







开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共650人左右 1 + 2)。
最近群里某个同学的提问,引起的本篇文章,关于数据库连接的部分,没有废话,我们先针对MYSQL 来说说数据库连接的部分。
首先MYSQL 的客户连接方式是通过线程的方式来进行客户和数据库之间的连接,在连接被使用的过程中,会出现活跃连接和idel连接,我们称之为空闲连接。
这里我们假设客户的连接是通过 libmysqlclient 连接到我们的MYSQL中的通过我们最常用的TCP/IP的协议方式通过3306端口,而在接受到连接手,MYSQL通过我们的队列形势,我们可以称之为接收队列来将我们客户发来的请求进行排队。
这里的一个关键是线程的缓存,缓存中会存在已经创建好的线程,如果发现当前的线程并不足以满足客户的需求,则会开启新的线程给新的来访者进行数据库的访问。那么控制来访者与线程缓存之间存在一个复用的关系,第一个问题在mysql 中thread cache 可以缓存多少线程满足用户的访问。
公式为:8 + (max_connections/100) = thread_cache_size
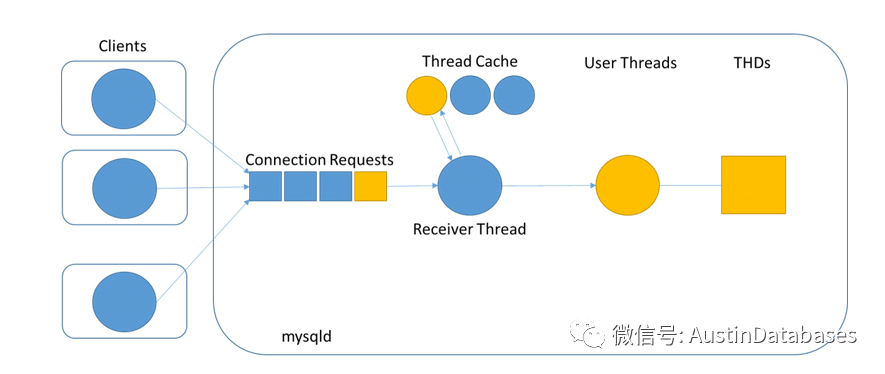
举例你的系统最大知识2000个连接(不是并发连接是最大连接),那么你的thread_cache_size = 8 + (2000/100) = 208
实际上也就是在变相的告诉使用者,我最大可以缓存的连接数复用的是208。实际上如果你的一半的主机配置(8C 32 是无法达到这个最大活跃连接数的,一半以我们测试的经验这个配置的机器 60的并发连接数据已经是一个较高的值了,在超过这个值你的MYSQL很可能出现无法响应的问题)
在我们的使用中瞬时连接在30以内属于性能良好的范畴(因人而异,不是一个标准值是一个经验值,具体你的系统是多少,这个你自己的去摸索和评估)
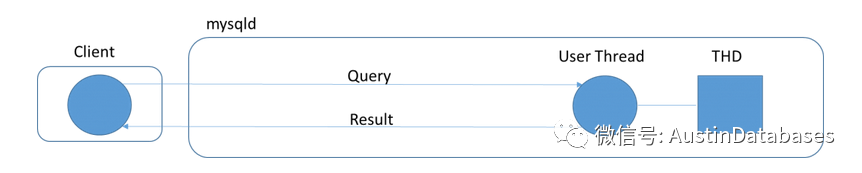
而在MYSQL的每个线程连接中有一个THD 的部分,这个部分是你在创建这个线程时共同创建出来的,这个部分就是收集你这个连接的状态信息的部分,代码在 sql_class.h 中,这个部分的内存会随着连接的时间而增长,有的时候每个连接的占用的内存可能会达到10MB。这里存储着你的线程在处理任务中的事务执行中的上下文,事务的状态会话中的一些变量,临时表,等等
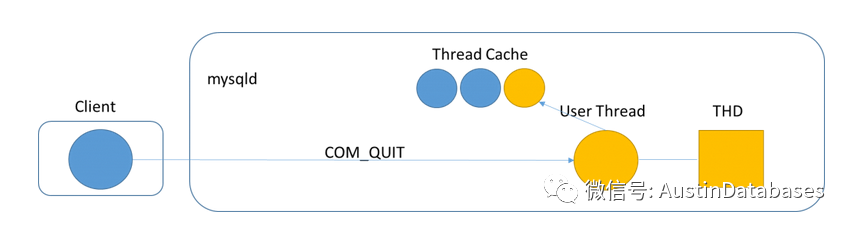
在连接使用完毕后,会进行释放这还是由客户端发起的com_quit 信号,通过他来将你的客户与MYSQL的线程进行分离,分离后THD 使用的内存将被释放,并且这个线程将重新放回到 thread cache 中。
实际上一个线程在处理任务中的三个关键因素
1 互斥锁
2 数据库锁
3 IO
一个线程在处理一个事务的过程中,会考虑在处理事务的情况下是否有其他的线程也在处理与我同样的资源,互斥锁的主要目的就是,独占性,通过独占来满足一个线程处理数据时的排他性。数据锁(如行锁)通常会保护一个线程正在更新的数据不被另一个线程读或写。元数据锁通常会保护数据库模式不受并发的、不兼容的更新的影响,而IO 是在数据处理中,一个任务等待处理的数据通过IO操作读入到内存的一个等待的事件。最终一个线程的整体操作会受到这三个方面的限制和控制。
而系统性能消耗最大的部分就是一个线程处理不完他的任务,而另一个需求已经来了,那么系统会不断开心的线程满足客户的需求,直到你的系统的资源出现瓶颈,可能是IO 也可能是 CPU 或内存。
那么怎么控制这个问题,有同学试图从数据库入手来解决这个问题,比如降低max_connections ,或者通过降低 thread_cache_size的方式,这些都是不可取的想法,首先数据库是一个包容性的集中处理数据的机构,任何想通过各种设置,降低客户访问便利性的想法都是对于数据库本身运行的机制的一种误解。
实际中正确的控制的方式应该是从软件的形成方来进行控制,如他们的软件的连接数的设置,连接池的设计与配置,等等,DBA 工作的方向是和开发联合进行沟通和正确的数据库连接的使用,而不是自行进行活跃连接数据的限制这样的想法和做法。
而群里面提到的 innodb_commit_concurrency, 并不是一个可以控制并发连接数的设置,他的主要的初衷是控制并发线程在同一个时刻可以进行commit的数量,这实际上与活跃连接控制无关。具体他是做什么的,可以参考下面的文字。
https://www.percona.com/blog/innodb-thread-concurrency/
反过来我们在说说 POSTGRESQL ,PG 工作的客户连接是进程的模式,与MYSQL 是不一样的,客户通过libpq 的方式与PG 建立连接,客户首先会与主进程进行访问的申请后,建立backend process 的进程与数据库进行数据处理,这里每个进程在PG14并不是自己进行信息的统计,而是通过另一个进程来进行相关的每个进程的工作信息的收集,这个进程是statistics collector 。
与mysql 不同的是POSTGRESQL 有一个统一管理客户进程内存的参数,work_mem 他来提供客户端访问数据库的使用的内存。相比较线程的模式,进程的模式以及POSTGRESQL 对于客户连接的处理上,POSTGRESQL 的使用是更愿意复用的,也就是将一个连接给多个应用在不同的时间部分进行利用,所以PG 有一个数据库连接池pgbouncer 的产生,来去做这个复用的部分。
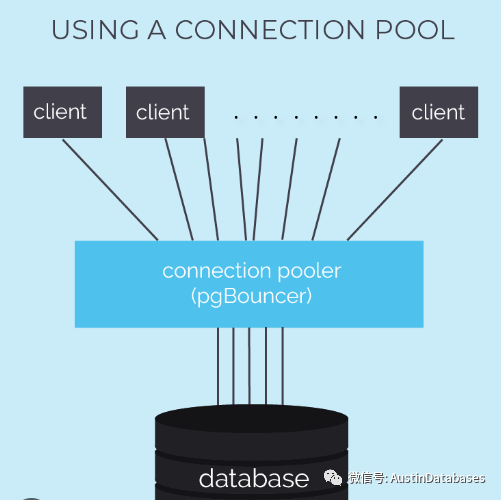
如果你不想使用pgbouncer 的情况下,建议不要长时间一个进程被应用程序霸占时间太长,你的应用线程池需要进行合理的设置,在多长时间释放掉连接,但是POSTGRESQL 有一个特性是并行,并行查询中是可以利用多个CPU为一个SQL进行服务的,在这样的情况下,需要评估你的CPU的数量,与你参数 max_worker_processes 和 max_parallel_workers的配置。
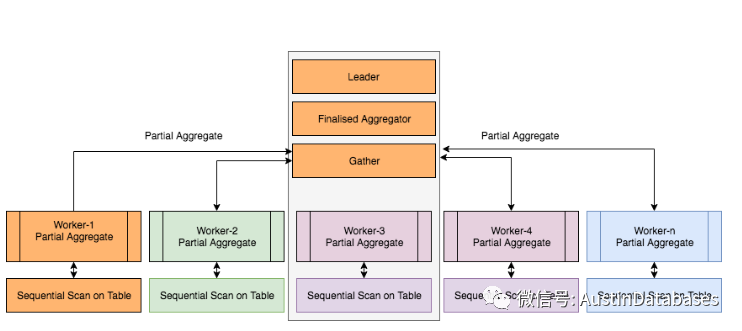
控制PG的连接的几个部分参数有一下,建议不熟悉PG的同学先把以下的参数与以及功能弄清楚
max_connections
work_mem
max_worker_processes = 8
max_parallel_workers_per_gather = 4
max_parallel_maintenance_workers = 2
max_parallel_workers = 8
下图为POSTGRESQL 客户连接进程与PG 内部进程
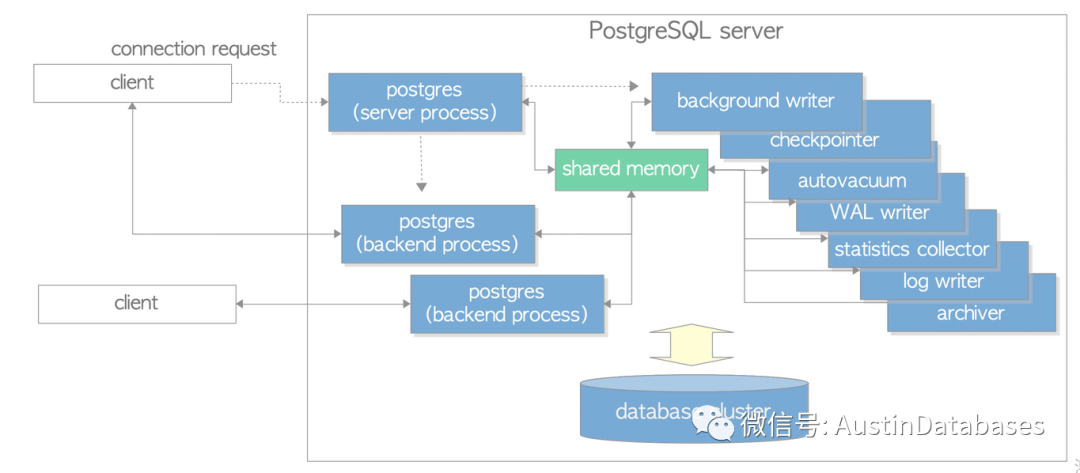
另外一个问题,为什么MYSQL是线程,POSTGRESQL 是进程,
进程比线程更沉重,每个进程都有自己的虚拟内存,它维护称为PCB(进程控制块)的元数据,其中包括用于将虚拟地址映射到物理地址的页表以及有关进程的任何其他元数据。PCB必须存储在内存中,并进入CPU缓存寄存器,将虚拟内存地址转换为物理地址。另一方面,线程与它们的父进程共享虚拟内存空间,并且它们的TCB(线程控制块)通过指向父进程PCB的指针要小得多。所以线程的缓存命中率要比进程高得多。但是在早期的系统设计中有一个概念,线程相对于进程是不稳定的,基于这个理念PG 在设计中采用了进程,而不是线程来设计。
如果对此有疑问,可以自行查找MYSQL 5.0 的稳定性的一些历史文章和问题。
总结:控制数据库的活跃线程,是一个伪命题,无论MYSQL 或 PG 都不应该支持这样的想法,应用设计模块该去解决的问题,应该去对应的部分去解决,而不是将所有的问题都塞给数据库。
















 1079
1079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









