






❝开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, OceanBase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共2790人左右 1 + 2 + 3 + 4 +5 + 6 + 7 + 8 +9)(1 2 3 4 5 6 7群均已爆满,开8群260+ 9群)
最近越来越多的人知道上云还用ECS自建的MySQL是垃圾,是呀用经济学原理一分析,就知道有多垃圾了。有人问了,你说的那个是价值观,太宏观,你说点干货,怎么自建的MySQL就垃圾了,来来来,今天我给你看一个云原生数据库的功能,你敢说你的自建MySQL不是小垃圾。
故事开头是我们的一个同事在产生一个新的PolarDB for MySQL的时候,发现一些和之前配置不同的地方,并进行询问,我后面也跟了进去。
后面我就发现了一些问题,主要还是云原生数据库的不学习就落后的问题,顺着客服给我的信息,我突然发现一些POALRDB FOR MYSQL之前没有的功能。
在此之前我们使用PolarDB for MySQL的通用功能是通过X-Engine 引擎来进行的数据的归档和压缩的。
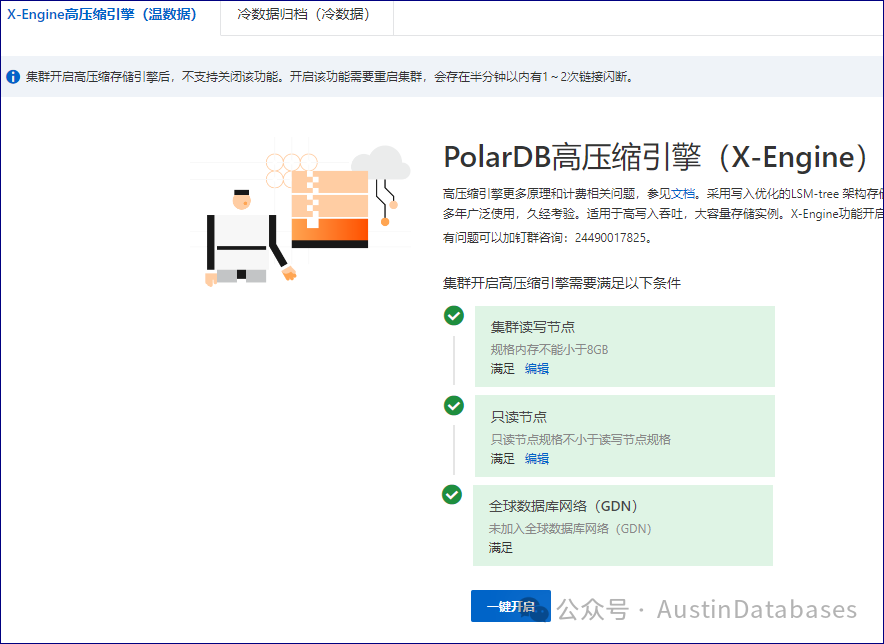
最近光忙活MongoDB的升级和PolarDB for PostgreSQL的事情了,一段时间没有去关注PolarDB for MySQL,这个数据库新版本提供了类似 PolarDB for PostgreSQL的冷数据归档的方案。
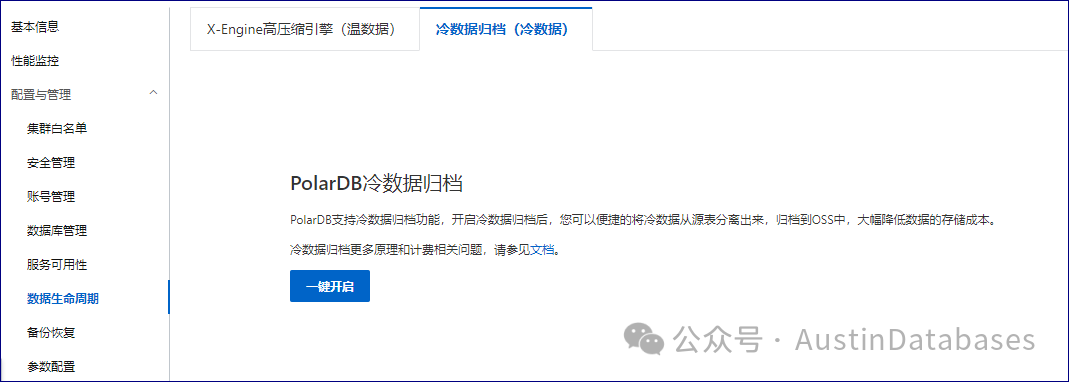
废话不说,咱们先试试这个PolarDB for MySQL的直接归档表的新功能。
MySQL [test]> SELECT
-> TABLE_NAME AS `Table`,
-> ROUND((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024, 2) AS `Size (MB)`,
-> TABLE_ROWS AS `Rows`
-> FROM
-> information_schema.TABLES
-> WHERE
-> TABLE_SCHEMA = 'test'
-> ORDER BY
-> (DATA_LENGTH + INDEX_LENGTH) DESC;
+------------+-----------+--------+
| Table | Size (MB) | Rows |
+------------+-----------+--------+
| text | 40.58 | 997819 |
| test_table | 0.02 | 0 |
+------------+-----------+--------+
2 rows inset (0.004 sec)
MySQL [test]>MySQL [test]> SELECT
-> TABLE_NAME AS `Table`,
-> ROUND((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024, 2) AS `Size (MB)`,
-> TABLE_ROWS AS `Rows`
-> FROM
-> information_schema.TABLES
-> WHERE
-> TABLE_SCHEMA = 'test'
-> ORDER BY
-> (DATA_LENGTH + INDEX_LENGTH) DESC;
+------------+-----------+--------+
| Table | Size (MB) | Rows |
+------------+-----------+--------+
| text | 40.58 | 997819 |
| test_table | 0.02 | 0 |
+------------+-----------+--------+
2 rows inset (0.004 sec)
MySQL [test]> alter table text engine = CSV storage OSS;
Query OK, 1000000 rows affected (3.124 sec)
Records: 1000000 Duplicates: 0 Warnings: 0
MySQL [test]> alter table text engine = innodb;
Query OK, 1000000 rows affected (6.440 sec)
Records: 1000000 Duplicates: 0 Warnings: 0
MySQL [test]> alter table text engine = CSV storage OSS;
Query OK, 1000000 rows affected (2.534 sec)
Records: 1000000 Duplicates: 0 Warnings: 0
MySQL [test]> select * from text limit 1;
+----+---------------+
| id | varchar_col |
+----+---------------+
| 1 | data_00000000 |
+----+---------------+
1 row inset (0.133 sec)
MySQL [test]> select * from text limit 1000;
+------+---------------+
| id | varchar_col |
+------+---------------+
| 1 | data_00000000 |
| 2 | data_00000001 |
| 3 | data_00000002 |
| 4 | data_00000003 |
| 5 | data_00000004 |
| 6 | data_00000005 |
| 7 | data_00000006 |
| 8 | data_00000007 |
| 9 | data_00000008 |
| 10 | data_00000009 |
| 11 | data_00000010 |
| 12 | data_00000011 |
| 13 | data_00000012 |
| 14 | data_00000013 |
| 15 | data_00000014 |
| 979 | data_00000978 |
| 980 | data_00000979 |
| 981 | data_00000980 |
| 982 | data_00000981 |
| 983 | data_00000982 |
| 984 | data_00000983 |
| 985 | data_00000984 |
| 986 | data_00000985 |
| 987 | data_00000986 |
| 988 | data_00000987 |
| 989 | data_00000988 |
| 990 | data_00000989 |
| 991 | data_00000990 |
| 992 | data_00000991 |
| 993 | data_00000992 |
| 994 | data_00000993 |
| 995 | data_00000994 |
| 996 | data_00000995 |
| 997 | data_00000996 |
| 998 | data_00000997 |
| 999 | data_00000998 |
| 1000 | data_00000999 |
+------+---------------+
1000 rows inset (0.107 sec)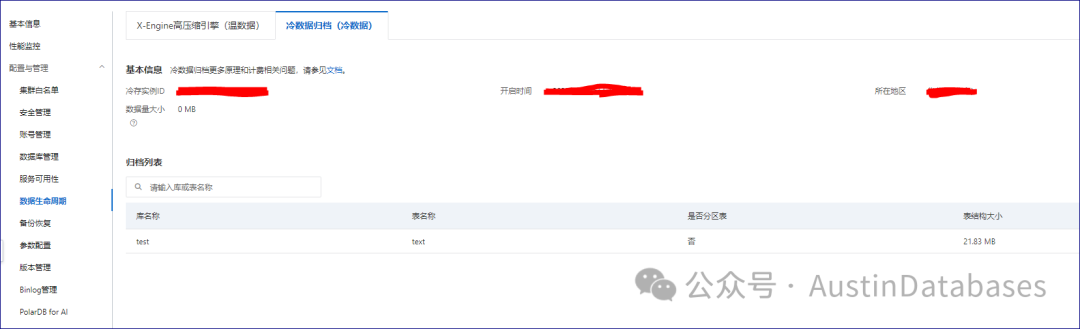


看来这功能是有点意思!! 这以后归档表那不是太方便了吗,还需要 mysqldump 吗? 还需要导入导出数据节省成本,在节省成本能有 OSS成本低,几分钱的成本,如果你嫌弃这个还高,那你把这些数据存到纸上都的几十块钱。
在查看文档的时候,我还发现,他不光可以把表存储成 csv方式进行归档,还可以存储成 ibd 文件
这里需要说一下,这两种方式的不同
1 将MySQL的表转为CSV的方式的意义在于只要归档了这个表就不可以变化了,数据就是死的,只能读
2 将MySQL的表转为idb文件的归档方式的好处是归档的表还可以进行DML的操作,但不能进行DDL的操作。
这个功能一出,我想都能想的到一些企业的需求马上就能被满足,尤其Saas 企业。一些企业的数据归档后,客户不知道那天冒出来,还要数据,你还没发拒绝,这功能可以支持数据归档后,在归档中将文件进行变更,这太牛了。
马上试一下,What F 我的天,这功能可以呀!!!
MySQL [test]> SELECT
-> TABLE_NAME AS `Table`,
-> ROUND((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024, 2) AS `Size (MB)`,
-> TABLE_ROWS AS `Rows`
-> FROM
-> information_schema.TABLES
-> WHERE
-> TABLE_SCHEMA = 'test'
-> ORDER BY
-> (DATA_LENGTH + INDEX_LENGTH) DESC;
+------------+-----------+--------+
| Table | Size (MB) | Rows |
+------------+-----------+--------+
| text | 40.58 | 997819 |
| test_table | 0.02 | 0 |
+------------+-----------+--------+
2 rows inset (0.004 sec)
MySQL [test]> alter table text storage_type oss;
Query OK, 0 rows affected (1.007 sec)
Records: 0 Duplicates: 0 Warnings: 0
MySQL [test]> select * from text limit 1;
+----+---------------+
| id | varchar_col |
+----+---------------+
| 1 | data_00000000 |
+----+---------------+
1 row inset (0.003 sec)
MySQL [test]> update text set varchar_col = '11111'where id = 1;
Query OK, 1 row affected (0.006 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL [test]> select * from text limit 1;
+----+-------------+
| id | varchar_col |
+----+-------------+
| 1 | 11111 |
+----+-------------+
1 row inset (0.094 sec)
MySQL [test]>写到这里,我对比了一下两种的归档方式的文件大小
1 ibd 大小是 60MB 2 csv 大小事 27MB左右
那么这里我总结,如果是真正归档,那么我们选择CSV的格式,这里数据不能再变动,但如果是我刚才说的那个需求,不定什么时间客户还要数据,还要改这个数据,那么把数据文件变成 ibd就是最优选。
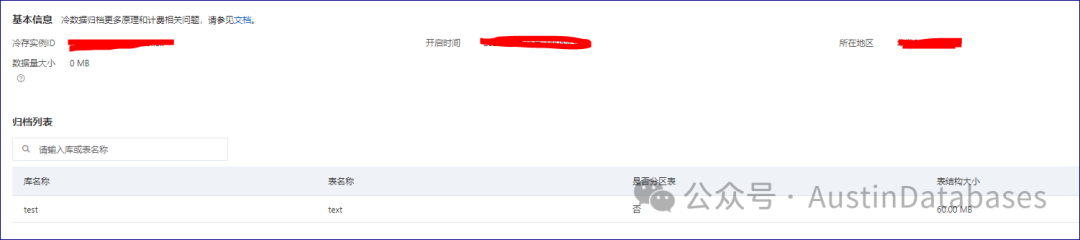
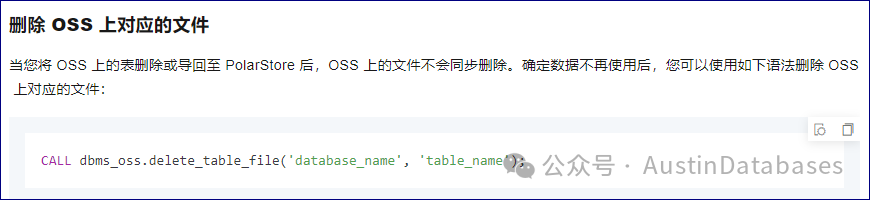
最后我们说一下数据的清理,在MySQL中如果删除一张表我们通过drop table命令来进行,而在PolarDB中,将表归档到OSS 后删除表需要两个步骤。
MySQL [test]> select * from text limit 1;
+----+---------------+
| id | varchar_col |
+----+---------------+
| 1 | data_00000000 |
+----+---------------+
1 row inset (0.003 sec)
MySQL [test]> update text set varchar_col = '11111'where id = 1;
Query OK, 1 row affected (0.006 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL [test]> select * from text limit 1;
+----+-------------+
| id | varchar_col |
+----+-------------+
| 1 | 11111 |
+----+-------------+
1 row inset (0.094 sec)
MySQL [test]> call dbms_oss.delete_table_file('test','text');
ERROR 8079 (HY000): [INNODB OSS] Operation failed. OSS files are still in use.
MySQL [test]> drop table text;
Query OK, 0 rows affected (0.010 sec)
MySQL [test]> call dbms_oss.delete_table_file('test','text');
Query OK, 0 rows affected (0.783 sec)
MySQL [test]>通过上面的演示,POALRDB FOR MYSQL 的数据归档表的方式我已经写清楚了,通过这样的方式,归档将只在库内进行,而不用再库外进行,或者在导出数据,对于一些Saas类的企业,这样的功能简直是到了心坎里面。
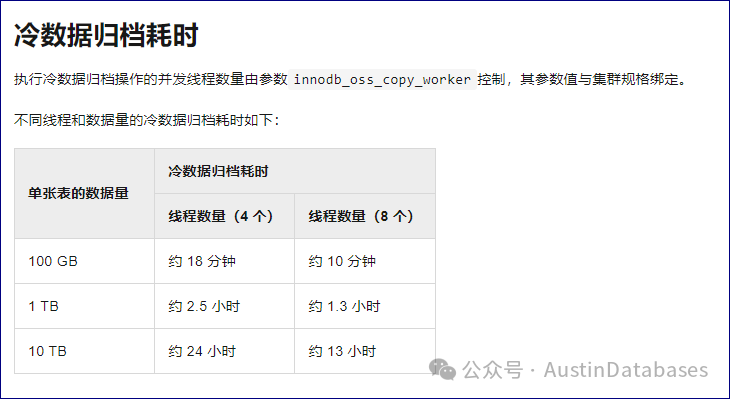
同时对于PolarDB for MySQL的数据归档的性能有相关的说明,我们在使用的过程中也发现时间比我们想的要快,甚至我们都想把一些冷库都转成归档IBD的形式,这是不是太鸡贼了,为了省钱我们是什么都敢干!!
置顶
MongoDB “升级项目” 大型连续剧(1)-- 可“生”可不升
搞 PostgreSQL多才多艺的人--赵渝强 《PG数据库实战派》
阿里云DTS 产品,你真让我出离愤怒,3年了病还没治好???
专访唐建法-从MongoDB中国第一人到TapData掌门人的故事
天上的“PostgreSQL” 说 地上的 PostgreSQL 都是“小垃圾”宇宙的“PostgreSQL” 说 “地球上的PG” 都是“小垃圾”
云数据库核爆在内部,上云下云话题都是皮外伤!--2025云数据库专栏(二)
云原生 DB 技术将取代K8S为基础云数据库服务-- 2025年云数据库专栏(一)
临时工:数据库人生路,如何救赎自己 -- 答某个迷茫DBA的职业咨询
PolarDB 相关文章 PolarDB MySQL 加索引卡主的整体解决方案“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
POLARDB 添加字段 “卡” 住---这锅Polar不背
PolarDB 版本差异分析--外人不知道的秘密(谁是绵羊,谁是怪兽)
PolarDB 答题拿-- 飞刀总的书、同款卫衣、T恤,来自杭州的Package(活动结束了)
PolarDB for MySQL 三大核心之一POLARFS 今天扒开它--- 嘛是火
MySQL相关文章
MySQL 的SQL引擎很差吗?由一个同学提出问题引出的实验
用MySql不是MySQL, 不用MySQL都是MySQL 横批 哼哼哈哈啊啊
MYSQL --Austindatabases 历年文章合集
PostgreSQL 相关文章
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
PostgreSQL 添加索引导致崩溃,参数调整需谨慎--文档未必完全覆盖场景
PostgreSQL SQL优化用兵法,优化后提高 140倍速度
PostgreSQL 运维的难与“难” --上海PG大会主题记录
PostgreSQL 什么都能存,什么都能塞 --- 你能成熟一点吗?
全世界都在“搞” PostgreSQL ,从Oracle 得到一个“馊主意”开始
PostgreSQL 加索引系统OOM 怨我了--- 不怨你怨谁
PostgreSQL “我怎么就连个数据库都不会建?” --- 你还真不会!
病毒攻击PostgreSQL暴力破解系统,防范加固系统方案(内附分析日志脚本)
PostgreSQL 远程管理越来越简单,6个自动化脚本开胃菜
PostgreSQL 稳定性平台 PG中文社区大会--杭州来去匆匆
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
POSTGRESQL --Austindatabaes 历年文章整理
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
PostgreSQL 字符集乌龙导致数据查询排序的问题,与 MySQL 稳定 "PG不稳定"
PostgreSQL Patroni 3.0 新功能规划 2023年 纽约PG 大会 (音译)
PostgreSQL 玩PG我们是认真的,vacuum 稳定性平台我们有了
PostgreSQL DBA硬扛 垃圾 “开发”,“架构师”,滥用PG 你们滚出 !(附送定期清理连接脚本)
OceanBase 相关文章
OceanBase 6大学习法--OBCA视频学习总结第六章
OceanBase 6大学习法--OBCA视频学习总结第五章--索引与表设计
OceanBase 6大学习法--OBCA视频学习总结第五章--开发与库表设计
OceanBase 6大学习法--OBCA视频学习总结第四章 --数据库安装
OceanBase 6大学习法--OBCA视频学习总结第三章--数据库引擎
OceanBase 架构学习--OB上手视频学习总结第二章 (OBCA)
OceanBase 6大学习法--OB上手视频学习总结第一章
没有谁是垮掉的一代--记 第四届 OceanBase 数据库大赛
跟我学OceanBase4.0 --阅读白皮书 (OB分布式优化哪里了提高了速度)
跟我学OceanBase4.0 --阅读白皮书 (4.0优化的核心点是什么)
跟我学OceanBase4.0 --阅读白皮书 (0.5-4.0的架构与之前架构特点)
跟我学OceanBase4.0 --阅读白皮书 (旧的概念害死人呀,更新知识和理念)
OceanBase 学习记录-- 建立MySQL租户,像用MySQL一样使用OB
MongoDB 相关文章
MongoDB “升级项目” 大型连续剧(1)-- 可“生”可不升
MongoDB 大俗大雅,上来问分片真三俗 -- 4 分什么分
MongoDB 大俗大雅,高端知识讲“庸俗” --3 奇葩数据更新方法
MongoDB 大俗大雅,高端的知识讲“通俗” -- 2 嵌套和引用
MongoDB 大俗大雅,高端的知识讲“低俗” -- 1 什么叫多模
MongoDB 合作考试报销活动 贴附属,MongoDB基础知识速通
MongoDB 使用网上妙招,直接DOWN机---清理表碎片导致的灾祸 (送书活动结束)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
MongoDB 双机热备那篇文章是 “毒”
MongoDB 会丢数据吗?在次补刀MongoDB 双机热备
MONGODB ---- Austindatabases 历年文章合集
临时工访谈系列
没有谁是垮掉的一代--记 第四届 OceanBase 数据库大赛
SQL SERVER 系列
SQL SERVER 如何实现UNDO REDO 和PostgreSQL 有近亲关系吗



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









