







因为工作中涉及到了部分人工智能技术的问题,特别是时间序列预测的问题,所以本人最近开始学习人工智能。本文是我再学习过程中的一些笔记,内容大部分来自于网络,加上了自己的一些想法和思考,以及一些实例,请各位高手批评指正。
一、前言
首先应该感谢这篇文章将我带入门,这篇文章写图文并茂,是非常不粗错的文章,不过需要一定的神经网络知识基础。:LSTM详解 .
在进入到LSTM的讲解之前,我们先来了解一下,为什么会出现LSTM,它的出现是解决什么问题的。
1.1 Recurrent Neural Networks (RNN)
循环神经网络(Recurrent Neural Networks, RNN) 是一种常用的神经网络结构,它源自于1982年由Saratha Sathasivam提出的霍普菲尔德网络。
RNN背后的想法是利用顺序信息。在传统的神经网络中,我们假设所有输入(和输出)彼此独立。但对于许多任务而言,这是一个非常糟糕的想法。如果你想预测句子中的下一个单词,那你最好知道它前面有哪些单词。RNN被称为"循环",因为它们对序列的每个元素执行相同的任务,输出取决于先前的计算。考虑RNN的另一种方式是它们有一个“记忆”,它可以捕获到目前为止计算的信息。理论上,RNN可以利用任意长序列中的信息,但实际上它们仅限于回顾几个步骤。

其中,
(1)Xt是输入层的输入;
(2)St是隐藏层的输出,其中S0是计算第一个隐藏层所需要的,通常初始化为全零;
(3)ht是输出层的输出。
RNN的数学表达式可以表示为:
RNN之所以在时序数据上有着优异的表现是因为RNN在时间片时会将时间片的隐节点作为当前时间片的输入,这样有效的原因是之前时间片的信息也用于计算当前时间片的内容,而传统模型的隐节点的输出只取决于当前时间片的输入特征。

我们以NLP常见的序列标注问题为例,h表示一个状态,也就是我们想要的输出,句子被word embedding之后,顺序进入模型,在参数矩阵A的作用下,其中h_0包含the这个词的信息,h_1包含the 和cat 两个词的信息,最后到h_t之后,就包含所有句子的信息。大家很快就能发现问题:句子很长之后就会出现梯度消失的问题,ht包含第一个字符x_0的信息很少很少。
RNN的缺点:梯度消失/爆炸
梯度消失和梯度爆炸是困扰RNN模型训练的关键原因之一,产生梯度消失和梯度爆炸是由于RNN的权值矩阵循环相乘导致的,相同函数的多次组合会导致极端的非线性行为。梯度消失和梯度爆炸主要存在RNN中,因为RNN中每个时间片使用相同的权值矩阵。对于一个DNN,虽然也涉及多个矩阵的相乘,但是通过精心设计权值的比例可以避免梯度消失和梯度爆炸的问题。
处理梯度爆炸可以采用梯度截断的方法。所谓梯度截断是指将梯度值超过阈值θ的梯度手动降到θ。虽然梯度截断会一定程度上改变梯度的方向,但梯度截断的方向依旧是朝向损失函数减小的方向。
对比梯度爆炸,梯度消失不能简单的通过类似梯度截断的阈值式方法来解决,因为长期依赖的现象也会产生很小的梯度。在上面例子中,我们希望 t9 时刻能够读到 t1 时刻的特征,在这期间内我们自然不希望隐层节点状态发生很大的变化,所以 [t2,t8] 时刻的梯度要尽可能的小才能保证梯度变化小。很明显,如果我们刻意提高小梯度的值将会使模型失去捕捉长期依赖的能力。
**在这个基础上LSTM应运而生,它的论文发表在1997年。**长短期记忆(LSTM)模型可用来解决稳定性和梯度消失的问题。
二、LSTM
在这里先说明一下,LSTM也是RNN的一种,输入基本没什么差别,它是一种特殊的RNNs,可以很好地解决长时依赖问题。
2.1 基本知识
在许多讲LSTM的文章中,都会出现下面这个图。 说实话,这个图确实很清晰明了(对于懂的人来说),一些很“显然”的问题就被忽略了,但是对于刚入门的人来说,一些基础的问题却要搞很久才能弄明白,我在原作者讲的很清楚的情况下再补充新手需要的内容。

在这里先说一下这些符号的含义,每个黄色方框表示一个神经网络层,由权值,偏置以及激活函数组成;每个粉色圆圈表示元素级别操作;箭头表示向量流向;相交的箭头表示向量的拼接;分叉的箭头表示向量的复制。

**Neuial Network layer:**一层神经网络,也就是w^T x + b的操作。区别在于使用的激活函数不同,σ表示的是sigmoid函数,他是将数据压缩到[0,1]范围内,如下图所示;tanh表示的是双曲正切激活函数,他把数据归一化到[-1,1]之间,具体函数网上可查,不一一贴图;

**Pointwise Operation:**这个是两个矩阵按位操作,如果是X号表示,这两个维数相同的矩阵,每个位置相同的元素相乘放到新矩阵的该位置上,如下图所示,加法也是同样。

**Vector Transfer:**矩阵传递
**Concatenate:**矩阵连接,两个矩阵不做任何计算,只是连接在一起,比如原来A10维,B5维,连接之后15维,就像贪食蛇一样。
**Copy:**一个矩阵变成两个一模一样的;
了解了这些基本操作,大概知道基础的运行原理,我们接下来一个个解析他的四个门结构,首先看大体结构。
2.2 LSTM结构
相比于原始的RNN的隐层(hidden state), LSTM增加了一个细胞状态Ct(cell state),下图是lstm中间一个时刻t的输入输出。

我们首先看一下LSTM在t时刻的输入与输出,首先,输入有三个: 细胞状态C_{t-1}(黄色圆圈),隐层状态h_{t-1}(紫色圆圈), t时刻输入向量X_t(蓝色圆圈),而输出有两个:细胞状态 C_t, 隐层状态 h_t。其中
1、细胞状态 C_{t-1}的信息,一直在上面那条线上传递, t时刻的隐层状态 ht与输入xt会对Ct进行适当修改,然后传到下一时刻去。
3、C_{t-1}会参与 t时刻输出 h_t的计算。
3、隐层状态 h_{t-1}的信息,通过LSTM的“门”结构,对细胞状态进行修改,并且参与输出的计算。
总的来说呢,细胞状态的信息一直在上面那条线上传递,隐层状态一直在下面那条线上传递,不过它们会有一些交互,在LSTM中,通常被叫做“门”结构。由此可以看到h_t不光光是由上一个状态,和本次的输入所决定,还有一个细胞状态C_{t-1},这是其与RNN最大的不用
LSTM也是RNN的一种,输入基本没什么差别。通常我们需要一个时序的结构喂给LSTM,数据会被分成 t个部分,也就是上面图里面的 X_t,X_t可以看作是一个向量 ,在实际训练的时候,我们会用batch来训练,所以通常它的shape是**(batch_size, input_dim)**。当然我们来看这个结构的时候可以认为batch_size是1,理解和计算之类的也比较简单。
另外C_0与 h_0的值,也就是两个隐层的初始值,一般是用全0初始化。两个隐层的同样是向量的形式,在定义LSTM的时候,会定义隐层大小(hidden size),即Shape(C_t) = Shape(h_t) = HiddenSize。输出的维度与对应输入是一致的。
2.3 LSTM的传送带
LSTM的核心部分是在图4中最上边类似于传送带的部分,这一部分一般叫做单元状态(cell state)它自始至终存在于LSTM的整个链式系统中。

其中:

其中 f_t叫做遗忘门,表示C_t-1的哪些特征被用于计算C_t。 f_t是一个向量,向量的每个元素均位于 [0,1]范围内。通常我们使用sigmoid作为激活函数,sigmoid的输出是一个介于[0,1]区间内的值,但是当你观察一个训练好的LSTM时,你会发现门的值绝大多数都非常接近0或者1,其余的值少之又少。其中 
是LSTM最重要的门机制,表示f_t和C_t-1之间的单位乘的关系。
2.4 LSTM的门结构( 一共有3个)
存储单元中管理向单元移除或添加的结构叫门限,有三种:遗忘门、输入门、输出门,门限由Sigmoid激活函数和逐点乘法运算组成。前一个时间步长的隐藏状态被送到遗忘门、输入门和输出门。在前向计算过程中,输入门学习何时激活让当前输入传入存储单元,而输出门学习何时激活让当前隐藏层状态传出存储单元。
2.4.1 遗忘门 Forget Gate

首先说一下[ht−1,xt]这个东西就代表把两个向量连接起来(操作与numpy.concatenate相同)。然后f_t就是一个网络的输出,看起来还是很简单的,执行的是上图中的公式。 具体的操作如下图所示:

这个图没有体现出来+b这个操作,下同
然而它为什么叫遗忘门呢,下面是我自己的看法,前面也说了,σ的输出在0到1之间,这个输出 f_t逐位与C_{t-1}的元素相乘,我们可以发现,当f_t的某一位的值为0的时候,这C_{t-1}对应那一位的信息就被干掉了,而值为(0, 1),对应位的信息就保留了一部分,只有值为1的时候,对应的信息才会完整的保留。因此,这个操作被称之为遗忘门,也算是“实至名归”,这样放到传送带上的内容是经过遗忘的,传送带我们后边会用到。
2.4.2 更新门 Input Gate
这个门有两个部分,一个是~C_t(因为我没有会员,当时写MD笔记不能插图,所以没有用Markdown来写,符合只能放在前面了,大家凑合着看吧),这个可以看作是新的输入带来的信息,tanh这个激活函数将内容归一化到-1到1。另一个是 i_t,这个东西看起来和遗忘门的结构是一样的,这里可以看作是新的信息保留哪些部分。

下面的操作就是对C_t进行更新,这个公式表示什么呢?看左边,就是前面遗忘门给出的f_t,这个值乘C_{t-1},表示过去的信息有选择的遗忘(保留)。右边也是同理,新的信息~{C_t}乘i_t表示新的信息有选择的遗忘(保留),最后再把这两部分信息加起来,就是新的状态C_t了。

具体的操作示意图如下:

2.4.3 输出门层 Output Gate
最后就是lstm的输出了,此时细胞状态C_t已经被更新了,这里的o_t还是用了一个sigmoid函数,表示输出哪些内容,而C_t通过tanh缩放后与o_t相乘,这就是这一个timestep的输出了。

看完公式之后,我们再来看图解,o_t比较简单,同forget门一样

参数
上面说了lstm的原理与公式,这里想再讲一下参数是怎么计算的。简单来说,就是上面公式的W和b包含的参数数量(上面一共有四个)。 W的话,就是输入维度乘输出维度, b的参数量就是加上输出维度。 上面的公式中,W有四个:W_f,W_i,W_c,W_o,同样,b也是四个: b_f, b_i, b_c, b_o。 我们假设输入x_t这个向量的维度是512,lstm的隐层数是 256,根据这个来实际计算一下参数量。 首先是输入 [h_{t-1}, x_t],这个前面说过,是两个向量连接起来,因此维度相加: 256 + 512 = 768。 因为隐层是 256,所以输出就是256维。 W的参数量就是 768×256=196608,b的参数是256。 所以最终的参数量就是:(768×256+256)×4=787456
另外,pytorch中的lstm实现稍有不同,其公式如下:

上面的 g_t其实就是~C_t,其他符号基本是一致的。可以看到,pytorch中,x_t与h_{t-1}并没有拼接在一起,而是各自做了对应的运算,这其实就是使用了分块矩阵的技巧进行计算,结果理论上是一样的,不过这里有些不同的就是加了两个bias,因此计算偏置的参数需要乘2。
2.5 LSTM如何解决RNN的梯度小时问题
LSTM可以抽象成这样:

三个圆圈内为乘号的符号分别代表的就是forget gate,input gate,output gate,而我认为LSTM最关键的就是forget gate这个部件。这三个gate是如何控制流入流出的呢?其实就是通过下面f_t,i_t,o_t三个函数来控制,因为 (代表sigmoid函数)的值是介于0到1之间的,刚好用趋近于0时表示流入不能通过gate,趋近于1时表示流入可以通过gate。
(代表sigmoid函数)的值是介于0到1之间的,刚好用趋近于0时表示流入不能通过gate,趋近于1时表示流入可以通过gate。


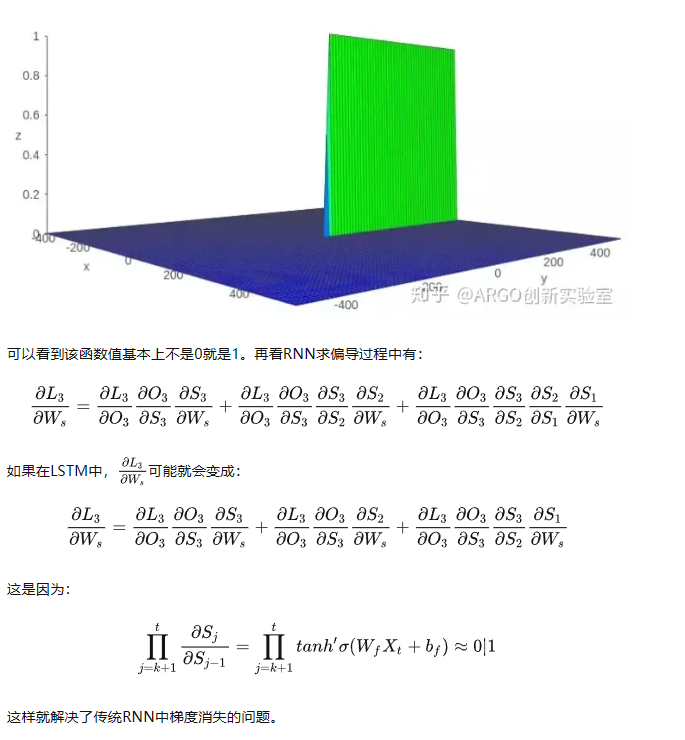
这样就解决了传统RNN中梯度消失的问题。
三、应用示例
3.1 RNN应用场景
a. 语言建模
语言建模(Language Modeling),通常指实现预测下一个单词的任务。例如下图,输入了"the students opened their"这个未完成的句子,预测下个单词最有可能的是哪一个?
b. 语言建模的应用
日常生活中天天会用到这个模型。例如在手机输入法中:

c. n-gram语言模型
问:怎样学习一个语言模型?
答:(深度学习前):使用n-gram语言模型
定义:n-gram是由n个连续单词组成的块。
unigrams: “the”, “students”, “opened”, ”their”
bigrams: “the students”, “students opened”, “opened their”
trigrams: “the students opened”, “students opened their”
**4-**grams: “the students opened their”
思想:收集关于不同n-grams频率的统计信息,用这些来预测下一个单词。
d. RNN语言模型源代码
参考: rnn-tutorial-rnnlm
其中有:RNNLM.ipynb 可以演示具体的运行过程。
3.1 LTSM应用场景
a. 文本情感分析
喜怒哀乐、批评、赞扬、中性,这就是情感。每一句话基本都可以和这情感词对应上。
基于之前的卷积神经网络的学习及分类/分割实例,如果要搭建一个实例模型,一般需要如下几个步骤:
数据素材准备、数据准备和处理,模型搭建,选择损失函数,选择优化方法,训练,评估。下面具体一步步展开。
目标:
有一批某评论数据,可以分为两类:正面评价与负面评价。需要训练一个情感分析模型,对评论文本进行分类。
详见:https://zhuanlan.zhihu.com/p/637258182














 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









