







原文转自:http://blog.csdn.net/baimafujinji/article/details/6496222
一、 引言
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
尽管kNN算法的思想比较简单,但它仍然是一种非常重要的机器学习(或数据挖掘)算法。在2006年12月召开的 IEEE
International Conference on Data Mining (ICDM),与会的各位专家选出了当时的十大数据挖掘算法( top 10 data mining algorithms ),可以参加文献【1】, K最近邻算法即位列其中。
其他本博客已经介绍过的且位列十大算法之中的还包括:
二、在Matlab中利用kNN进行最近邻查询
如果手头有一些数据点(以及它们的特征向量)构成的数据集,对于一个查询点,我们该如何高效地从数据集中找到它的最近邻呢?最通常的方法是基于k-d-tree进行最近邻搜索。限于篇幅,本文不会对k-d-tree做过深的讨论,对此还不甚了解的读者可以参考http://blog.csdn.net/baimafujinji/article/details/52928203。
KNN算法不仅可以用于分类,还可以用于回归,但主要应用于回归,所以下面我们就演示在MATLAB中利用KNN算法进行数据挖掘的基本方法。我们所选用的数据集,仍然是较为常用的费希尔鸢尾花数据集,有关这组数据集的基本情况可以参考http://blog.csdn.net/baimafujinji/article/details/49885481。
首先在Matlab中载入数据,代码如下,其中meas( : , 3:4)相当于取出(之前文章中的)Petal.Length和Petal.Width这两列数据,一共150行,三类鸢尾花每类各50行。
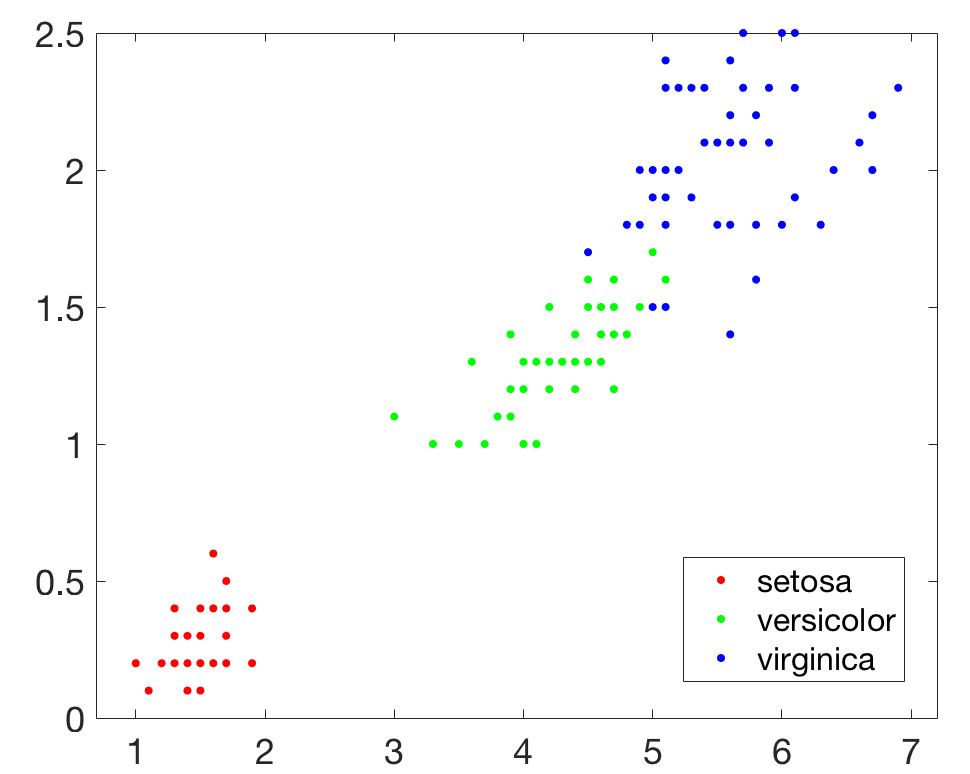
然后我们可以借助下面的代码来用图形化的方式展示一下数据的分布情况:
执行上述代码,结果如下图所示:
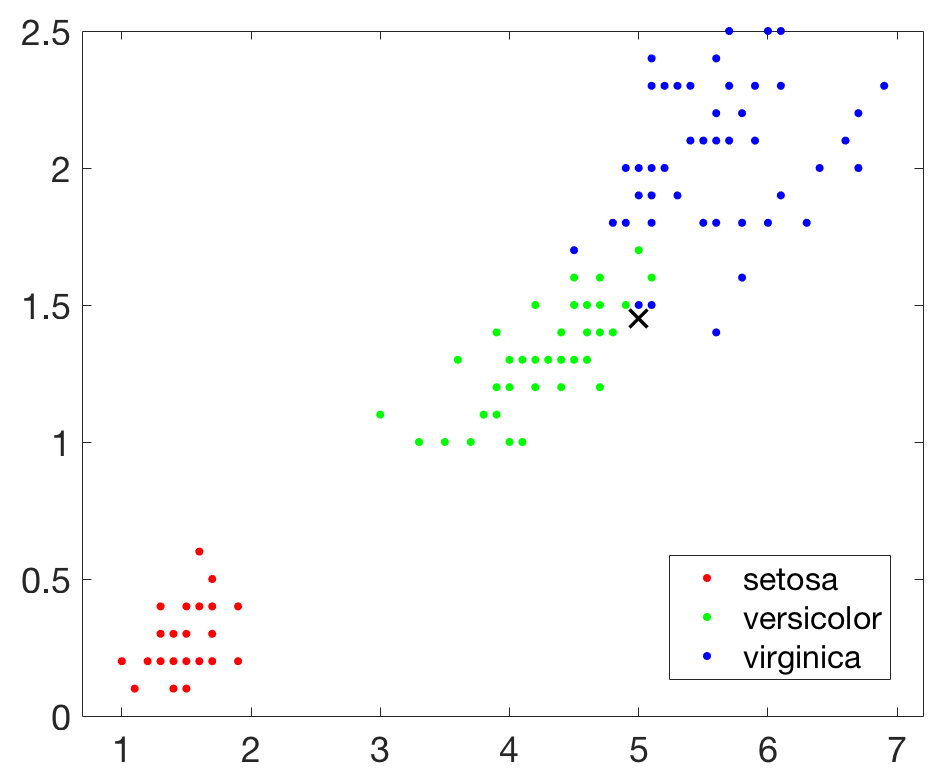
然后我们在引入一个新的查询点,并在图上把该点用×标识出来:
结果如下图所示:
接下来建立一个基于KD-Tree的最近邻搜索模型,查询目标点附近的10个最近邻居,并在图中用圆圈标识出来。
下图显示确实找出了查询点周围的若干最近邻居,但是好像只要8个,
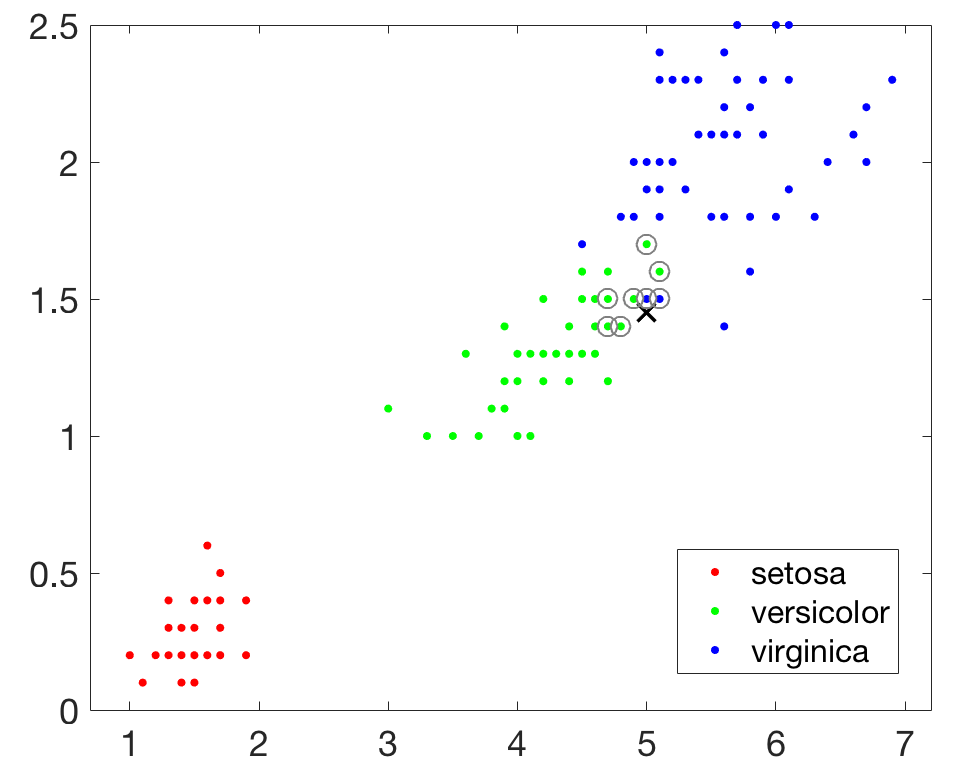
不用着急,其实系统确实找到了10个最近邻居,但是其中有两对数据点完全重合,所以在图上你只能看到8个,不妨把所有数据都输出来看看,如下所示,可知确实是10个。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。例如下面的代码告诉我们,待查询点的邻接中有80%是versicolor类型的鸢尾花,所以如果采用KNN来进行分类,那么待查询点的预测分类结果就应该是versicolor类型。
在利用 KNN方法进行类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
我们还要说明在Matlab中使用KDTreeSearcher进行最近邻搜索时,距离度量的类型可以是欧拉距离(
三、利用kNN进行数据挖掘的实例
下面我们来演示在MATLAB构建kNN分类器,并以此为基础进行数据挖掘的具体步骤。首先还是载入鸢尾花数据,不同的是这次我们使用全部四个特征来训练模型。
然后使用fitcknn()函数来训练分类器模型。
你可以看到默认情况下,最近邻的数量为1,下面我们把它调整为4。
或者你可以使用下面的代码来完成上面同样的任务:
既然有了模型,我们能否利用它来执行以下预测分类呢,具体来说此时我们需要使用predict()函数,例如
最后,我们还可以来评估一下建立的kNN分类模型的情况。例如你可以从已经建好的模型中建立一个cross-validated 分类器:
然后再来看看cross-validation loss,它给出了在对那些没有用来训练的数据进行预测时每一个交叉检验模型的平均损失
再来检验一下resubstitution loss, which,默认情况下,它给出的是模型Mdl预测结果中被错误分类的数据占比。
如你所见,cross-validated 分类准确度与 resubstitution 准确度大致相近。所以你可以认为你的模型在面对新数据时(假设新数据同训练数据具有相同分布的话),分类错误的可能性大约是 4% 。
四、关于k值的选择
kNN算法在分类时的主要不足在于,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。因此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
从另外一个角度来说,算法中k值的选择对模型本身及其对数据分类的判定结果都会产生重要影响。如果选择较小的k值,就相当于用较小的领域中的训练实例来进行预测,学习的近似误差会减小,只有与输入实例较为接近(相似的)训练实例才会对预测结果起作用。但缺点是“学习”的估计误差会增大。预测结果会对近邻的实例点非常敏感。如果临近的实例点恰巧是噪声,预测就会出现错误。换言之,k值的减小意味着整体模型变得复杂,容易发成过拟合。
如果选择较大的k值,就相当于用较大的邻域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。k值的增大就意味着整体的模型变得简单。
在应用中,k值一般推荐取一个相对比较小的数值。并可以通过交叉验证法来帮助选取最优k值。
尽管kNN算法的思想比较简单,但它仍然是一种非常重要的机器学习(或数据挖掘)算法。在2006年12月召开的 IEEE
International Conference on Data Mining (ICDM),与会的各位专家选出了当时的十大数据挖掘算法( top 10 data mining algorithms ),可以参加文献【1】, K最近邻算法即位列其中。
其他本博客已经介绍过的且位列十大算法之中的还包括:
- [1] k-means算法(http://blog.csdn.net/baimafujinji/article/details/50570824)
- [2] 支持向量机SVM(http://blog.csdn.net/baimafujinji/article/details/49885481)
- [3] EM算法(http://blog.csdn.net/baimafujinji/article/details/50626088)
- [4] 朴素贝叶斯算法(http://blog.csdn.net/baimafujinji/article/details/50441927)
二、在Matlab中利用kNN进行最近邻查询
如果手头有一些数据点(以及它们的特征向量)构成的数据集,对于一个查询点,我们该如何高效地从数据集中找到它的最近邻呢?最通常的方法是基于k-d-tree进行最近邻搜索。限于篇幅,本文不会对k-d-tree做过深的讨论,对此还不甚了解的读者可以参考http://blog.csdn.net/baimafujinji/article/details/52928203。
KNN算法不仅可以用于分类,还可以用于回归,但主要应用于回归,所以下面我们就演示在MATLAB中利用KNN算法进行数据挖掘的基本方法。我们所选用的数据集,仍然是较为常用的费希尔鸢尾花数据集,有关这组数据集的基本情况可以参考http://blog.csdn.net/baimafujinji/article/details/49885481。
首先在Matlab中载入数据,代码如下,其中meas( : , 3:4)相当于取出(之前文章中的)Petal.Length和Petal.Width这两列数据,一共150行,三类鸢尾花每类各50行。
然后我们可以借助下面的代码来用图形化的方式展示一下数据的分布情况:
执行上述代码,结果如下图所示:
结果如下图所示:
接下来建立一个基于KD-Tree的最近邻搜索模型,查询目标点附近的10个最近邻居,并在图中用圆圈标识出来。
下图显示确实找出了查询点周围的若干最近邻居,但是好像只要8个,
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。例如下面的代码告诉我们,待查询点的邻接中有80%是versicolor类型的鸢尾花,所以如果采用KNN来进行分类,那么待查询点的预测分类结果就应该是versicolor类型。
在利用 KNN方法进行类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
我们还要说明在Matlab中使用KDTreeSearcher进行最近邻搜索时,距离度量的类型可以是欧拉距离(
'euclidean')、曼哈顿距离('cityblock')、闵可夫斯基距离('minkowski')、切比雪夫距离('chebychev'),缺省情况下系统使用欧拉距离。你甚至还可以自定义距离函数,然后使用knnsearch()函数来进行最近邻搜索,具体可以查看MATLAB的帮助文档,我们不具体展开。三、利用kNN进行数据挖掘的实例
下面我们来演示在MATLAB构建kNN分类器,并以此为基础进行数据挖掘的具体步骤。首先还是载入鸢尾花数据,不同的是这次我们使用全部四个特征来训练模型。
然后使用fitcknn()函数来训练分类器模型。
你可以看到默认情况下,最近邻的数量为1,下面我们把它调整为4。
或者你可以使用下面的代码来完成上面同样的任务:
既然有了模型,我们能否利用它来执行以下预测分类呢,具体来说此时我们需要使用predict()函数,例如
最后,我们还可以来评估一下建立的kNN分类模型的情况。例如你可以从已经建好的模型中建立一个cross-validated 分类器:
然后再来看看cross-validation loss,它给出了在对那些没有用来训练的数据进行预测时每一个交叉检验模型的平均损失
再来检验一下resubstitution loss, which,默认情况下,它给出的是模型Mdl预测结果中被错误分类的数据占比。
如你所见,cross-validated 分类准确度与 resubstitution 准确度大致相近。所以你可以认为你的模型在面对新数据时(假设新数据同训练数据具有相同分布的话),分类错误的可能性大约是 4% 。
四、关于k值的选择
kNN算法在分类时的主要不足在于,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。因此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
从另外一个角度来说,算法中k值的选择对模型本身及其对数据分类的判定结果都会产生重要影响。如果选择较小的k值,就相当于用较小的领域中的训练实例来进行预测,学习的近似误差会减小,只有与输入实例较为接近(相似的)训练实例才会对预测结果起作用。但缺点是“学习”的估计误差会增大。预测结果会对近邻的实例点非常敏感。如果临近的实例点恰巧是噪声,预测就会出现错误。换言之,k值的减小意味着整体模型变得复杂,容易发成过拟合。
如果选择较大的k值,就相当于用较大的邻域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。k值的增大就意味着整体的模型变得简单。
在应用中,k值一般推荐取一个相对比较小的数值。并可以通过交叉验证法来帮助选取最优k值。
参考文献
【1】Wu, X., Kumar, V., Quinlan, J.R., Ghosh, J., Yang, Q., Motoda, H., McLachlan, G.J., Ng, A., Liu, B., Philip, S.Y. and Zhou, Z.H., 2008. Top 10 algorithms in data mining. Knowledge and information systems, 14(1), pp.1-37. (http://www.cs.uvm.edu/~icdm/algorithms/10Algorithms-08.pdf)
【2】http://au.mathworks.com/help/stats/classification-using-nearest-neighbors.html
【3】李航,统计学习方法,清华大学出版社















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









