






开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共2310人左右 1 + 2 + 3 + 4 +5+6) 新人奖直接分配到5群,5群已经停止进行自由申请 已建立6群(接近100)。

有了PostgreSQL的出现,MySQL的数据库在SQL的处理上的问题一直被人当做有意思的事情来去谈论,实际上每种数据库有自己不同的个性,我们掌握就好,无需特别的进行一些情感上的好恶。
MySQL 最近一个同学给我提了一个问题,关于为什么一个简单的语句,并且语句中提取的数据是唯一的一条,而却在下面循环了三次,因为我没有他的数据,也仅仅是看了执行计划和语句,又因为是截图,所以只是简单的看了看。
不过今天转念一想,到底MySQL 8 的数据处理部分,基于我之前在MySQL 5.6 5.7等积累的一些关于 子查询差的口碑,是否被改善了的事情又重新让我想起了,8.0 是不是更好,随即使用了8.031版本的MySQL 数据库。
这里我们使用了一个MYSQL 的emaple数据库,并编造了一段可以重新写成两种方式的SQL ,我们直接来看一下.
select o.*
from orders as o
left join orderdetails as d on o.ordernumber = d.ordernumber and o.ordernumber = (select ordernumber
from orders where requiredDate > '2003-01-12' and requiredDate < '2003-01-14')
where o.requiredDate > '2003-01-12' and o.requiredDate < '2003-01-14';
| -> Nested loop left join (cost=1.36 rows=4) (actual time=0.070..0.075 rows=4 loops=1)
-> Index range scan on o using idx_requiredDate over ('2003-01-12' < requiredDate < '2003-01-14'), with index condition: ((o.requiredDate > DATE'2003-01-12') and (o.requiredDate < DATE'2003-01-14')) (cost=0.71 rows=1) (actual time=0.060..0.062 rows=1 loops=1)
-> Filter: ((o.orderNumber = (select #2)) and (d.orderNumber = (select #2))) (cost=0.65 rows=4) (actual time=0.009..0.011 rows=4 loops=1)
-> Covering index lookup on d using PRIMARY (orderNumber=(select #2)) (cost=0.65 rows=4) (actual time=0.007..0.010 rows=4 loops=1)
-> Select #2 (subquery in condition; run only once)
-> Filter: ((orders.requiredDate > DATE'2003-01-12') and (orders.requiredDate < DATE'2003-01-14')) (cost=0.46 rows=1) (actual time=0.028..0.032 rows=1 loops=1)
-> Covering index range scan on orders using idx_requiredDate over ('2003-01-12' < requiredDate < '2003-01-14') (cost=0.46 rows=1) (actual time=0.027..0.030 rows=1 loops=1)
-> Select #2 (subquery in condition; run only once)
-> Filter: ((orders.requiredDate > DATE'2003-01-12') and (orders.requiredDate < DATE'2003-01-14')) (cost=0.46 rows=1) (actual time=0.028..0.032 rows=1 loops=1)
-> Covering index range scan on orders using idx_requiredDate over ('2003-01-12' < requiredDate < '2003-01-14') (cost=0.46 rows=1) (actual time=0.027..0.030 rows=1 loops=1)
|第二个写法
select o.*
from orders as o
left join orderdetails as d on o.ordernumber = d.ordernumber
left join orders as o2 on o2.ordernumber = d.ordernumber and o2.requiredDate > '2003-01-12' and o2.requiredDate < '2003-01-14'
where o.requiredDate > '2003-01-12' and o.requiredDate < '2003-01-14';
| -> Nested loop left join (cost=5.11 rows=9) (actual time=0.039..0.047 rows=4 loops=1)
-> Nested loop left join (cost=1.89 rows=9) (actual time=0.034..0.039 rows=4 loops=1)
-> Index range scan on o using idx_requiredDate over ('2003-01-12' < requiredDate < '2003-01-14'), with index condition: ((o.requiredDate > DATE'2003-01-12') and (o.requiredDate < DATE'2003-01-14')) (cost=0.71 rows=1) (actual time=0.023..0.025 rows=1 loops=1)
-> Covering index lookup on d using PRIMARY (orderNumber=o.orderNumber) (cost=1.18 rows=9) (actual time=0.009..0.012 rows=4 loops=1)
-> Filter: ((o2.requiredDate > '2003-01-12') and (o2.requiredDate < '2003-01-14')) (cost=0.26 rows=1) (actual time=0.001..0.002 rows=1 loops=4)
-> Single-row index lookup on o2 using PRIMARY (orderNumber=d.orderNumber) (cost=0.26 rows=1) (actual time=0.001..0.001 rows=1 loops=4)从下面的截图语句,可以看到两种写法的语句均得到一样的逻辑数据结果,但是相关的语句的执行计划完全不同。
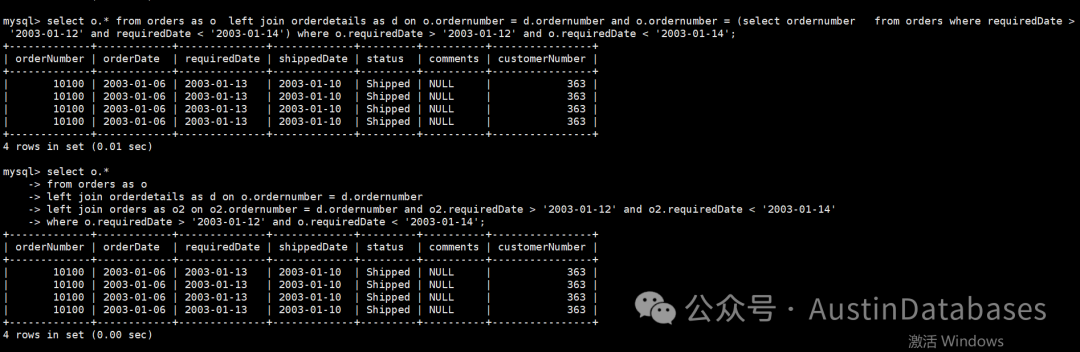
1 子查询类型的方式撰写的语句
select o.*
from orders as o
left join orderdetails as d on o.ordernumber = d.ordernumber and o.ordernumber = (select ordernumber
from orders where requiredDate > '2003-01-12' and requiredDate < '2003-01-14')
where o.requiredDate > '2003-01-12' and o.requiredDate < '2003-01-14';
从上面的语句中可以看到,将其中一个left join中的条件对接到子查询中,这里可以看到子查询得出的数据一定是一条数据,否则语句就会报错。
但从执行计划,我们明显可以看出,对于日期的部分,在执行计划中,出现了三次。
其中的两次是一致的,
-> Select #2 (subquery in condition; run only once)
-> Filter: ((orders.requiredDate > DATE'2003-01-12') and (orders.requiredDate < DATE'2003-01-14')) (cost=0.46 rows=1) (actual time=0.028..0.032 rows=1 loops=1)
-> Covering index range scan on orders using idx_requiredDate over ('2003-01-12' < requiredDate < '2003-01-14') (cost=0.46 rows=1) (actual time=0.027..0.030 rows=1 loops=1)
-> Select #2 (subquery in condition; run only once)
-> Filter: ((orders.requiredDate > DATE'2003-01-12') and (orders.requiredDate < DATE'2003-01-14')) (cost=0.46 rows=1) (actual time=0.028..0.032 rows=1 loops=1)
-> Covering index range scan on orders using idx_requiredDate over ('2003-01-12' < requiredDate < '2003-01-14') (cost=0.46 rows=1) (actual time=0.027..0.030 rows=1 loops=1)
|
出现这样的情况主要是因为,在MySQL 在通过子查询查询数据的时候,会在子查询内部重新评估条件,并产生相关的执行计划,导致重复的查询计划生成的操作,同时由于查询的复杂度,尤其子查询的嵌入会增加优化器生成和选择执行计划的难度,在这样的情况下优化器会多次进行过滤,还有在MySQL在进行执行计划产生的时候会尝试不同的执行计划并在其中做出优化策略的权衡时为保证查询结果的正确性,产生多次过滤方式保证最终结果的正确性。
而反观我们不在使用子查询撰写的语句在执行计划中并未有重复的日志数据的过滤,并且从执行时间上看,也要比子查询的方式查询的速度要快。
select o.*
from orders as o
left join orderdetails as d on o.ordernumber = d.ordernumber
left join orders as o2 on o2.ordernumber = d.ordernumber and o2.requiredDate > '2003-01-12' and o2.requiredDate < '2003-01-14'
where o.requiredDate > '2003-01-12' and o.requiredDate < '2003-01-14';
| -> Nested loop left join (cost=5.11 rows=9) (actual time=0.039..0.047 rows=4 loops=1)
-> Nested loop left join (cost=1.89 rows=9) (actual time=0.034..0.039 rows=4 loops=1)
-> Index range scan on o using idx_requiredDate over ('2003-01-12' < requiredDate < '2003-01-14'), with index condition: ((o.requiredDate > DATE'2003-01-12') and (o.requiredDate < DATE'2003-01-14')) (cost=0.71 rows=1) (actual time=0.023..0.025 rows=1 loops=1)
-> Covering index lookup on d using PRIMARY (orderNumber=o.orderNumber) (cost=1.18 rows=9) (actual time=0.009..0.012 rows=4 loops=1)
-> Filter: ((o2.requiredDate > '2003-01-12') and (o2.requiredDate < '2003-01-14')) (cost=0.26 rows=1) (actual time=0.001..0.002 rows=1 loops=4)
-> Single-row index lookup on o2 using PRIMARY (orderNumber=d.orderNumber) (cost=0.26 rows=1) (actual time=0.001..0.001 rows=1 loops=4)
通过此示例我们可以得出如下的一些结论
1 在MySQL中如果可以将子查询改为连接查询的,尽量改为连接查询 ,通常连接查询的被正确翻译并走更优的执行计划的可能性更高。
2 左连接通常比子查询更适合大数据量的情况,子查询会产生中间结果集,导致内存压力增大,和查询性能的下降,左连接可以更好的解决由于子查询在产生的子结果集较大时产生的问题,减少中间结果集的产生,提高执行效率。
这同时也体现了,MySQL SQL 处理引擎,在SQL的解析上应还有更多的进步的空间,在SQL转换为内部数据结果时,对于子查询上的语义的解读上还有改善的空间。
同时本公众号,正在举办留言送书活动,详情请到下面的页面查看具体活动和送书的具体细节https://mp.weixin.qq.com/s/FOVBTcShVgwQJgZ2FrHBSQ
置顶文章:
临时工访谈:我很普通,但我也有生存的权利,大龄程序员 求职贴
临时工说:DBA 是不是阻碍国产数据库发展的毒瘤 ,是不是?从国产DB老专家的一条留言开始
震惊了:TechTalk技术交流社区主理人荐书 | 我与 Zabbix 的故事
临时工说:DBA 新职业,善于发现工作的人有工作---云数据库成本精算师
往期热门文章:
PolarDB Serverless POC测试中有没有坑与发现的疑问
临时工访谈:庙小妖风大-PolarDB 组团镇妖 之 他们是第一
临时工访谈:PolarDB Serverless 发现“大”问题了 之 灭妖记 续集
感谢 老虎刘 刘老师 对 5月20日 SQL 问题纠正贴 ---PostgreSQL 同一种SQL为什么这样写会提升45%性能
PostgreSQL 同一种SQL为什么这样写会提升45%性能 --程序员和DBA思维方式不同决定
临时工访谈:金牌 “女” 销售从ORACLE 转到另类国产数据库 到底 为什么?
PostgreSQL 熊灿灿一句话够学半个月 之 KILL -9
临时工访谈:无名氏意外到访-- 也祝你好运(管理者PUA DBA现场直播)
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
JunkFood读者说你文章不对,作者被鞭策后,DBA 开始研究JAVA程序锁
PostgreSQL PG_DUMP 工作失败了怎么回事及如何处理
临时工说:经济规律解读ORACLE 工资低 --读 Roger 数据库专栏
PostgreSQL 为什么也不建议 RR隔离级别,MySQL别笑
临时工访谈:OceanBase上海开大会,我们四个开小会 OB 国产数据库破局者
临时工说:OceanBase 到访,果然数据库的世界很卷,没边
PolarDB for PostgreSQL 有意思吗?有意思呀
PostgreSQL 玩PG我们是认真的,vacuum 稳定性平台我们有了
临时工说:裁员裁到 DBA 咋办 临时工教你 套路1 2 3
临时工说:OceanBase 到访,果然数据库的世界很卷,没边
MONGODB ---- Austindatabases 历年文章合集
MYSQL --Austindatabases 历年文章合集
POSTGRESQL --Austindatabaes 历年文章整理
POLARDB -- Ausitndatabases 历年的文章集合
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
SQL SERVER 如何实现UNDO REDO 和PostgreSQL 有近亲关系吗
MongoDB 2023纽约 MongoDB 大会 -- 我们怎么做的新一代引擎 SBE Mongodb 7.0双擎力量(译)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
MongoDB 会丢数据吗?在次补刀MongoDB 双机热备
临时工说:从人性的角度来分析为什么公司内MySQL 成为少数派,PolarDB 占领高处
PostgreSQL 字符集乌龙导致数据查询排序的问题,与 MySQL 稳定 "PG不稳定"
PostgreSQL Patroni 3.0 新功能规划 2023年 纽约PG 大会 (音译)
Austindatabases 公众号,主要围绕数据库技术(PostgreSQL, MySQL, Mongodb, Redis, SqlServer,PolarDB, Oceanbase 等)和职业发展,国外数据库大会音译,国外大型IT信息类网站文章翻译,等,希望能和您共同发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









