









实现目标
1、支持文本中英文互译;
2、支持中文语音输入;
3、支持英文语言输入;
进阶(未实现)
4、优化web界面;
5、优化语音输入js实现逻辑;
6、增加语音输入自纠错模型,纠正语音识别输出;
7、增加中文文本转语音输出;
8、增加英语文本转语音输出。
环境
在实现语音识别前,需要获取符合语音识别模型格式的语音文件。按照要求,需要提供wav格式,采样频率为16000Hz的音频文件。而通过web API navigator.mediaDevices.getUserMedia获取到的音频文件是webm格式的。如果需要通过web获取wav格式的音频文件,可能比较复杂。因此,通过在后端使用ffmpeg将前端上传的webm格式的音频文件转为wav格式。
ffmpeg -i input_file.webm -ar 16000 output_file.wav
在实际测试过程中,可以将获取到的音频文件直接用notepad++打开查看文件开头,来判断文件的类型。以防外部修改导致的文件格式与文件后缀不一致导致的执行结果混乱的问题。
wav文件:

webm文件:

除了ffmpeg之外的其他重要环境:
Python 3.11.2
Flask 3.0.3
torch 2.3.0
torchaudio 2.3.0
transformers 4.41.2
PySoundFile 0.9.0.post1
实现逻辑
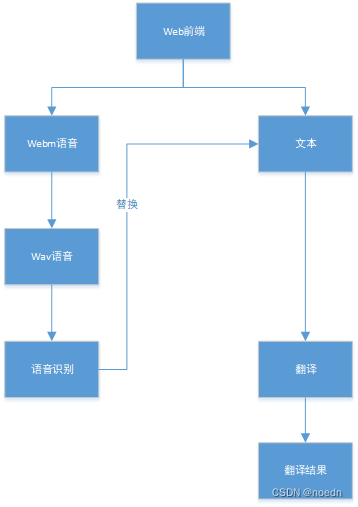
基本实现逻辑是web前端-文本-翻译-翻译结果-返回前端,为了使用的方便,增加了语音输入。语音输入的输出也相当于web前端的文本输入。
在语音输入实现当中,上传语言文件至输出结果最大时间由record.js文件控制。比如,record.js文件当中设置的最大语音识别时间是1秒。那么,如果语音识别结果在1秒之后输出,web页面将无法获取语音识别结果。(语音识别的实现不足:1、识别精准度不足;2、web页面动态更新识别结果实现不完善)
所有源代码
一、项目代码目录结构:
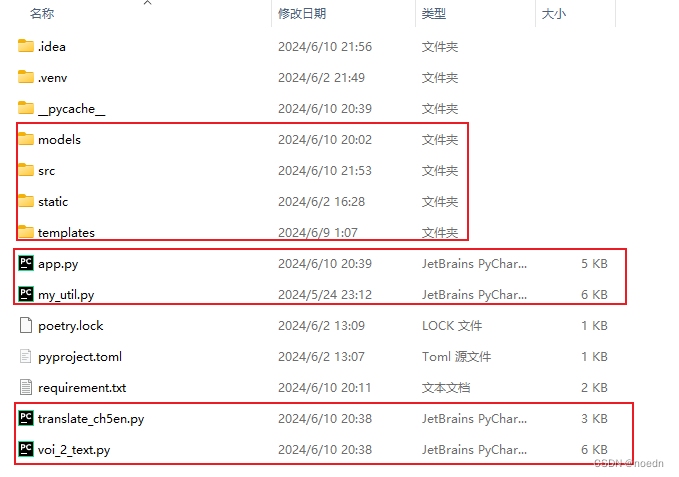
models文件夹:
ch-en中英文文本翻译模型
ch-voi-text中文语音识别模型
en-ch英中文文本翻译模型
en-voi-text英文语音识别模型
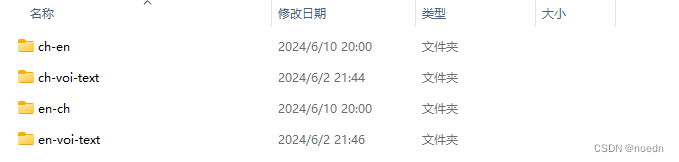
src文件夹:
上传语音文件和logo

static文件夹:
css文件、fonts字体文件、js文件

record.js
const recordBtn = document.querySelector(".record-btn")
const player = document.querySelector(".audio-player")
// const download = document.querySelector('#download')
function getLastSegment(url) {
// 使用URL API来解析URL
const urlObj = new URL(url);
// 获取路径部分并去除开头的斜杠(如果有)
const path = urlObj.pathname.replace(/^\//, '');
// 分割路径并返回最后一段
return path.split('/').pop();
}
function areLastSegmentsEqual(url1, url2) {
// 获取两个URL的最后一段
const segment1 = getLastSegment(url1);
const segment2 = getLastSegment(url2);
// 比较它们是否相同
return segment1 === segment2;
}
if (navigator.mediaDevices.getUserMedia) {
let audioChunks = []
// 约束属性
const constraints = {
// 音频约束
audio: {
sampleRate: 16000, // 采样率
sampleSize: 16, // 每个采样点大小的位数
channelCount: 1, // 通道数
volume: 1, // 从 0(静音)到 1(最大音量)取值,被用作每个样本值的乘数
echoCancellation: true, // 开启回音消除
noiseSuppression: true, // 开启降噪功能
},
// 视频约束
video: false
}
// 请求获取音频流
navigator.mediaDevices.getUserMedia(constraints)
.catch(err => serverLog("ERROR mediaDevices.getUserMedia: ${err}"))
.then(stream => {// 在此处理音频流
// 创建 MediaRecorder 实例
const mediaRecorder = new MediaRecorder(stream)
// 点击按钮
recordBtn.onclick = () => {
if (mediaRecorder.state === "recording") {
// 录制完成后停止
mediaRecorder.stop()
recordBtn.textContent = "录音结束"
}
else {
// 开始录制
mediaRecorder.start()
recordBtn.textContent = "录音中..."
}
}
mediaRecorder.ondataavailable = e => {
audioChunks.push(e.data)
}
// 结束事件
mediaRecorder.onstop = e => {
// 将录制的数据组装成 Blob(binary large object) 对象(一个不可修改的存储二进制数据的容器)
const blob = new Blob(audioChunks, { type: "audio/webm" })
audioChunks = []
const audioURL = window.URL.createObjectURL(blob)
// 赋值给一个 <audio> 元素的 src 属性进行播放
player.src = audioURL
// // 添加下载功能
// download.innerHTML = '下载'
// download.href = audioURL
// 将文件回传
// 准备 FormData 对象用于文件上传
const formData = new FormData();
// 添加 Blob 到 FormData,并为其指定一个名称(这里假设服务器期望的字段名为 'audioFile')
formData.append('audioFile', blob, 'recording.webm'); // 'recording.webm' 是文件的建议名称,不是必须
// 使用 fetch API 发送文件到服务器
fetch('/upload-url', { // 请替换为您的上传 URL
method: 'POST',
body: formData
})
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
return response.text(); // 或者返回 response.json() 如果服务器返回 JSON
})
.then(data => {
console.log('Upload successful:', data);
let textarea = document.getElementById('inputQuestion');
textarea.readOnly = true;
setTimeout(function() {
window.location.reload();
}, 1000); // 等待 1 秒后刷新页面
})
// setInterval(function () {
// const currentUrl = window.location.href;
// alert(currentUrl)
// }, 2000); // 每秒/1000检查一次
// })
.catch(error => {
console.error('There has been a problem with your fetch operation:', error);
});
}
},
() => {
console.error("授权失败!");
}
);
} else {
console.error("该浏览器不支持 getUserMedia!");
}
templates文件夹:
所有web页面的html文件
home.html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>开始页面</title>
<link rel="stylesheet" href="/static/css/bootstrap.css">
<style>
/*static 文件夹是默认用于存放静态文件的,比如 CSS、JavaScript、图片和字体文件等。
Flask 会自动为 static 文件夹下的所有文件提供静态文件的路由,使得这些文件可以被直接访问,
而不需要你为每个文件单独编写路由。*/
@font-face {
font-family: 'KingHwa'; /* 自定义字体名称 */
/*此处将字体文件加入到static文件夹当中,就省去了编写路由的工作,ttf文件对应路由格式truetype*/
src: url('../static/fonts/KingHwa_OldSong.ttf') format('truetype');/* 字体文件路径和格式 */
font-weight: normal;
font-style: normal;
}
body {
background-color: rgba(173, 216, 230, 0.5); /*设置页面背景颜色*/
font-family: "KingHwa", sans-serif; /*设置字体*/
}
.center-image {
/*position: fixed;*/
display: block;
margin-top: 4%;
margin-left: 40%;
margin-right: 40%;
border-radius: 4%; /* 设置圆角大小 */
width: 20%; /* 你可以根据需要调整宽度 */
}
.center-bnt {
/*position: fixed;*/
display: block;
{#margin-top: 10%;#}
margin-top: 5%;
margin-left: 45%;
margin-right: 45%;
width: 10%; /* 你可以根据需要调整宽度 */
}
.rounded-font {
display: block;
margin-top: 8%;
border-radius: 2%; /* 设置圆角大小 */
font-size: 360%; /* 设置字体大小 */
text-align: center; /* 将文本居中 */
}
#backToTop {
position: fixed;
bottom: 20px;
right: 30px;
z-index: 99;
border: none;
outline: 1px solid black;/*设置轮廓*/
background-color: rgba(0, 0, 230, 0.5);
color: white;
cursor: pointer;
padding: 4px 5px;
border-radius: 2px;/*设置圆角*/
}
</style>
</head>
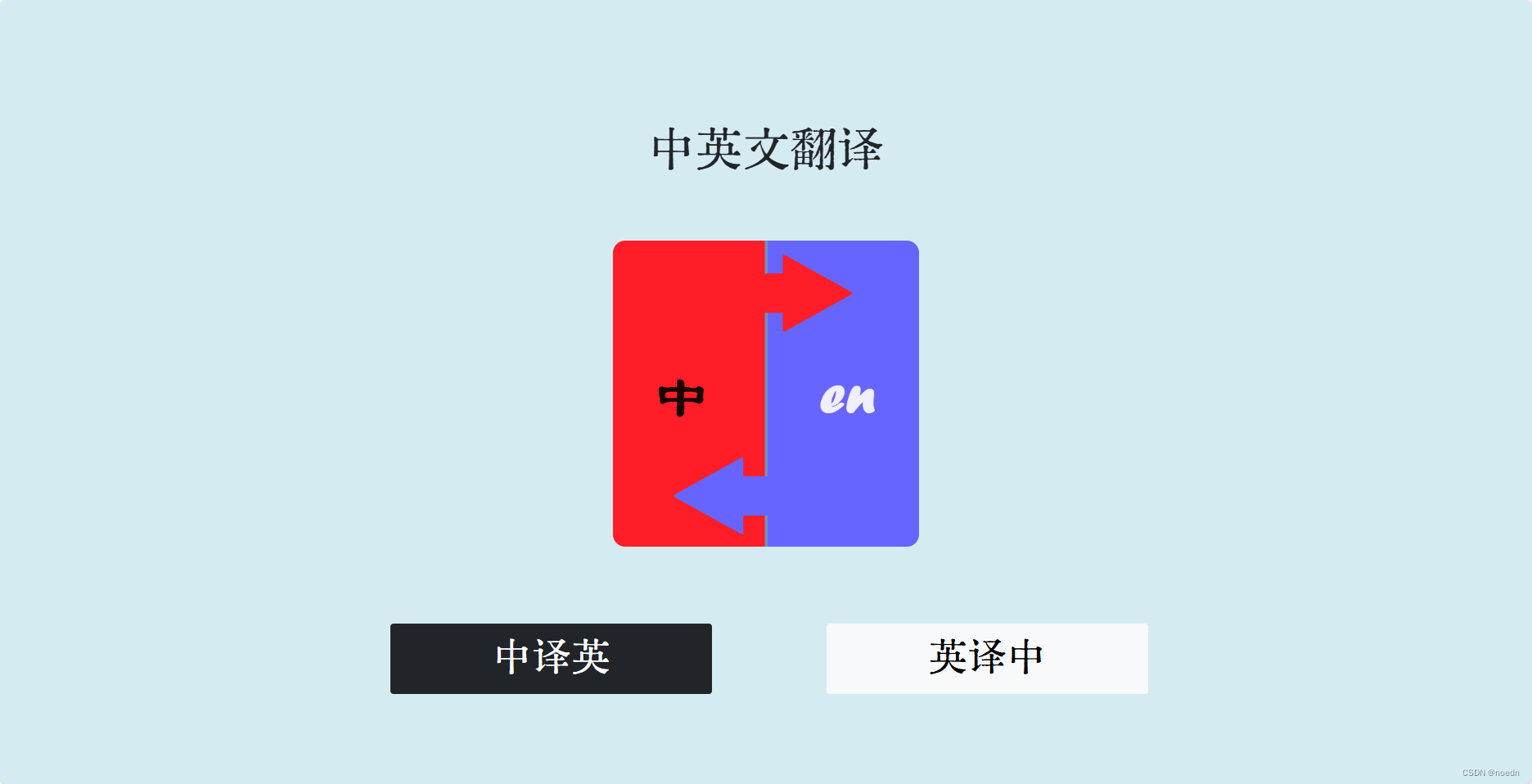
<h1 class="rounded-font">中英文翻译</h1>
<img src="{{ url_for('send_image', path='src/translate.jpg') }}"
alt="中英文翻译"
class="center-image"
style="margin-bottom:5%">
<body>
<form action='/home' style="width:70%; margin:0 auto;" method="post">
<button type="submit"
class="btn btn-primary btn-dark"
style="font-size: 300%; width: 30%; margin-left:15%; margin-right:5%;"
name="choice" value="ch2en">中译英</button>
<button type="submit"
class="btn btn-primary btn-light"
style="font-size: 300%; width: 30%; margin-left:5%;"
name="choice" value="en2ch">英译中</button>
</form>
</body>
</html>
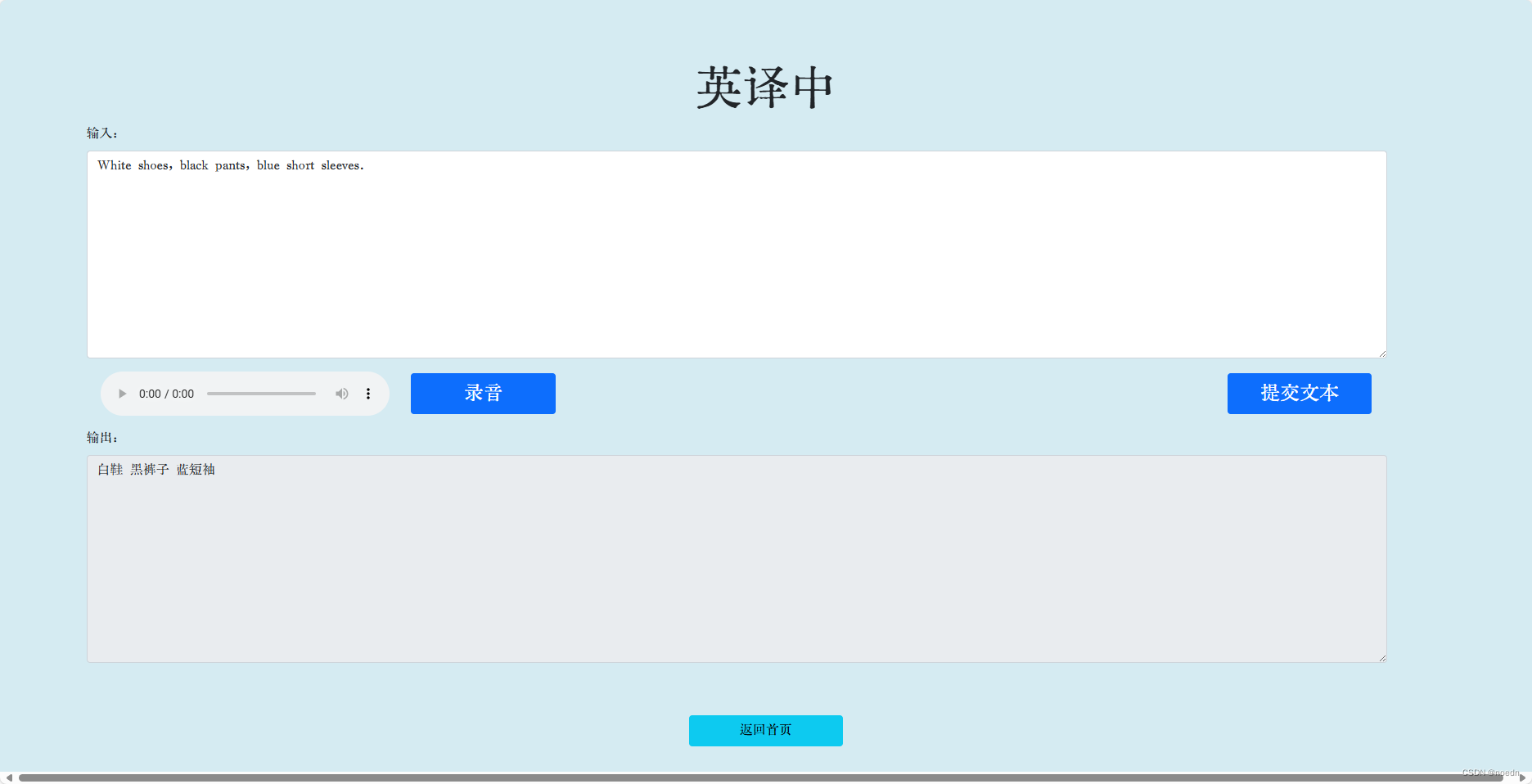
en2ch.html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>英译中</title>
<link rel="stylesheet" href="/static/css/bootstrap.css">
<style>
/*static 文件夹是默认用于存放静态文件的,比如 CSS、JavaScript、图片和字体文件等。
Flask 会自动为 static 文件夹下的所有文件提供静态文件的路由,使得这些文件可以被直接访问,
而不需要你为每个文件单独编写路由。*/
@font-face {
font-family: 'KingHwa'; /* 自定义字体名称 */
/*此处将字体文件加入到static文件夹当中,就省去了编写路由的工作,ttf文件对应路由格式truetype*/
src: url('../static/fonts/KingHwa_OldSong.ttf') format('truetype');/* 字体文件路径和格式 */
font-weight: normal;
font-style: normal;
}
body {
background-color: rgba(173, 216, 230, 0.5); /*设置页面背景颜色*/
font-family: "KingHwa", sans-serif; /*设置字体*/
}
.center-image {
/*position: fixed;*/
display: block;
margin-top: 4%;
margin-left: 40%;
margin-right: 40%;
border-radius: 4%; /* 设置圆角大小 */
width: 20%; /* 你可以根据需要调整宽度 */
}
.center-bnt {
/*position: fixed;*/
display: block;
margin-left: 45%;
margin-right: 45%;
width: 10%; /* 你可以根据需要调整宽度 */
}
.rounded-font {
display: block;
margin-top: 4%;
border-radius: 2%; /* 设置圆角大小 */
font-size: 360%; /* 设置字体大小 */
text-align: center; /* 将文本居中 */
}
#backToTop {
position: fixed;
bottom: 20px;
right: 30px;
z-index: 99;
border: none;
outline: 1px solid black;/*设置轮廓*/
background-color: rgba(0, 0, 230, 0.5);
color: white;
cursor: pointer;
padding: 4px 5px;
border-radius: 2px;/*设置圆角*/
}
.default-img {
/*position: fixed;*/
display: block;
{#margin-top: 10%;#}
{#margin-top: 5%;#}
margin-left: 30%;
margin-right: 30%;
width: 20%; /* 你可以根据需要调整宽度 */
border-radius: 2%;/*设置圆角*/
}
.back-home {
position: fixed;
bottom: 15px; /* 初始时,将元素移出视口 */
right: 100px;
/* 其他样式 */
}
.bottom_left {
position: fixed;
bottom: 15px; /* 初始时,将元素移出视口 */
left: 100px;
/* 其他样式 */
}
</style>
</head>
<h1 class="rounded-font">英译中</h1>
<body>
<form action="/en2ch" method="post" enctype = "multipart/form-data">
<div class="row" style="margin-left:5%;">
<div class="mb-3">
<label for="inputQuestion" class="form-label">输入:</label>
<textarea class="form-control"
id="inputQuestion"
rows="10" style="width: 90%;"
name="inputTxt">{{ data.input }}</textarea>
</div>
<div class="mb-3">
<audio controls class="audio-player"
style="width: 20%; margin-left: 1%; vertical-align: middle;"></audio>
<button type="button"
style="font-size: 150%; width:10%; margin-left: 1%;"
class="btn btn-primary record-btn">录音</button>
<button type="submit"
class="btn btn-primary"
style="font-size: 150%; width: 10%; margin-left: 46%;">提交文本</button>
</div>
<div class="mb-3">
<label for="outputQuestion" class="form-label">输出:</label>
<textarea class="form-control"
id="outputQuestion"
rows="10" style="width: 90%;"
readonly>{{ data.output }}</textarea>
</div>
</div>
</form>
<br/>
<br/>
<button onclick="goToLink()"
class="btn btn-primary btn-info center-bnt">返回首页</button>
<script>
function goToLink() {
window.location.href = "{{ url_for('home') }}"
}
</script>
<script src="../static/js/record.js"></script>
</body>
</html>
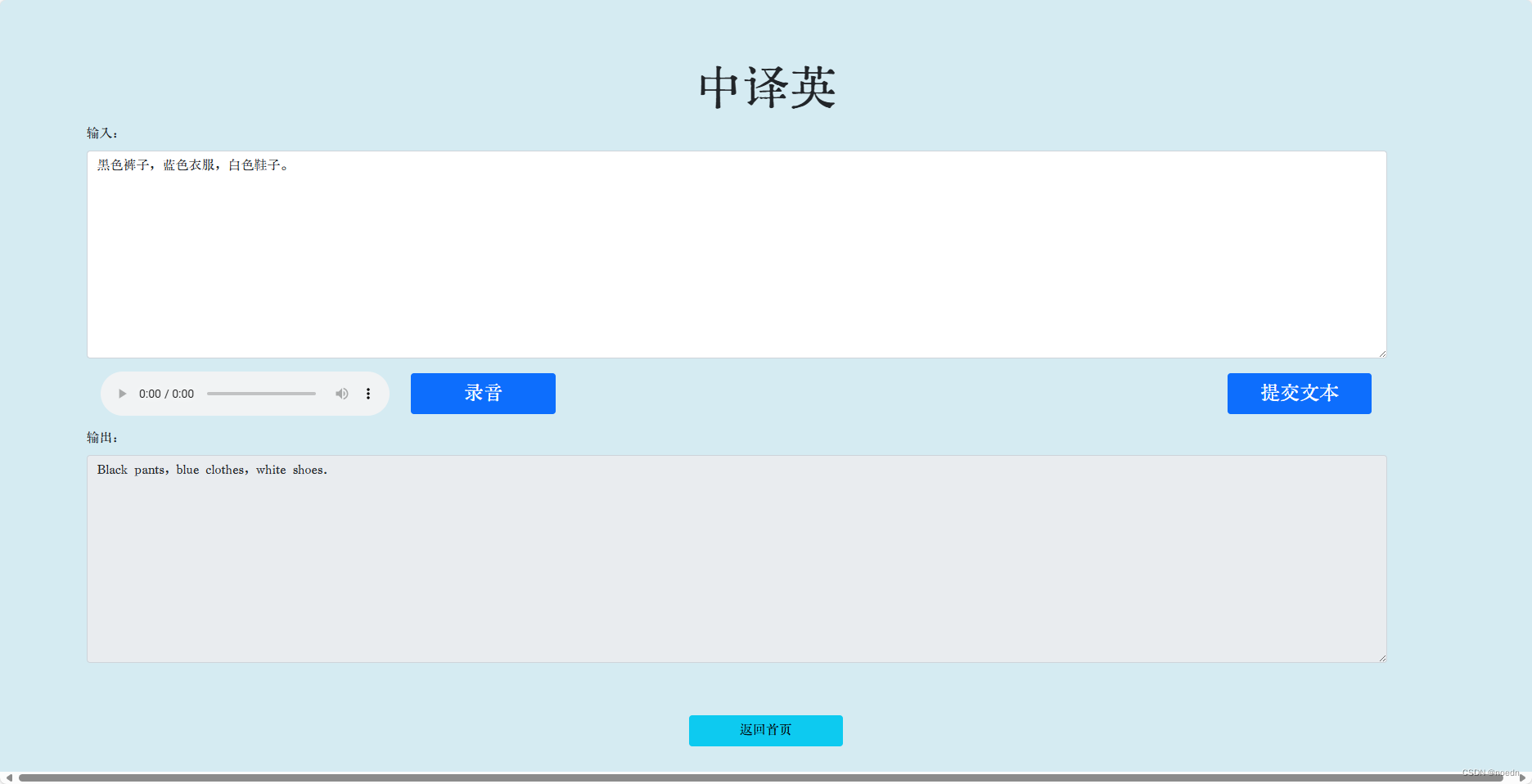
ch2en.html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>中译英</title>
<link rel="stylesheet" href="/static/css/bootstrap.css">
<style>
/*static 文件夹是默认用于存放静态文件的,比如 CSS、JavaScript、图片和字体文件等。
Flask 会自动为 static 文件夹下的所有文件提供静态文件的路由,使得这些文件可以被直接访问,
而不需要你为每个文件单独编写路由。*/
@font-face {
font-family: 'KingHwa'; /* 自定义字体名称 */
/*此处将字体文件加入到static文件夹当中,就省去了编写路由的工作,ttf文件对应路由格式truetype*/
src: url('../static/fonts/KingHwa_OldSong.ttf') format('truetype');/* 字体文件路径和格式 */
font-weight: normal;
font-style: normal;
}
body {
background-color: rgba(173, 216, 230, 0.5); /*设置页面背景颜色*/
font-family: "KingHwa", sans-serif; /*设置字体*/
}
.center-image {
/*position: fixed;*/
display: block;
margin-top: 4%;
margin-left: 40%;
margin-right: 40%;
border-radius: 4%; /* 设置圆角大小 */
width: 20%; /* 你可以根据需要调整宽度 */
}
.center-bnt {
/*position: fixed;*/
display: block;
margin-left: 45%;
margin-right: 45%;
width: 10%; /* 你可以根据需要调整宽度 */
}
.rounded-font {
display: block;
margin-top: 4%;
border-radius: 2%; /* 设置圆角大小 */
font-size: 360%; /* 设置字体大小 */
text-align: center; /* 将文本居中 */
}
#backToTop {
position: fixed;
bottom: 20px;
right: 30px;
z-index: 99;
border: none;
outline: 1px solid black;/*设置轮廓*/
background-color: rgba(0, 0, 230, 0.5);
color: white;
cursor: pointer;
padding: 4px 5px;
border-radius: 2px;/*设置圆角*/
}
.default-img {
/*position: fixed;*/
display: block;
{#margin-top: 10%;#}
{#margin-top: 5%;#}
margin-left: 30%;
margin-right: 30%;
width: 20%; /* 你可以根据需要调整宽度 */
border-radius: 2%;/*设置圆角*/
}
.back-home {
position: fixed;
bottom: 15px; /* 初始时,将元素移出视口 */
right: 100px;
/* 其他样式 */
}
.bottom_left {
position: fixed;
bottom: 15px; /* 初始时,将元素移出视口 */
left: 100px;
/* 其他样式 */
}
</style>
</head>
<h1 class="rounded-font">中译英</h1>
<body>
<form action="/ch2en" method="post" enctype = "multipart/form-data">
<div class="row" style="margin-left:5%;">
<div class="mb-3">
<label for="inputQuestion" class="form-label">输入:</label>
<textarea class="form-control"
id="inputQuestion"
rows="10" style="width: 90%;"
name="inputTxt">{{ data.input }}</textarea>
</div>
<div class="mb-3">
<audio controls class="audio-player"
style="width: 20%; margin-left: 1%; vertical-align: middle;"></audio>
<button type="button"
style="font-size: 150%; width:10%; margin-left: 1%;"
class="btn btn-primary record-btn">录音</button>
<button type="submit"
class="btn btn-primary"
style="font-size: 150%; width: 10%; margin-left: 46%;">提交文本</button>
</div>
<div class="mb-3">
<label for="outputQuestion" class="form-label">输出:</label>
<textarea class="form-control"
id="outputQuestion"
rows="10" style="width: 90%;"
readonly>{{ data.output }}</textarea>
</div>
</div>
</form>
<br/>
<br/>
<button onclick="goToLink()"
class="btn btn-primary btn-info center-bnt">返回首页</button>
<script>
function goToLink() {
window.location.href = "{{ url_for('home') }}"
}
</script>
<script src="../static/js/record.js"></script>
</body>
</html>
app.py
import os
from flask import Flask, redirect, render_template, request, send_file, session, url_for
from voi_2_text import *
from translate_ch5en import *
from my_util import Logger
loger = Logger()
app = Flask(__name__)
app.secret_key = 'RyVzs9ObLV5wsTDHN0h6X1VP1jmi6UgYNGWZXPgNwKI='
UPLOAD_FOLDER = os.path.join(os.path.join(os.getcwd(), 'src', 'upload-audio'))
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
init_voice_recognize_models() # 初始化中英语音识别模型
init_text_translate_models() # 初始化中英文翻译模型
@app.route('/src/<path:path>')#网页的所有文件都是来自服务器
def send_image(path):
return send_file(path, mimetype='image/jpeg')
@app.route('/')
def hello_world(): # put application's code here
session.clear()
loger.debug('Hello World!')
return redirect('/home')
@app.route('/home', methods=['GET', 'POST'])
def home():
if request.method == 'POST':
session.clear()
if request.form.get('choice') == 'ch2en':
loger.info('choice is chinese translate to english')
return redirect('/ch2en')
elif request.form.get('choice') == 'en2ch':
loger.info('choice is english translate to chinese')
return redirect('/en2ch')
else:
loger.info('unsupported choice')
return redirect('/home')
return render_template('home.html')
@app.route('/upload-url', methods=['POST']) # 访问的路径
def upload_url(): # put application's code here# '
if request.method == "POST":
if request.files.get("audioFile"): # !!!!!!!!!!!注意保存的录音文件还不是wav格式的,应该是哪里出错了20240526-2221
audio_file = request.files["audioFile"]
if audio_file is not None:
loger.info(f"get voice ok, file length {audio_file.content_length}")
loger.info(f"get file name {audio_file.filename}")
# 设置保存文件的路径
file_path = os.path.join(app.config['UPLOAD_FOLDER'], audio_file.filename)
# 保存文件
audio_file.save(file_path)
loger.info(f"save file path {file_path}")
loger.info(f"save file {audio_file.filename} length: {os.path.getsize(file_path)} bytes")
if session.get('previous_route', 'unknown') == "ch2en":
result = convert_ch_voi2text(file_path)
loger.info(f"recognized [ch2en] result: {result[0]}")
session['input'] = result[0]
elif session.get('previous_route', 'unknown') == "en2ch":
result = convert_en_voi2text(file_path)
loger.info(f"recognized [en2ch] result: {result[0]}")
session['input'] = result[0]
else:
loger.warning(f"unsupported previous route: {session.get('previous_route', 'unknown')}")
else:
loger.error("empty")
loger.debug(f"previous route is {session.get('previous_route', 'unknown')}")
return redirect(url_for(session.get('previous_route', 'unknown')))
@app.route('/ch2en', methods=['GET', 'POST'])
def ch2en():
loger.info(f'now in chinese translate to english')
data = {'input': session.get('input', '你好'), 'output': 'hello'}
if request.method == 'POST':
session.clear()
question = request.form.get("inputTxt")
loger.info(f"get input text {question}")
translate = translate_ch2en(question)
data = {'input': question, 'output': translate}
session['previous_route'] = 'ch2en'
return render_template('ch2en.html', data=data)
@app.route('/en2ch', methods=['GET', 'POST'])
def en2ch():
loger.info(f'now in english translate to chinese')
data = {'input': session.get('input', 'hello'), 'output': '你好'}
if request.method == 'POST':
session.clear()
question = request.form.get("inputTxt")
loger.info(f"get input text {question}")
translate = translate_en2ch(question)
data = {'input': question, 'output': translate}
session['previous_route'] = 'en2ch'
return render_template('en2ch.html', data=data)
if __name__ == '__main__':
app.run(debug=False)
my_util.py
#进度条
import os
import sys
import time
import shutil
import logging
import time
from datetime import datetime
def print_progress_bar(iteration, total, prefix='', suffix='', decimals=1, length=100, fill='█', print_end="\r"):
"""
调用在Python终端中打印自定义进度条的函数
iteration - 当前迭代(Int)
total - 总迭代(Int)
prefix - 前缀字符串(Str)
suffix - 后缀字符串(Str)
decimals - 正数的小数位数(Int)
length - 进度条的长度(Int)
fill - 进度条填充字符(Str)
print_end - 行尾字符(Str)
"""
percent = ("{0:." + str(decimals) + "f}").format(100 * (iteration / float(total)))
filled_length = int(length * iteration // total)
bar = fill * filled_length + '-' * (length - filled_length)
print(f'\r{prefix} |{bar}| {percent}% {suffix}', end=print_end)
# 打印新行,完成进度条
if iteration == total:
print()
class Logger(object):
"""
终端打印不同颜色的日志
"""
ch = logging.StreamHandler() # 创建日志处理器对象,在__init__外创建,是类当中的静态属性,不是__init__中的实例属性
# #创建静态的日志处理器可以减少内存消耗
# # 创建 FileHandler 实例,指定日志文件路径
# ch = logging.FileHandler(filename='app1.log')
def __init__(self):
self.logger = logging.getLogger() # 创建日志记录对象
self.logger.setLevel(logging.INFO) # 设置日志等级info,其他低于此等级的不打印
def debug(self, message):
self.fontColor('\033[0;37m%s\033[0m')
self.logger.debug(message)
def info(self, message):
self.fontColor('\033[0;32m%s\033[0m')
self.logger.info(message)
def warning(self, message):
self.fontColor('\033[0;33m%s\033[0m')
self.logger.warning(message)
def error(self, message):
self.fontColor('\033[0;31m%s\033[0m')
self.logger.error(message)
def fontColor(self, color):
formatter = logging.Formatter(color % '%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 控制日志输出颜色
self.ch.setFormatter(formatter)
self.logger.addHandler(self.ch) # 向日志记录对象中加入日志处理器对象
def delete_files(folder_path, max_files):
"""
监控指定文件夹中的文件数量,并在超过max_files时删除最旧的文件。
"""
print("进入删除图片文件夹"+folder_path)
print("需要删除文件数量")
print(max_files)
if True:
# 获取文件夹中的文件列表
files = os.listdir(folder_path)
file_count = len(files)
print(f"当前文件夹 {folder_path} 中的文件数量: {file_count}")
# 如果文件数量超过max_files,则删除最旧的文件
if file_count > max_files:
# 获取文件夹中所有文件的完整路径,并带上修改时间
file_paths_with_mtime = [(os.path.join(folder_path, f), os.path.getmtime(os.path.join(folder_path, f))) for
f in files]
# 按修改时间排序
sorted_files = sorted(file_paths_with_mtime, key=lambda x: x[1])
# 删除最旧的文件,直到文件数量在阈值以下
for file_path, mtime in sorted_files[:file_count - max_files]:
try:
os.remove(file_path)
print(f"已删除文件: {file_path}")
except OSError as e:
print(f"删除文件时出错: {e.strerror}")
def copy_file(src, dst):
shutil.copy2(src, dst) # copy2会尝试保留文件的元数据
def end_sentence(text, max_length):
'''
保证在max_length长度前以句号或点号结束文本
:param text: 文本
:param max_length: 最大长度
:return:
'''
# 如果文本长度已经超过最大长度,则直接截断
if len(text) > max_length:
text = text[:max_length]
# print("结果长度 {}".format(len(text)))
# 查找句号的位置(en)
period_index = max(text.rfind('.'), text.rfind(','),
text.rfind(':'), text.rfind(';'),
text.rfind('!'), text.rfind('?')) # 从后往前找,找到最后一个句号
# 如果找到了句号且它在最大长度内
if period_index != -1 and (period_index + 1 < max_length or
max_length == -1):
# 如果需要替换,则替换句号
text = text[:period_index] + '.'
# 查找句号的位置(cn)
period_index = max(text.rfind('。'), text.rfind(','),
text.rfind(':'), text.rfind(';'),
text.rfind('!'), text.rfind('?')) # 从后往前找,找到最后一个句号
# 如果找到了句号且它在最大长度内
if period_index != -1 and (period_index + 1 < max_length or
max_length == -1):
# 如果需要替换,则替换句号
text = text[:period_index] + '。'
return text
import base64
def encode_base64(input_string):
"""
对字符串进行Base64编码
"""
encoded_bytes = base64.b64encode(input_string.encode('utf-8'))
encoded_string = encoded_bytes.decode('utf-8')
return encoded_string
def decode_base64(input_string):
"""
对Base64编码的字符串进行解码
"""
decoded_bytes = base64.b64decode(input_string.encode('utf-8'))
decoded_string = decoded_bytes.decode('utf-8')
return decoded_string
translate_ch5en.py
# 项目模型来自hugging face镜像网站,HF Mirror
# 中译文模型:https://hf-mirror.com/Helsinki-NLP/opus-mt-zh-en/tree/main
# 英译中模型:https://hf-mirror.com/Helsinki-NLP/opus-mt-en-zh/tree/main
import os
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from transformers import pipeline
from my_util import Logger
loger = Logger()
def init_text_translate_models():
try:
# 加载中译英模型
model_cn2en_path = os.path.join(os.getcwd(), 'models', 'ch-en')
# 创建tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_cn2en_path)
# 创建模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_cn2en_path)
# 创建pipeline
global pipeline_ch2en
pipeline_ch2en = pipeline("translation", model=model, tokenizer=tokenizer)
# 加载英译中模型
model_en2cn_path = os.path.join(os.getcwd(), 'models', 'en-ch')
# 创建tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_en2cn_path)
# 创建模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_en2cn_path)
# 创建pipeline
global pipeline_en2ch
pipeline_en2ch = pipeline("translation", model=model, tokenizer=tokenizer)
except Exception as e:
# 捕获所有异常,并打印错误信息
loger.error(f"An error occurred: {e}")
finally:
loger.info(f"load text translate models success")
return
def translate_ch2en(sentence):
english_res = "unknown"
try:
result = pipeline_ch2en(sentence)
english_res = result[0]['translation_text']
except Exception as e:
# 捕获所有异常,并打印错误信息
loger.error(f"An error occurred: {e}")
finally:
loger.info(f"translate {sentence} to {english_res}")
return english_res
def translate_en2ch(sentence):
chinese_res = "未知"
try:
result = pipeline_en2ch(sentence)
chinese_res = result[0]['translation_text']
except Exception as e:
# 捕获所有异常,并打印错误信息
loger.error(f"An error occurred: {e}")
finally:
loger.info(f"translate {sentence} to {chinese_res}")
return chinese_res
# if __name__ == "__main__":
# init_translate_model()
# print("initializing translation models final")
# chinese = """
# 六岁时,我家在荷兰的莱斯韦克,房子的前面有一片荒地,
# 我称其为“那地方”,一个神秘的所在,那里深深的草木如今只到我的腰际,
# 当年却像是一片丛林,即便现在我还记得:“那地方”危机四伏,
# 洒满了我的恐惧和幻想。
# """
# result = pipeline_ch2en(chinese)
# english = result[0]['translation_text']
# print(english)
#
# result = pipeline_en2ch(english)
# print(result[0]['translation_text'])
voi_2_text.py
import os
import torch
import shlex
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import torchaudio
import subprocess
from my_util import Logger
loger = Logger()
# 模型镜像
# https://hf-mirror.com/jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn
CH_MODEL_ID = os.path.join(os.getcwd(), 'models', 'ch-voi-text')
# 模型镜像
# https://hf-mirror.com/jonatasgrosman/wav2vec2-large-xlsr-53-english/tree/main
EN_MODEL_ID = os.path.join(os.getcwd(), 'models', 'en-voi-text')
def convert_webm_to_wav(input_file, output_file):
"""
使用ffmpeg将WebM文件转换为WAV文件。
参数:
input_file (str): 输入的WebM文件名。
output_file (str): 输出的WAV文件名。
"""
loger.debug(f"input file {input_file}")
loger.debug(f"output file {output_file}")
try:
if os.path.exists(output_file):
os.remove(output_file)
loger.debug(f"file {output_file} remove success")
else:
loger.warning(f"file {output_file} not exist")
except PermissionError:
loger.error(f"cant remove file {output_file}, access denied")
except Exception as e:
loger.error(f"remove file {output_file} meet error: {e}")
try:
# FFmpeg命令行参数
# cmd = [
# 'ffmpeg',
# '-i', input_file, # 输入文件
# '-ar', '16000', # 输出音频采样率为16000Hz
# output_file # 输出文件名
# ]
input_file = input_file.replace('\\', '\\\\')
output_file = output_file.replace('\\', '\\\\')
cli_cmd = f'ffmpeg -i {input_file} -ar 16000 {output_file}'
cmd = shlex.split(cli_cmd)
loger.debug(f"shlex.split {cmd}")
# 执行FFmpeg命令并等待其完成
result = subprocess.run(cmd)
loger.debug(f"subprocess result {result}")
loger.debug(f"Successfully converted {input_file} to {output_file}")
except subprocess.CalledProcessError as e:
loger.error(f"Error occurred: {e}")
finally:
return
def init_voice_recognize_models():
try:
# 加载中文语音识别模型
global process_ch2en
global model_ch2en
process_ch2en = Wav2Vec2Processor.from_pretrained(CH_MODEL_ID)
model_ch2en = Wav2Vec2ForCTC.from_pretrained(CH_MODEL_ID)
# 加载英语语音识别模型
global process_en2ch
global model_en2ch
process_en2ch = Wav2Vec2Processor.from_pretrained(EN_MODEL_ID)
model_en2ch = Wav2Vec2ForCTC.from_pretrained(EN_MODEL_ID)
except Exception as e:
# 捕获所有异常,并打印错误信息
loger.error(f"An error occurred: {e}")
finally:
loger.info(f"load voice recognize models success")
return
def convert_ch_voi2text(webm_voi):
audio_path = os.path.join(os.path.dirname(webm_voi), "result.wav")
convert_webm_to_wav(webm_voi, audio_path)
# pip install pysoundfile 除了安装torchaudio,还需要安装pysoundfile
waveform, sample_rate = torchaudio.load(audio_path)
loger.debug(f"audio file {audio_path} waveform is {waveform}")
loger.debug(f"audio file {audio_path} sample rate is {sample_rate}")
# 模型期望的采样率是16000Hz,而你的音频是44100Hz,则需要进行重采样
if sample_rate != 16000: # 这个模型的采样率是16000Hz,20240536-2229
resampler = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=16000)
waveform = resampler(waveform)
sample_rate = 16000
# 使用特征提取器处理音频数据
input_values = process_ch2en(waveform, sampling_rate=sample_rate, return_tensors="pt", padding=True).input_values
# 获取预测结果(logits)
with torch.no_grad():
logits = model_ch2en(input_values.squeeze(0)).logits
# print(logits)
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = process_ch2en.batch_decode(predicted_ids)
loger.info(predicted_sentences)
return predicted_sentences
def convert_en_voi2text(webm_voi):
audio_path = os.path.join(os.path.dirname(webm_voi), "result.wav")
convert_webm_to_wav(webm_voi, audio_path)
# pip install pysoundfile 除了安装torchaudio,还需要安装pysoundfile
waveform, sample_rate = torchaudio.load(audio_path)
loger.debug(f"audio file {audio_path} waveform is {waveform}")
loger.debug(f"audio file {audio_path} sample rate is {sample_rate}")
# 模型期望的采样率是16000Hz,而你的音频是44100Hz,则需要进行重采样
if sample_rate != 16000: # 这个模型的采样率是16000Hz,20240536-2229
resampler = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=16000)
waveform = resampler(waveform)
sample_rate = 16000
# 使用特征提取器处理音频数据
input_values = process_en2ch(waveform, sampling_rate=sample_rate, return_tensors="pt", padding=True).input_values
# 获取预测结果(logits)
with torch.no_grad():
logits = model_en2ch(input_values.squeeze(0)).logits
# print(logits)
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = process_en2ch.batch_decode(predicted_ids)
loger.info(predicted_sentences)
return predicted_sentences
整体实现效果
page1
page2
page3
录音中
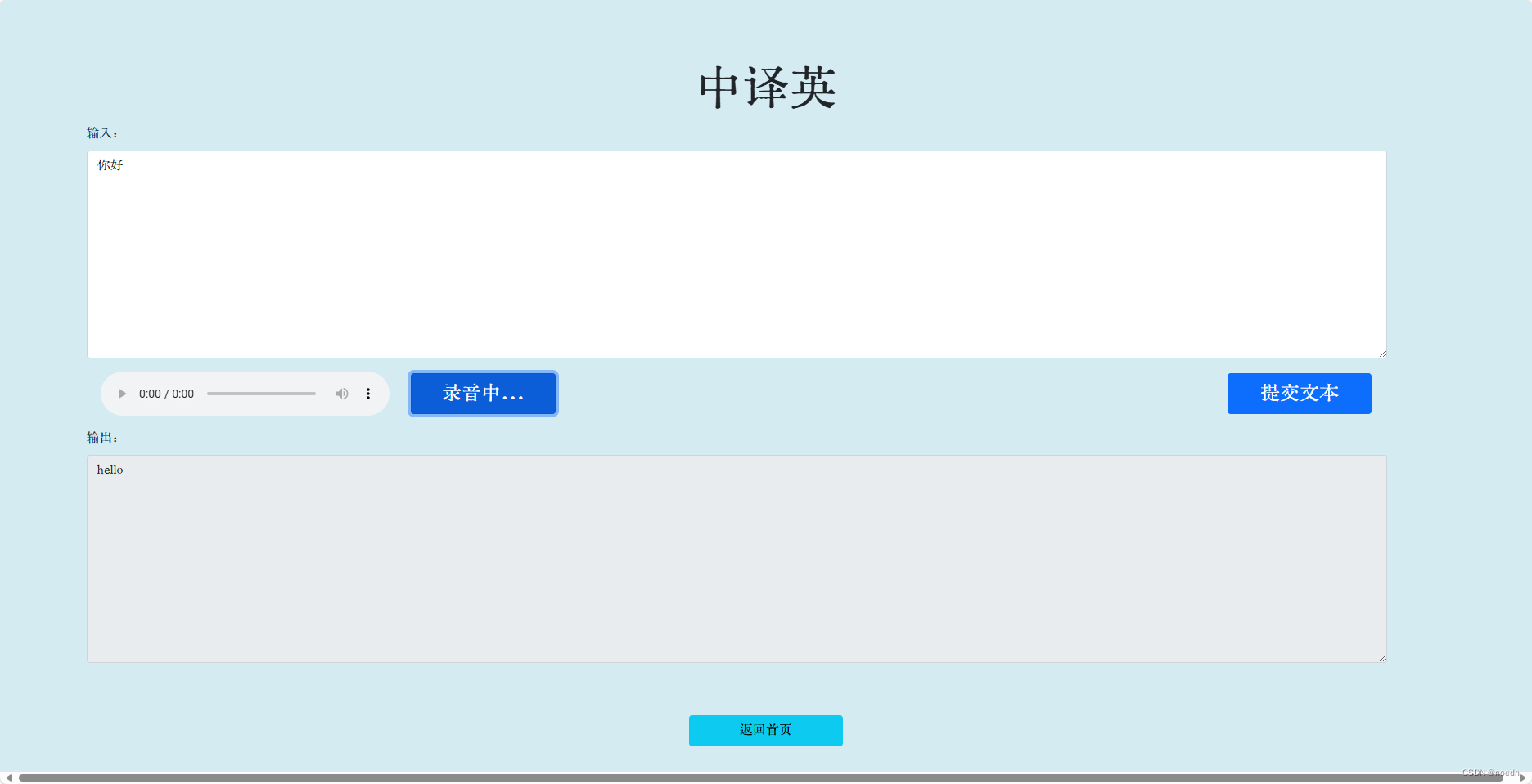
录音结束



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









