







数据库中一个核心的功能就是数据的访问, 数据的访问与计算单元越近越好,而CPU中的缓存的价格是昂贵的,并且也是稀少的,这就需要有CPU的 1 2 3 级别的缓存,CPU有一大部分的时间在处理这些缓存之间的信息交换,当然这些CACHE 也不大够处理我们的数据,所以就有了内存,同时为了永久的存储信息,将这些信息又存储到了磁盘。这就是我们整体的数据处理和存储最基本的原理,而数据库软件也一直以此来设计数据库的软件,并让他达到最大性价比。
POSTGRESQL 数据库的CACHE 要接受什么,数据,以及索引,这些信息已8KB的块存储在磁盘上,在需要处理的时候,需要将他们读入4KB的为存储单元的CACHE 中。除此以外还有查询的执行计划,把他作为一个定义存储到缓存中。
对于数据库最重要的就是如何将数以亿计的数据从磁盘加载到内存中,让计算变得可能,并且尽可能的快, postgresql 与其他的数据库不同在于,它对数据的依赖不在与磁盘,而在于LINUX 的cache,每次的数据提取都是从linux的file cache中获得的。而数据库中大部分的努力都是想让处理的数据尽量留在内存中,并且时间足够长,同时也想让不在使用的数据尽量的从内存中“轰出来”。这就是我们熟悉的LRU 算法对于数据库的意义。
PG 通过postmaster 为每一个数据库数据的访问分配一个基于他下面的子进程,并且这些进程在访问 share buffer后,基于LRU算法会让这些数据持续的在缓冲中,当这些数据在一定时间不再需要后,会通过checkpoint 子进程将这些数据重新写入到磁盘,空出缓冲承接新的数据。
实际上cache 在PG中的意义(这里的cache 指 os cache)
1 降低PG 内部缓冲与数据调用的代码,而是调用操作系统代码调取数据,系统的构造变得简单,并且随着操作系统的升级,对于PG本身的性能有提高的可能,属于一箭三雕。(当然如果操作系统不怎么样,那就.....)
2 通过os cache 加速数据的读取,os cache 够大 share buffer 的意义会削弱
反思: 随着硬件的变动,SSD 的磁盘系统性能越来越高,价格越来越便宜,硬件的变化,会对PG 的性能提升更有意义,在某些SSD 磁盘系统做测试,通过提前加载数据对性能的提高有限。
我们做一个实验,看看数据在内存中和不再内存中查询的差别(以下实验在传统SATA磁盘系统)
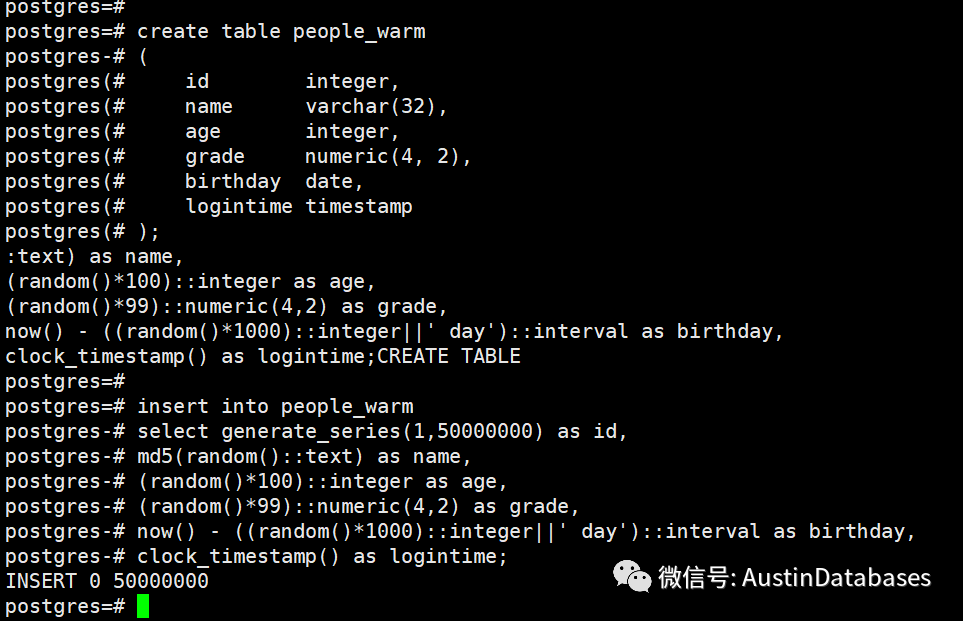
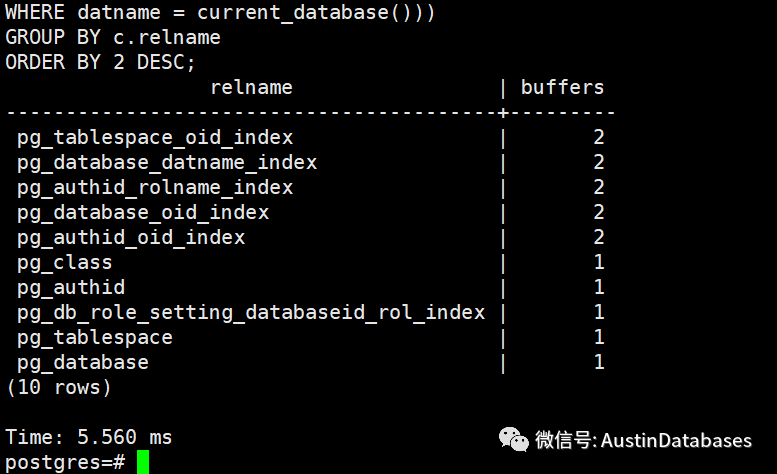
我们灌入5000万的数据到PG的数据库中。通过语句我们可以查出表在内存中的数据块的数量。
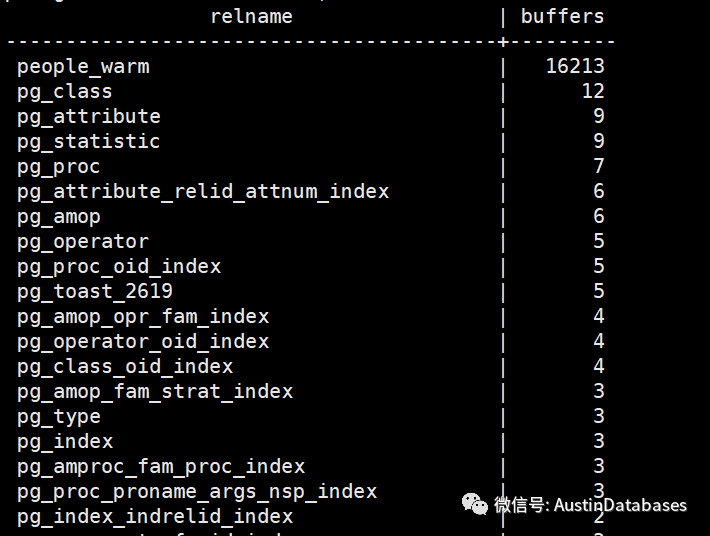
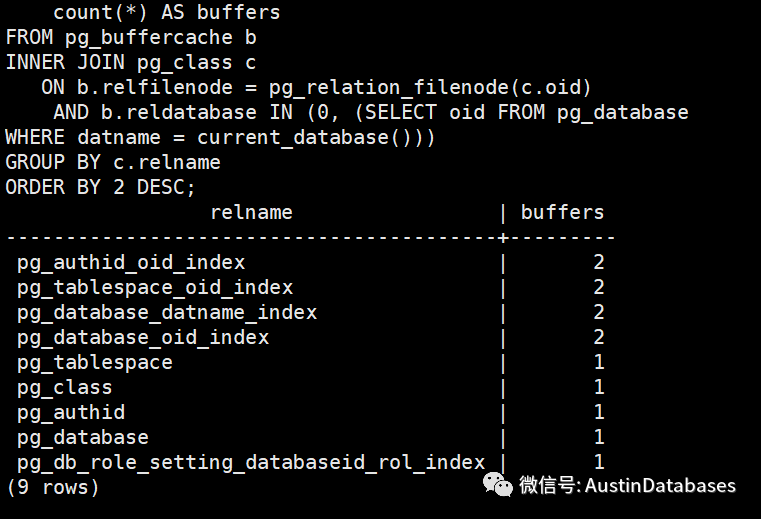
我们通过命令将数据库中people_warm 的缓存在 share_buffer中清空
我们通过简单的查询5000万表的数据,之间在26秒
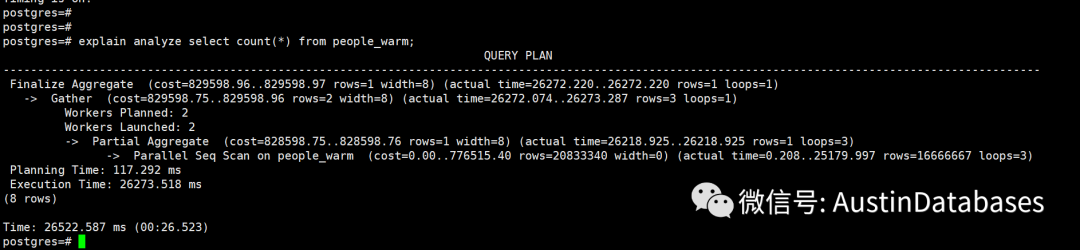
此时一部分数据已经进入到了缓存。
我们再次将数据清空。通过pg_prewarm 将数据加载进缓存中。
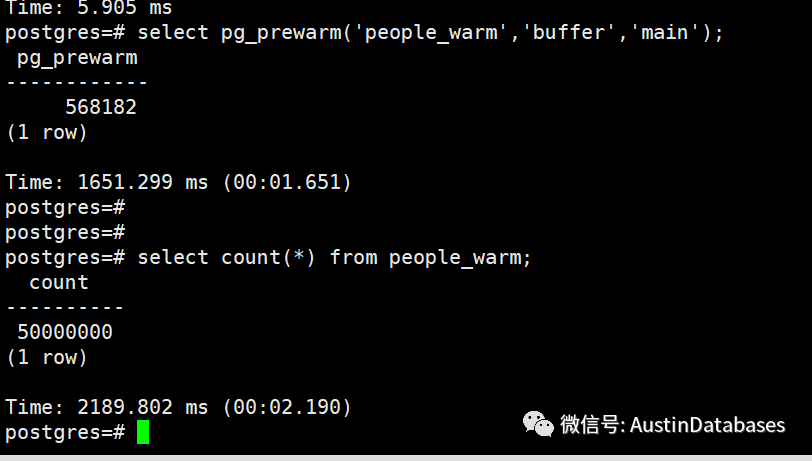
可以看到这次查询的时间仅仅需要2秒钟

执行计划也没有什么不同。此时这就能证明,数据在buffer中 和不再buffer中的巨大区别.
这里 pg_prewarm 有三种模式
1 Prefetch : 将数据迁移至LINUX 系统的 OS CACHE,而不是PG的buffer,数据加载的方式是异步的
2 Read: 读取所有的数据加载进行LINUX CACHE
3 Buffer:读取所有的数据块到PG的 share buffer中。
下图介绍了几个2个工具与参数的不同在数据引入内存的深度问题
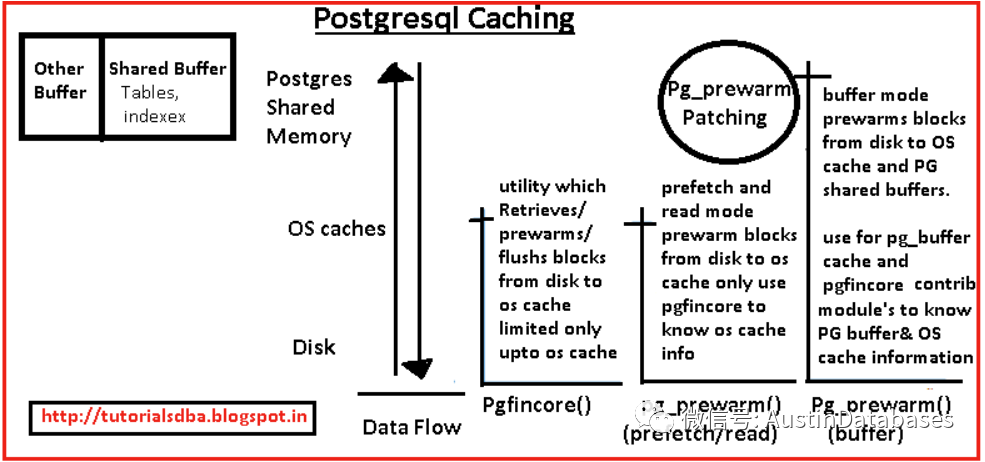
所有通过工具的使用也能了解一点 postgresql 本身的数据读取是必须通过LINUX的 缓存,也可以叫os cache.
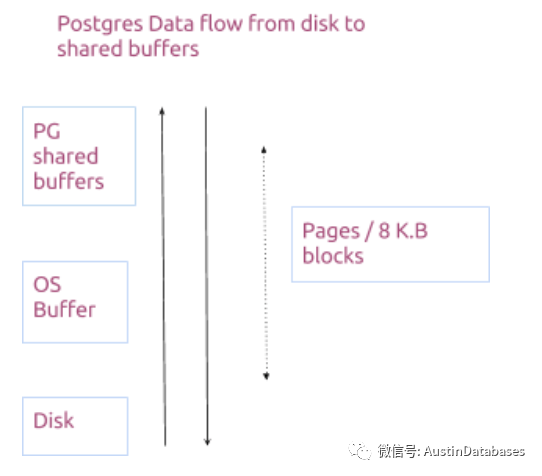

另一个问题就是PG的 share_buffer 与系统剩余内存的容量之间的关系,之前官方给出的调整参数是 1/4 share buffer 3/4 LINUX OS
那我们来通过一个测试来看看是不是如此,
这里有一个4核心,8G内存,SSD 磁盘系统的系统,并且这里通过pgbench来产生一个5000万的表。然后我们通过将share buffer 变动的情况,看看数据库的性能与share buffer 变动的关系。
pgbench -i --unlogged-tables -s 500 -U postgres -p 5432 -d pgbench
之前写的一篇与这个有关的文字
PostgreSQL 自己的 DB buffer & 与别的人的OS cache 之 回答问题
https://cloud.tencent.com/developer/article/1536270
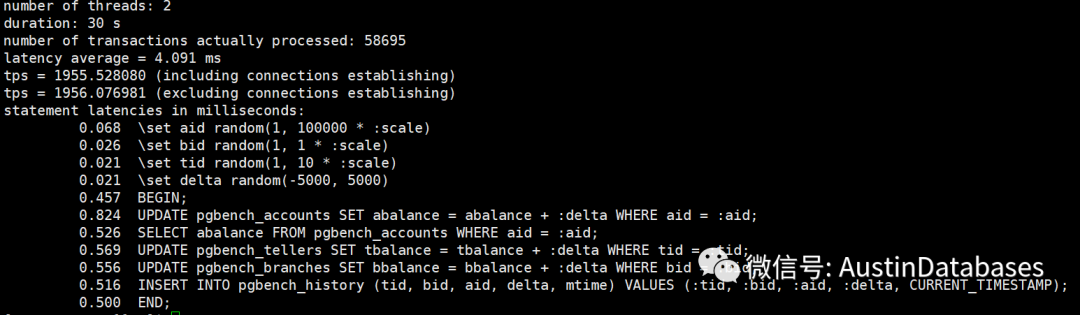
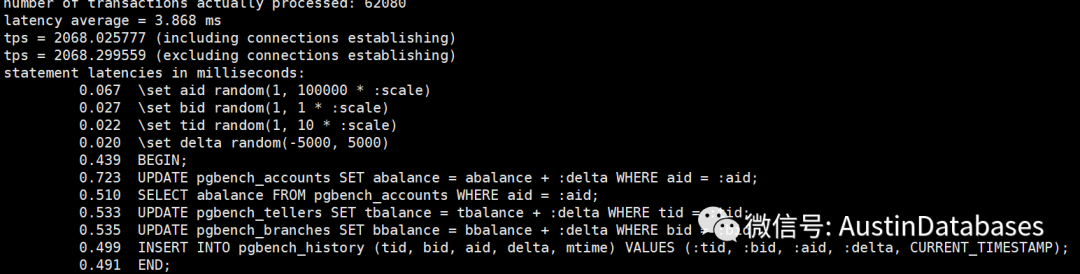
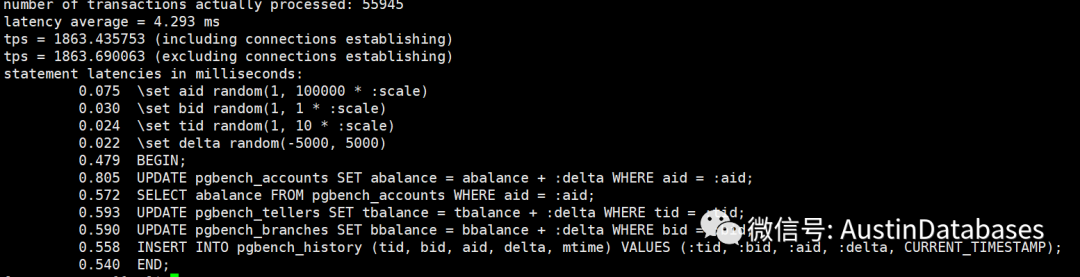
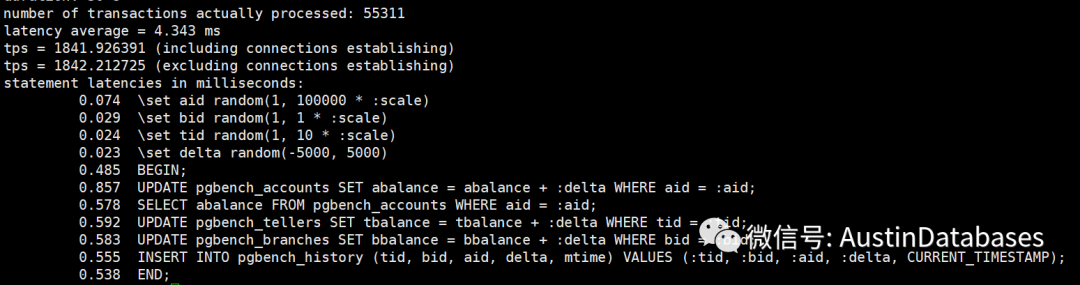
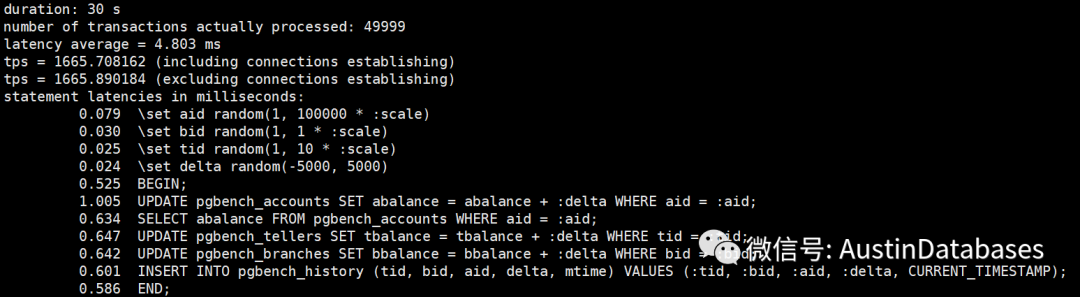
经过一个简单的测试,我们将shared buffer 设置成不同的数值,然后观察每条SQL 的平均延迟,以及30秒内运行的事务总数。当然一下的测试并不严谨,严谨的测试需要在时间,客户端的数量,以及测试数据等等都进行更多的数据测试,并且每个测试至少要测试10次,并取平均数。
这里并没有这么多时间,所以以下测试结果,只能参考,根据结果
1 share buffer 可以设置超过总物理内存的大小,系统不会报错
2 这里 3G ,占总内存的 37.5% 的结果是最好的,而不是 2G 根据官方的建议,我们这里应该设置成2G
3 虽然2G 不是最好的成绩,但是确实这9次测试里面较好的成绩
4 最差的成绩就是将所有的内存都设置成 share buffer
5 将share buffer 设置成9G 并不是这些成绩里面最差的成绩比 5G 4G 的成绩要好。
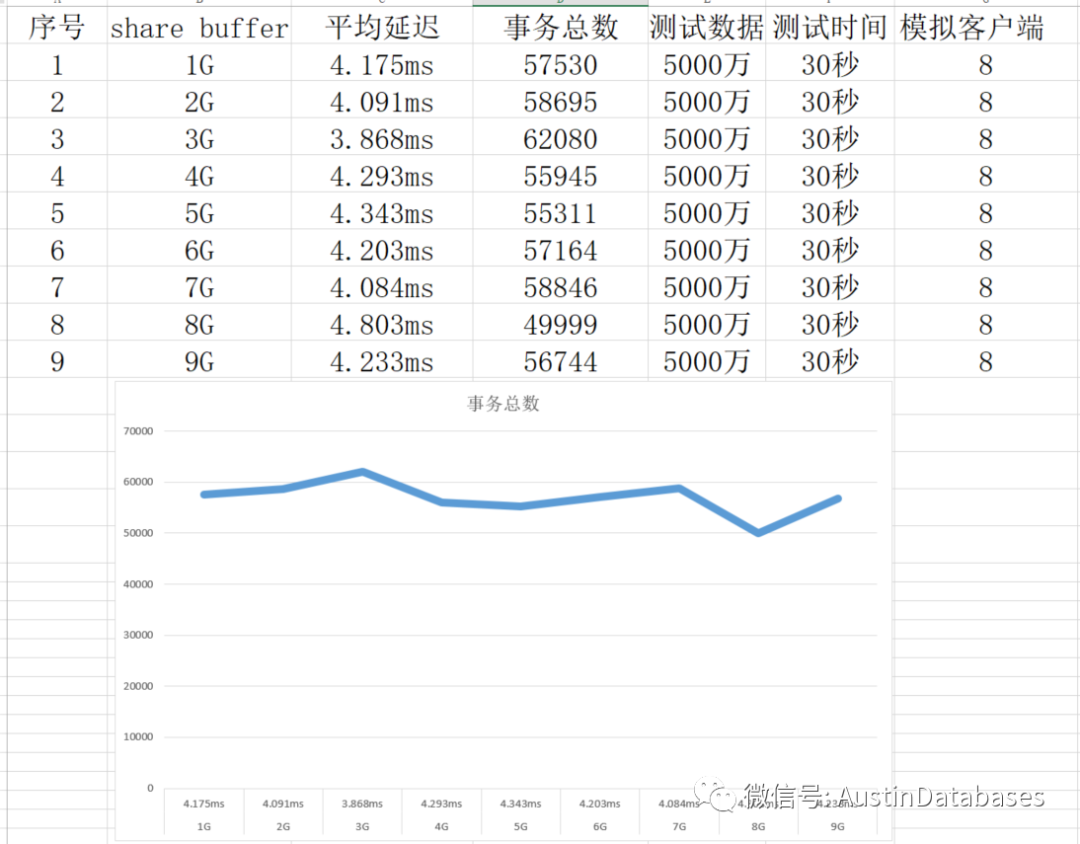
当然以上的测试并不能说明我们最好将内存设置为总体内存的37.5% ,但我们需要思考,并且有时候需要问自己一个问什么
1 为什么官方的建议是0.25
2 原因是什么















 3600
3600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









