






❝开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, OceanBase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共3000人左右 1 + 2 + 3 + 4 +5 + 6 + 7 + 8 +9)(1 2 3 4 5 6 7群均已爆满,开8群350+ 9群 150+)
一直使用PolarDB for MySQL,很多人其实好奇到底PolarDB for MySQL数据库本身到底比MySQL强在哪里,SQL的执行有什么不同,怎么优化SQL,方案是什么。今天我们来一个真实的优化案例,来看看PolarDB在运行SQL的时候和MySQL有什么不同,今天我们来实战一下。
首先要说明的是PolarDB for MySQL,使用起来和MySQL没有太多的不同,而且PolarDB for MySQL商业在8.0上又两个版本,8.01 ,8.02。今天我们用的是MySQL的8.01,相对来说现在我更愿意推荐大家使用8.02因为哪个版本上的黑科技比8.01厉害多了,如果要比喻的话,应该是MySQL如果算凡人的话,PolarDB for MySQL 8.01相当于终结者 T800, PolarDB for MySQL8.02相当于终结者 T-X。(没看过终结者的可以自行查询之间的区别)。
今天我们还是拿终结者T800来运行SQL,来比对一下与传统的MySQL有什么不同。
1 并行能力 如果你有PolarDB for MySQL 8.01的版本,可以和我一起做,我们先产生几个表,然后我们灌入数据。
-- 用户表(100 万)
CREATE TABLE users (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
region_id INT,
created_at DATETIME
);
-- 地区表(100 条)
CREATE TABLE regions (
id INT PRIMARY KEY,
name VARCHAR(100)
);
-- 订单表(100 万条)
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
user_id BIGINT,
product_id BIGINT,
amount DECIMAL(10,2),
created_at DATETIME,
status VARCHAR(20),
INDEX(user_id),
INDEX(created_at)
);
-- 产品表(1 万条)
CREATE TABLE products (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
category VARCHAR(50)
);-- 插入地区
INSERT INTO regions (id, name)
SELECT seq, CONCAT('Region_', seq)
FROM (
SELECT 1 AS seq UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5
UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10
) AS a;
-- 插入用户
DELIMITER //
CREATE PROCEDURE insert_users()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000000 DO
INSERT INTO users (id, name, region_id, created_at)
VALUES (i, CONCAT('User_', i), FLOOR(1 + RAND() * 10), NOW() - INTERVAL FLOOR(RAND() * 365) DAY);
SET i = i + 1;
END WHILE;
END;
//
DELIMITER ;
CALL insert_users();
-- 插入产品
INSERT INTO products (id, name, category)
SELECT seq, CONCAT('Product_', seq), CONCAT('Category_', FLOOR(RAND() * 10))
FROM (
SELECT @row := @row + 1 AS seq FROM
(SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3) t1,
(SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3) t2,
(SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3) t3,
(SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3) t4,
(SELECT @row := 0) t0
LIMIT 10000
) AS derived;
-- 插入订单
DELIMITER //
CREATE PROCEDURE insert_orders()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000000 DO
INSERT INTO orders (id, user_id, product_id, amount, created_at, status)
VALUES (
i,
FLOOR(1 + RAND() * 1000000),
FLOOR(1 + RAND() * 10000),
ROUND(100 + (RAND() * 900), 2),
NOW() - INTERVAL FLOOR(RAND() * 365) DAY,
IF(RAND() > 0.5, 'paid', 'pending')
);
SET i = i + 1;
END WHILE;
END;
//
DELIMITER ;
CALL insert_orders();explain SELECT
r.name AS region_name,
p.category,
COUNT(*) AS total_orders,
SUM(o.amount) AS total_amount
FROM orders o
JOIN users u ON o.user_id = u.id
JOIN regions r ON u.region_id = r.id
JOIN products p ON o.product_id = p.id
WHERE o.created_at >= NOW() - INTERVAL 90 DAY
AND o.status = 'paid'
GROUP BY r.name, p.category
ORDER BY total_amount DESC
LIMIT 20;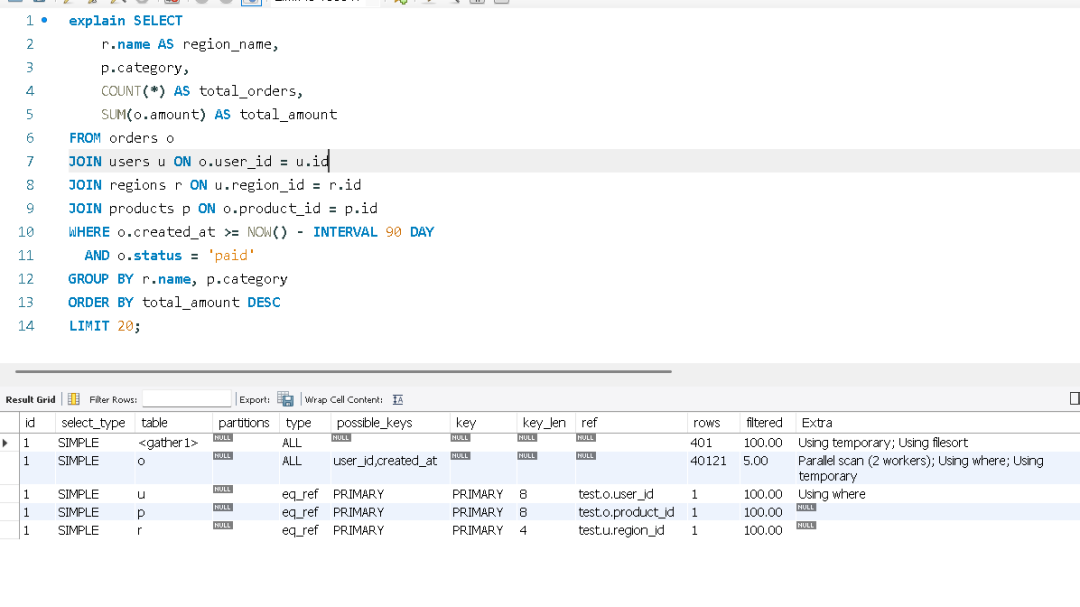
从上图我们可以看出PolarDB for MySQL 8.01在执行SQL的时候和MySQL有明显的不同,这里使用了parallel scan,也就是并行扫描来对SQL进行加速,这也是PolarDB for Mysql 与 MySQL 在执行SQL时的一个最大的不同之一。
1 PolarDB for MySQL 会发现在查询数据量大的情况下,且你没有很好的SQL优化的情况下,自动开启并行。这个语句是没有优化的情况下,POALRDB发现了通过并行数据扫描,可以提高数据查询效率,且比使用现有索引的情况下更可能快速的将查询完成,他将直接使用并行来处理SQL。
这里并行度是可以调整的,通过参数,有足够的CPU可以开启2 4 6 8 16 或更多的并行度,来处理一个SQL,这个功能在MySQL中是不存在的。这也是一个问题在MYSQL中很早就出现的SQL执行的性能问题,在POLARDB FOR MYSQL中因为有并行,很多情况再严重了后才被发现,早期通过并行查询就解决了性能的问题。所以在看到并行的执行计划,就需要看是否是因为SQL没有优化导致的问题。
所以基于POLARDB的优化方案,会和基于MySQL的方案略有不同。
1 添加适合的索引,针对这个SQL,如果可以可以针对orders表的返回数据进行索引覆盖的方案。
CREATE INDEX idx_orders_cover ON orders ( status, created_at, user_id, product_id, amount );
2 针对访问的线程,临时调整临时表和排序的缓存大小,在实验中,临时开大后,语句的执行时间由原来的0.719S 变化为0.516S
SET tmp_table_size = 256 * 1024 * 1024;
SET max_heap_table_size = 256 * 1024 * 1024;
SET sort_buffer_size = 8 * 1024 * 1024;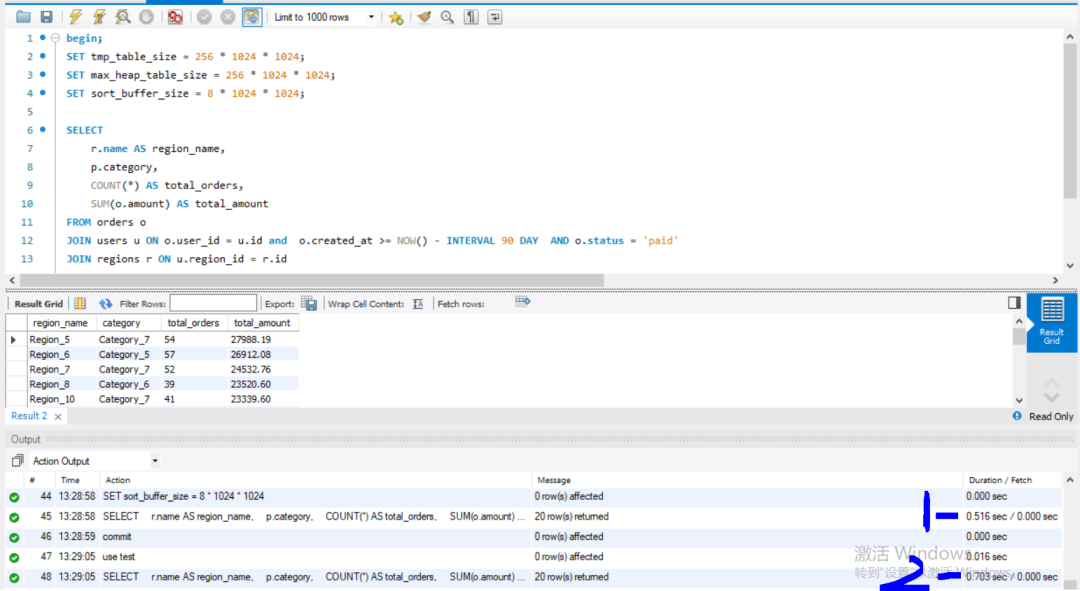
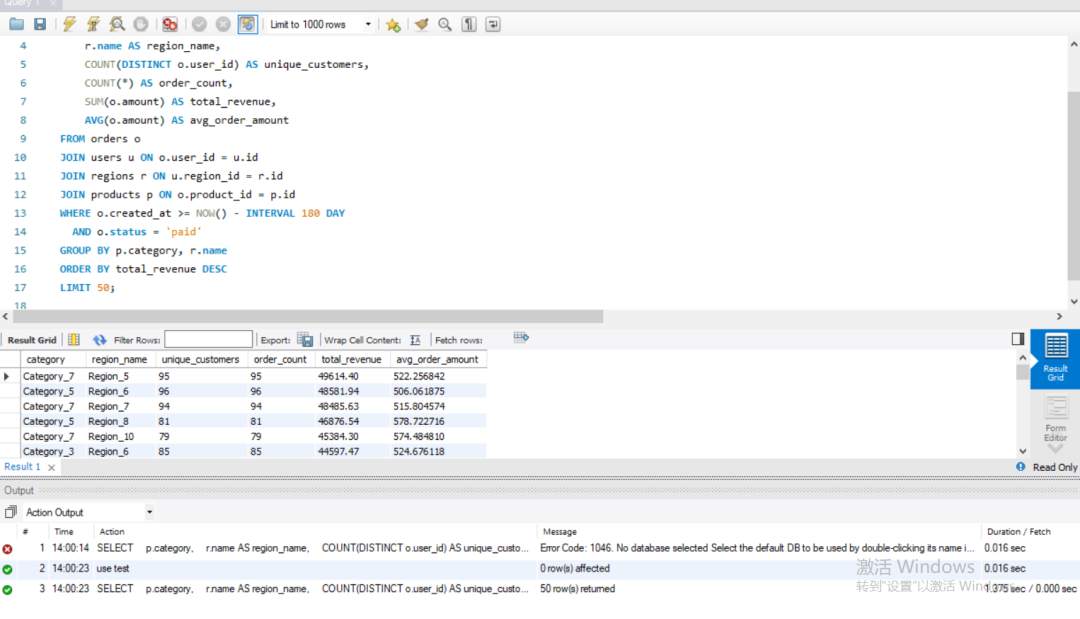
3 如果CPU够多的情况下,且使用了PLS5的磁盘系统,那么可以开大并行,这里可以开到4个并行。

4 如果以上的方案还不能满足实际的需求,可以考虑开启POLARDB FOR MYSQL 的IMCI功能,通过IMCI功能直接对于聚合操作中的部分,变为列式处理。
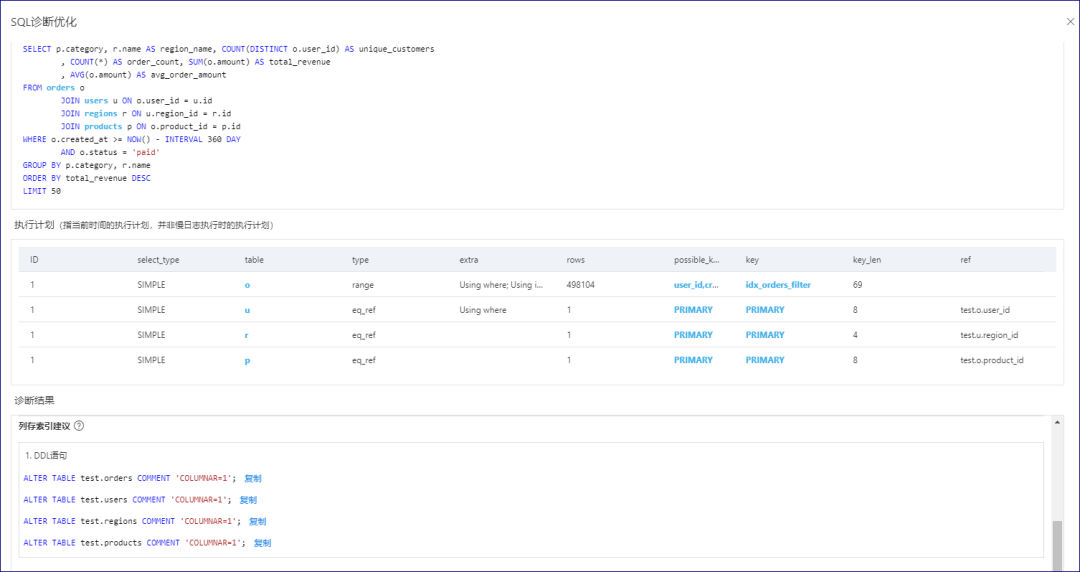
ALTER TABLE orders
ADD COLUMNSTORE INDEX cs_idx_orders
(created_at, status, user_id, product_id, amount);关于POLARDB的IMCI方面属于另一个话题,但在POALRDB FOR MYSQL中是一个完美解决聚合计算的方案,添加一个列式的节点,添加上面的索引后,相关的查询就和飞了一样相当于,MYSQL+CLICKHOUSE的方案,但这里数据在行列中,我们可以认为是同步的,这点 MYSQL + Clickhouse又做不到。
所以这也是我们为什么把MySQL在云上都踢掉的原因,因为MySQL在云原生数据库的面前,都是短处,我要你何用。
总结:在云上使用POLARDB FOR MYSQL,针对SQL的优化的方案很多,且很灵活。在MySQL无法优化的SQL,或者需要改写的部分,放到POLARDB 上很多都不用改写,多种方案齐下手,大部分问题都能解决,所以MYSQL 我真的没法用你,在云上抱歉了MySQL。
置顶
PostgreSQL 新版本就一定好--由培训现象让我做的实验
删除数据“八扇屏” 之 锦门英豪 --我去-BigData!
写了3750万字的我,在2000字的OB白皮书上了一课--记 《OceanBase 社区版在泛互场景的应用案例研究》
疯狂老DBA 和 年轻“网红” 程序员 --火星撞地球-- 谁也不是怂货
和架构师沟通那种“一坨”的系统,推荐只能是OceanBase,Why ?
OceanBase 相关文章写了3750万字的我,在2000字的OB白皮书上了一课--记 《OceanBase 社区版在泛互场景的应用案例研究》
OceanBase 6大学习法--OBCA视频学习总结第六章
OceanBase 6大学习法--OBCA视频学习总结第五章--索引与表设计
OceanBase 6大学习法--OBCA视频学习总结第五章--开发与库表设计
OceanBase 6大学习法--OBCA视频学习总结第四章 --数据库安装
OceanBase 6大学习法--OBCA视频学习总结第三章--数据库引擎
OceanBase 架构学习--OB上手视频学习总结第二章 (OBCA)
OceanBase 6大学习法--OB上手视频学习总结第一章
没有谁是垮掉的一代--记 第四届 OceanBase 数据库大赛
跟我学OceanBase4.0 --阅读白皮书 (OB分布式优化哪里了提高了速度)
跟我学OceanBase4.0 --阅读白皮书 (4.0优化的核心点是什么)
跟我学OceanBase4.0 --阅读白皮书 (0.5-4.0的架构与之前架构特点)
跟我学OceanBase4.0 --阅读白皮书 (旧的概念害死人呀,更新知识和理念)
OceanBase 学习记录-- 建立MySQL租户,像用MySQL一样使用OB
MongoDB 相关文章
MongoDB “升级项目” 大型连续剧(4)-- 与开发和架构沟通与扫尾
MongoDB “升级项目” 大型连续剧(3)-- 自动校对代码与注意事项
MongoDB “升级项目” 大型连续剧(2)-- 到底谁是"der"
MongoDB “升级项目” 大型连续剧(1)-- 可“生”可不升
MongoDB 大俗大雅,上来问分片真三俗 -- 4 分什么分
MongoDB 大俗大雅,高端知识讲“庸俗” --3 奇葩数据更新方法
MongoDB 大俗大雅,高端的知识讲“通俗” -- 2 嵌套和引用
MongoDB 大俗大雅,高端的知识讲“低俗” -- 1 什么叫多模
MongoDB 合作考试报销活动 贴附属,MongoDB基础知识速通
MongoDB 使用网上妙招,直接DOWN机---清理表碎片导致的灾祸 (送书活动结束)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
MongoDB 双机热备那篇文章是 “毒”
MongoDB 会丢数据吗?在次补刀MongoDB 双机热备
MONGODB ---- Austindatabases 历年文章合集
PolarDB 相关文章
MySQL 和 PostgreSQL 可以一起快速发展,提供更多的功能?
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
POLARDB 添加字段 “卡” 住---这锅Polar不背
PolarDB 版本差异分析--外人不知道的秘密(谁是绵羊,谁是怪兽)
PolarDB 答题拿-- 飞刀总的书、同款卫衣、T恤,来自杭州的Package(活动结束了)
PolarDB for MySQL 三大核心之一POLARFS 今天扒开它--- 嘛是火
PostgreSQL 相关文章
PostgreSQL 新版本就一定好--由培训现象让我做的实验
PostgreSQL 无服务 Neon and Aurora 新技术下的新经济模式 (翻译)
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
PostgreSQL 添加索引导致崩溃,参数调整需谨慎--文档未必完全覆盖场景
PostgreSQL SQL优化用兵法,优化后提高 140倍速度
PostgreSQL 运维的难与“难” --上海PG大会主题记录
PostgreSQL 什么都能存,什么都能塞 --- 你能成熟一点吗?
全世界都在“搞” PostgreSQL ,从Oracle 得到一个“馊主意”开始
PostgreSQL 加索引系统OOM 怨我了--- 不怨你怨谁
PostgreSQL “我怎么就连个数据库都不会建?” --- 你还真不会!
病毒攻击PostgreSQL暴力破解系统,防范加固系统方案(内附分析日志脚本)
PostgreSQL 远程管理越来越简单,6个自动化脚本开胃菜
PostgreSQL 稳定性平台 PG中文社区大会--杭州来去匆匆
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
POSTGRESQL --Austindatabaes 历年文章整理
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
PostgreSQL 字符集乌龙导致数据查询排序的问题,与 MySQL 稳定 "PG不稳定"
PostgreSQL Patroni 3.0 新功能规划 2023年 纽约PG 大会 (音译)
PostgreSQL 玩PG我们是认真的,vacuum 稳定性平台我们有了
PostgreSQL DBA硬扛 垃圾 “开发”,“架构师”,滥用PG 你们滚出 !(附送定期清理连接脚本)
MySQL相关文章
MySQL 的SQL引擎很差吗?由一个同学提出问题引出的实验
用MySql不是MySQL, 不用MySQL都是MySQL 横批 哼哼哈哈啊啊
MYSQL --Austindatabases 历年文章合集
临时工访谈系列
没有谁是垮掉的一代--记 第四届 OceanBase 数据库大赛
SQL SERVER 系列
SQL SERVER 如何实现UNDO REDO 和PostgreSQL 有近亲关系吗



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









