出现整个注册流程的调用链路
9、 根据调用链路可以整理出整个nacos作为注册中心时客户端的调用流程
第一步:springboot在启动main方法时调用到spring的核心方法refresh
第二步: spring的refresh方法会在最后的流程中finishRefresh(),
而由于是Springboot的方式启动时初始化的applictionContext是AnnotationConfigServletWebServerApplicationContext,并且该类是继承于ServletWebServerApplicationContext,ServletWebServerApplicationContext重写了finishRefresh方法,Spring在调用finishRefresh最终会调到子类的ServletWebServerApplicationContext当中的finishRefresh方法。
第三步:ServletWebServerApplicationContext在处理完父类的finishRefresh的时候会去发布一个ServletWebServerInitializedEvent事件,该事件继承于WebServerInitializedEvent,而最终nacos就是去监听该事件来进行注册的
第四步:spring在发送事件之后最终由AbstractApplicationContext将该事件交给ApplicationEventMulticaster将事件广播到适定的监听器。
第五步:AbstractApplicationContext的实现类SimpleApplicationEventMulticaster当中的multicastEvent中会去获取当前处理该事件的所有的监听器,并执行最终的事件处理
第六步:最后根据注册的事件,该事件的对应的监听器会实现onApplicationEvent方法,调到对应的实现上,AbstractAutoServiceRegistration会去监听前面所提到的WebServerInitializedEvent事件,最终会调到 AbstractAutoServiceRegistration中的onApplicationEvent方法
第七步:AbstractAutoServiceRegistration经过一系列的跳转调用最终调用到ServiceRegistry中的register方法。而ServiceRegistry.register实际上就是spring cloud为各个注册中心所制定的标准,要想使服务注册,那么须各个注册中心的客户端去实现该方法
第八步:在这里nacos的注册流程就完全的清楚了,由于使用了唯一的注册中心nacos,而恰巧nacos的注册流程是通过NacosServiceRegistry实现的,这里最终就调用到了nacos的注册流程。
第九步:nacos的注册流程已经走完了,其实还有个疑问,那么spring cloud中AbstractAutoServiceRegistration又是怎么初始话的呢,翻开spring cloud common的/META-INFO/spring.factories中配置AutoServiceRegistrationAutoConfiguration,
而通过该类对AbstractAutoServiceRegistration进行了初始化。
最后说一下:对现有常用的注册中心 erueka、zookeeper、consul 最终都是通过ServiceRegistry的实现类来处理register来完成整个客户端的注册。稍微翻看了以上几个注册中心客户端注册流程的代码,发现zookeeper、consul,nacos都是通过事件的发布与监听来处理最终流程,但是erueka是LifecycleProcessor来实现服务注册的。
第五:Sentinel底层滑动时间窗限流算法怎么实现的?
其实sentinel核心原理并不难理解,就是在访问被保护资源时,根据实时的统计信息和预先定义的规则,检查是否可以访问。对我自己而言,可能统计的算法是比较关心的,都知道sentinel的统计算法是滑动时间窗口算法。
探索
说这个算法主要要解决什么事呢?就是说在某个时间间隔要做点统计,比如说现在时间是16:06:21,320,我现在想知道16:06:21,000-16:06:21,320我的应用app通过了多少个请求,即当前的320ms通过了多少请求?
sentinel时间窗口

就如图片展示的,想统计一段时间内的数据,就定义一个WindowWrap(时间窗口)来实现,在时间轴上随着时间的流逝,会有无限多连续的时间窗口,时间窗口通过MetricBucket来统计数据,都统计什么数据呢,MetricEvent定义了相关的统计数据类型,不同的统计数据类型由一个LongAdder来计数,这样在请求到来的时候先根据当前时间戳定位时间窗口,由当前的时间窗口来记录需要统计的信息,至于LeapArray是怎么回事,代码逻辑比较容易理解,但是设计意图在这里还不是特别清晰,可以看看其sampleCount这个属性,应该能有所猜测,再多的可以到下文再仔细品味下。
上代码,不详细说为什么代码执行流程了,就看看关键的代码。
public class{
private final LeapArray<MetricBucket> data;
public void addPass(int count) {
WindowWrap<MetricBucket> wrap = data.currentWindow();
wrap.value().addPass(count);
}
}
public abstract class LeapArray{
public WindowWrap<T> currentWindow(long timeMillis) {
if (timeMillis < 0) {
return null;
}
//计算当前时间在数组中的位置
int idx = calculateTimeIdx(timeMillis);
//计算当前时间窗口的开始时间
long windowStart = calculateWindowStart(timeMillis);
while (true) {
//在数组中获取时间窗口,注意这里的old是说时间窗口已经创建过了
WindowWrap<T> old = array.get(idx);
//如果没有就搞一个新的时间窗口
if (old == null) {
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
if (array.compareAndSet(idx, null, window)) {
return window;
} else {
Thread.yield();
}
//如果开始时间等于old的开始时间就把old返回
} else if (windowStart == old.windowStart()) {
return old;
//如果大于old开始时间,就重置
} else if (windowStart > old.windowStart()) {
if (updateLock.tryLock()) {
try {
return resetWindowTo(old, windowStart);
} finally {
updateLock.unlock();
}
} else {
Thread.yield();
}
} else if (windowStart < old.windowStart()) {
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
}
}
}
public class MetricBucket {
public MetricBucket add(MetricEvent event, long n) {
//找到对应的事件LongAdder递增
counters[event.ordinal()].add(n);
return this;
}
}
结合代码又进一步了解了sentinel的滑动时间窗口算法,一段时间(事件窗口)+统计对象,即时间在时间窗口中滑动并作数据统计。那统计完咋用的啊?那就再看看。
public class StatisticNode implements Node {
public long totalPass() {
return rollingCounterInMinute.pass();
}
}
public class ArrayMetric implements Metric {
public long pass() {
data.currentWindow();
long pass = 0;
List<MetricBucket> list = data.values();
for (MetricBucket window : list) {
pass += window.pass();
}
return pass;
}
}
public class MetricBucket {
public long pass() {
return get(MetricEvent.PASS);
}
public long get(MetricEvent event) {
return counters[event.ordinal()].sum();
}
}
这就明白了,不就是找在固定时间间隔内所有时间窗口样本的统计数据嘛,还记得sampleCount(LeapArray)吗?好像有点内味了,再看看qps。
public class StatisticNode implements Node {
public double passQps() {
return rollingCounterInSecond.pass() / rollingCounterInSecond.getWindowIntervalInSec();
}
}
qps=所有样本请求通过数/固定时间间隔,呦,这么一看我可以把时间间隔搞得小一点比如(500ms,默认1000ms),那样本数我也不搞那么多,我让窗口长度就是500,那统计qps的时候就是1个500ms的qps。
第六:Sentinel底层是如何计算线上系统实时QPS的?
第七:Seata分布式事务回滚机制如何实现的?
第八:Nacos集群CP架构底层类Raft协议怎么实现的?
第九:Nacos&Eureka&Zookeeper集群架构都有脑裂问题吗?
第十:如何设计能支撑全世界公司使用的微服务云架构?















 1990
1990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









