










一 MapReduce中Map和Reduce的任务数量
中间数据回写到磁盘中,运行速度慢,适合处理海量的离线大数据
spark和storm等都不往磁盘中写文件,处理速度快,因此适合处理实时数据。但并不能真正的代替mapreduce。
Map task的并发数量:
1.map task的并发是由切片的数量决定的,有多少个切片,就启动多少个map task
2.切片是一个逻辑的概念,指的是文件中数据的偏移量范围
3.切片的具体大小应该是根据处理的文件的大小来调整
Reduce task的并发数量:
通过 job.setNumReduceTasks(taks)来设置任务的个数
PS:切记,设置reduce的分组数,应该和分组数一致。
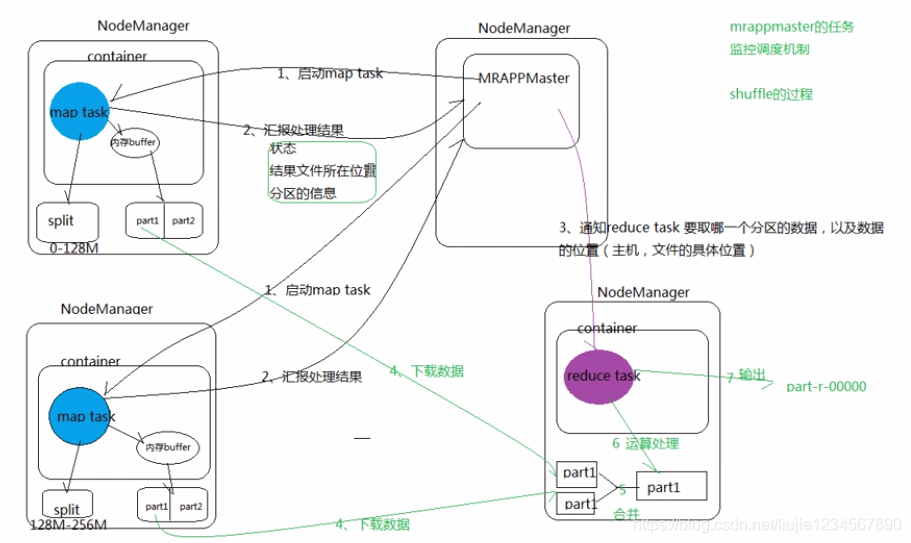
二 MRAppMaster的任务监控调度机制和shuffle的过程:
1.MRAppMaster启动map task
2.汇报处理结果(状态,结果文件所在的位置,分区的信息)
3.启动reduce task,并通知reduce task要取哪个分区的数据以及数据的位置(两个位置:主机和文件的具体位置)
4.下载map的文件
5.对下载的文件进行合并
6.reduce进行运算处理
7.输出到具体的文件part-r-0000…
如图所示:
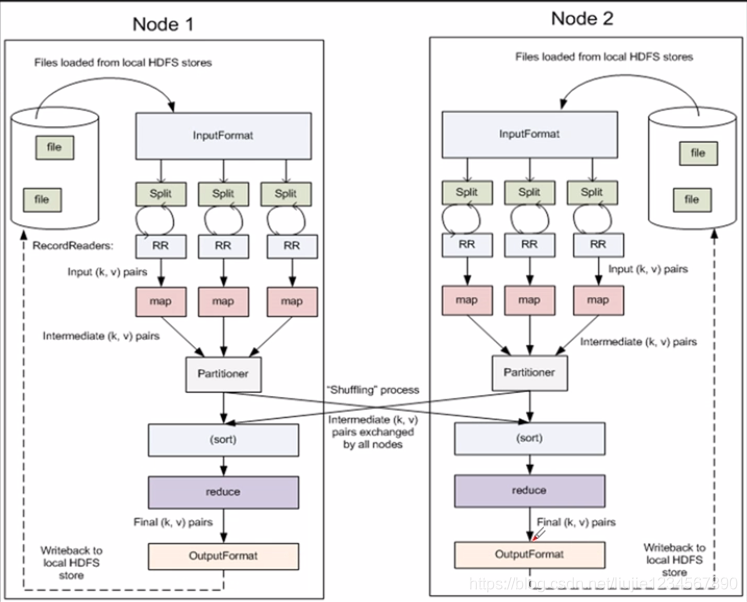
三 MR的组件全貌:
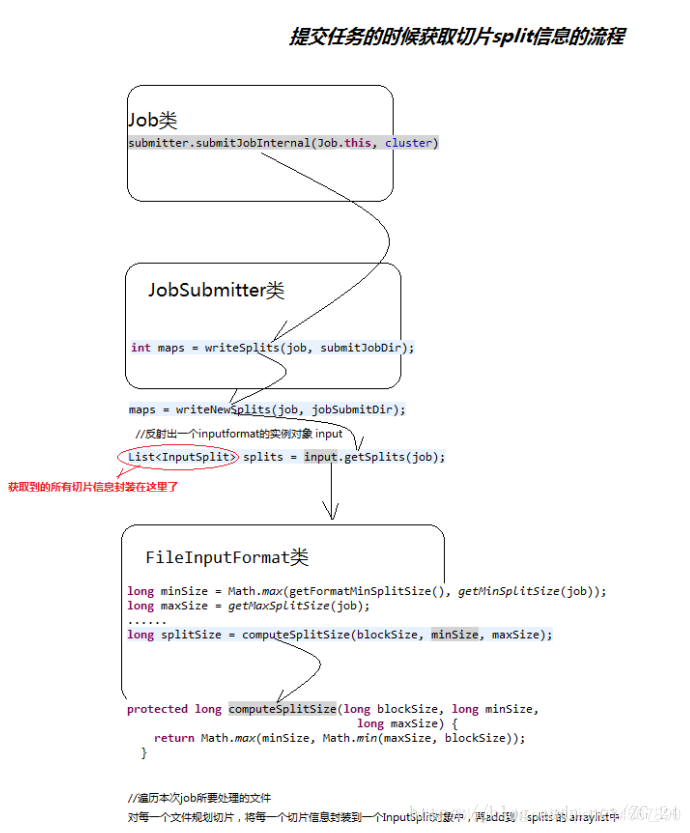
四 textinputformat对切片规划的源码分析














 2124
2124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









