







1.确保已安装mitmproxy
如果没有安装,可以参考https://blog.csdn.net/liujingliuxingjiang/article/details/121633927?spm=1001.2014.3001.5501
2.手机设置
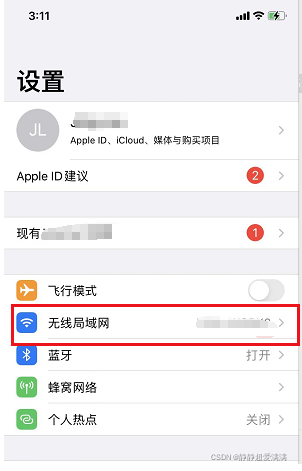
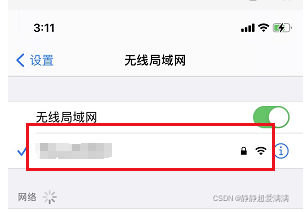
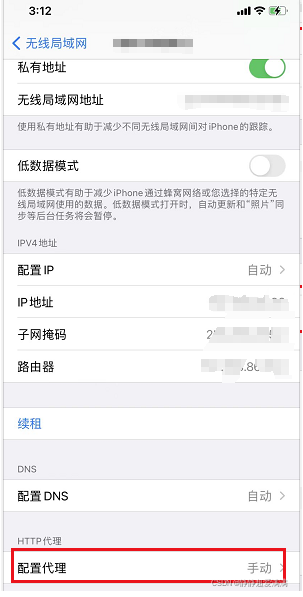
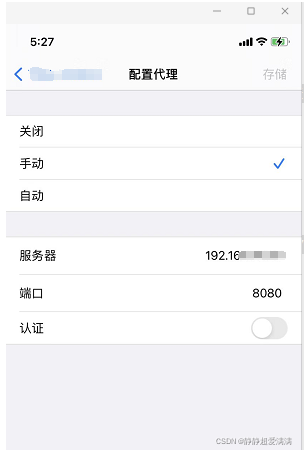
2.1 配置代理
2.2 Safri上下载证书
我用的是iphone,我在其他浏览器输入mitm.it,下载后不能识别成描述文件,只有在自带的Safri上下载才好用。
下载的时候选择apple版本,下载好后安装上。
安装好后检查证书是否打开
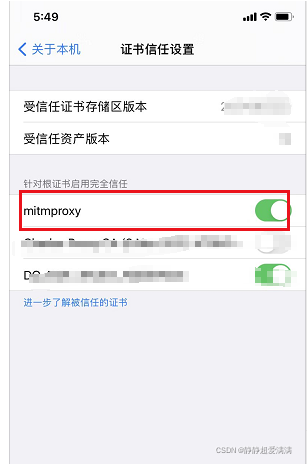
3.爬虫微信读书的今日书单
3.1 运行mitmweb
命令行输入mitmweb,如果要自己设置端口,就用mitmweb -p 端口号

3.2 手机上打开微信读书
点书单,进入“今日书单”页面,如下第一个页面,然后选择第一个“半佛推荐”,进入第二个页面。这时候mitmweb已经抓了一堆数据包了。
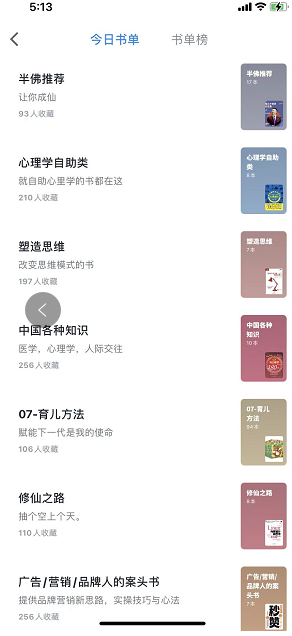
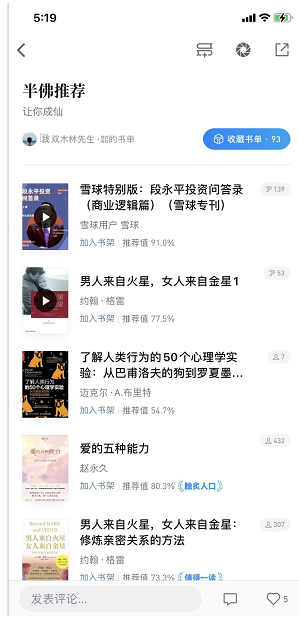
3.3 分析数据包
3.3.1 第一个页面分析
找到这个数据包和第一个页面显示的内容一样。
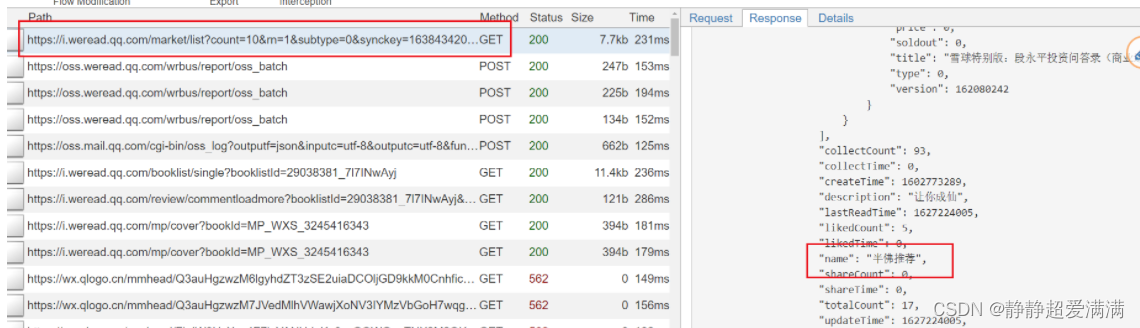
tips:抓好包之后,可以直接在搜索栏里搜索关键的url部分,就可以筛选出需要的数据包了。

从上面可以得到基本的信息:
请求的url:https://i.weread.qq.com/market/list?count=10&rn=1&subtype=0&synckey=1638434203&type=44
请求方式:get
3.3.2 第二个页面
找到这个数据包和第二个页面显示的内容一样。
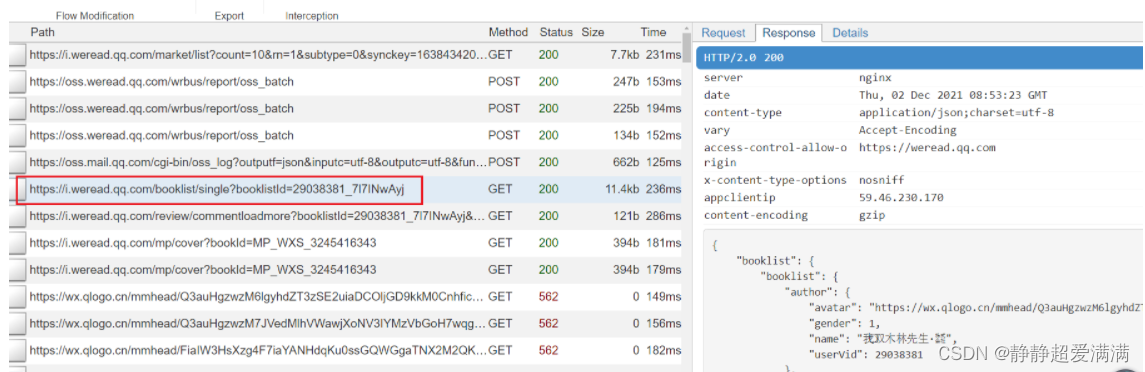
返回第一个页面,另外选一个类型点进去,找到了2次的数据包,他们的url如下
url:https://i.weread.qq.com/booklist/single?booklistId=29038381_7l7INwAyj
url:https://i.weread.qq.com/booklist/single?booklistId=1637484_709GTPGzp
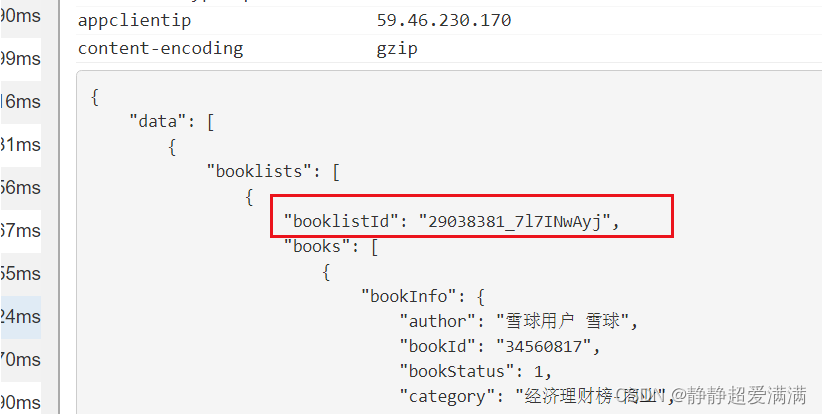
分析url,发现等号前面的部分是固定的,后面的数字和字母正好是上一个页面的booklistId的值。这样只需要在第一个页面上获取booklistId的值,就可以拼接出新的url,使用get请求方式获取第二个页面的内容。
3.4 代码编写
3.4.1 请求头
请求头很重要,如果用默认的请求头,会被识别出来是程序访问而不是真正的用户在访问。还有上面的内容是需要登录才能看见的,所以我们需要带上cookie里面的一些信息。
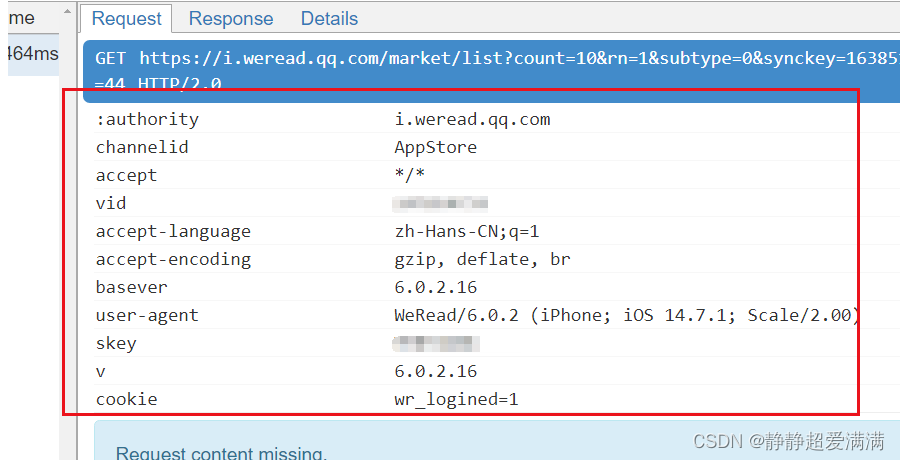
这里重要的是user-agent和一些登录信息相关的值。注意user-agent只能用手机的,用浏览器的不行。登录有时候过期了要重新登录,获取最新登录的信息。
headers = {
'user-agent': 'WeRead/6.0.2 (iPhone; iOS 14.7.1; Scale/2.00)',
'vid': '1234567',
'basever': '6.0.2.16',
'skey': 'YHB91ONh',
'v': '6.0.2.16'
}
3.4.2 获取第一个页面的booklistId
因为请求后返回的是json格式,我们使用json.loads转换成字典,然后就可以一层层获取到需要的值了。
获取到booklistId之后,拼接成新的url,然后再继续发送get请求。
def get_booklistId():
url = 'https://i.weread.qq.com/market/list?type=44'
resp = requests.get(url, headers=headers)
text = json.loads(resp.text)
booklist = text["data"][0]["booklists"]
for b in booklist:
booklistId = b["booklistId"]
books_url = 'https://i.weread.qq.com/booklist/single?booklistId=' + booklistId
get_bookname(books_url)
3.4.3 获取第二个页面的书信息
这里我就简单获取一下书名和作者名,然后打印出来
def get_bookname(url):
resp = requests.get(url, headers=headers)
text = json.loads(resp.text)
booklist = text['booklist']['booklist']['books']
for b in booklist:
book_name = b['bookInfo']['title']
author = b['bookInfo']['author']
print('book_name',book_name)
print('author', author)
3.4.4 完整代码
import requests
import json
headers = {
'user-agent': 'WeRead/6.0.2 (iPhone; iOS 14.7.1; Scale/2.00)',
'vid': '1234567',
'basever': '6.0.2.16',
'skey': 'YHB91ONh',
'v': '6.0.2.16'
}
def get_booklistId():
url = 'https://i.weread.qq.com/market/list?type=44'
resp = requests.get(url, headers=headers)
text = json.loads(resp.text)
booklist = text["data"][0]["booklists"]
for b in booklist:
booklistId = b["booklistId"]
books_url = 'https://i.weread.qq.com/booklist/single?booklistId=' + booklistId
get_bookname(books_url)
def get_bookname(url):
resp = requests.get(url, headers=headers)
text = json.loads(resp.text)
booklist = text['booklist']['booklist']['books']
for b in booklist:
book_name = b['bookInfo']['title']
author = b['bookInfo']['author']
print('book_name',book_name)
print('author', author)
if __name__ == '__main__':
get_booklistId()
3.5 结果显示


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









