







生成树
生成树(Spanning Tree)是一个连通图的生成树是图的极小连通子图,它包含图中的所有顶点,并且只含尽可能少的边。这意味着对于生成树来说,若砍去它的一条边,则会使生成树变成非连通图;若给它增加一条边,则会形成图中的一条回路。
最小生成树
最小生成树(Minimum Spanning Tree,简称 MST)是一个图的生成树中,边的权重之和最小的那棵生成树。
对于一个带权连通无向图G=(V,E),生成树不同,每棵树的权(即树中所有边上的权值之和)也可能不同。设X为G的所有生成树的集合,若T为X中边的权值之和最小的那棵生成树,则T称为G的最小生成树(Minimum-Spanning-Tree(MST),在一个加权连通图中,可能存在多个不同的生成树,但是其中只有一个最小生成树。最小生成树通常用于解决网络设计、通信网络等问题。
不难看出,最小生成树具有如下性质:
1)最小生成树不是唯一的,即最小生成树的树形不唯一,X中可能有多个最小生成树。当图G中的各边权值互不相等时,G的最小生成树是唯一的;若无向连通图G的边数比顶点数少1,即G本身是一棵树时,则G的最小生成树就是它本身。
2)最小生成树的边的权值之和总是唯一的,虽然最小生成树不唯一,但其对应的边的权值之和总是唯一的,而且是最小的。
3)最小生成树的边数为顶点数减1
构造最小生成树有多种算法,但大多数算法都利用了最小生成树的下列性质:假设G=(V,E)是一个带权连通无向图,U是顶点集V的一个非空子集。若(u,v)是一条具有最小叔值的边,其中u∈U, v∈V- U,则必存在一棵包含边(u,V)的最小生成树,基于该性质的最小生成树算法主要有Prim算法和Kruskal算法,它们都基于贪心算法的策略。
常用的最小生成树算法
Prim算法:Prim算法是一种贪心算法,从一个顶点开始,每次选择权重最小的边来扩展最小生成树,直到所有顶点都加入到最小生成树中为止。
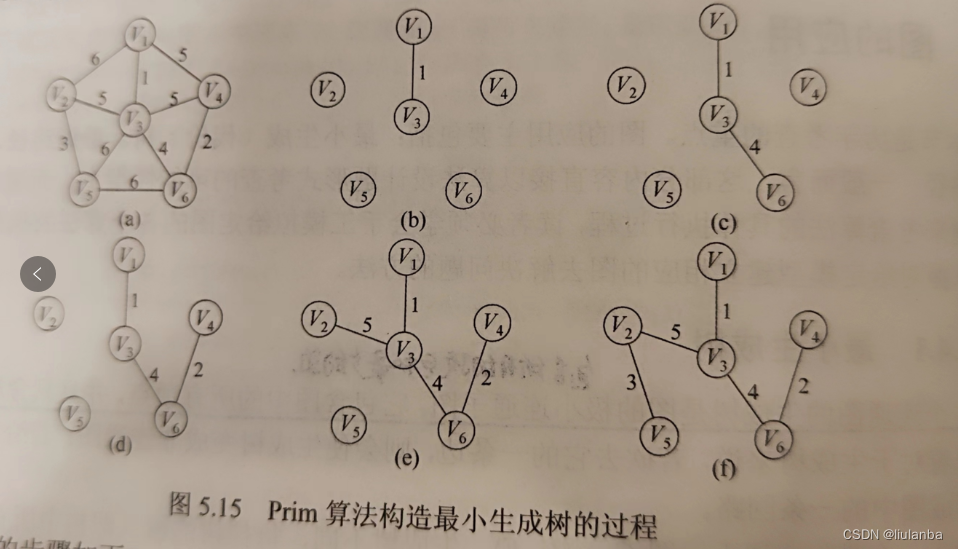
1.初始化一个空的最小生成树集合和一个空的候选边集合。
2.从任意一个顶点开始,将该顶点加入到最小生成树集合中。
3.将与该顶点相连的所有边加入到候选边集合中。
4.从候选边集合中选择权重最小的边,将其加入到最小生成树集合中。
5.将新加入的顶点以及与之相连的边从候选边集合中移除。
6.重复步骤4和步骤5,直到最小生成树集合中包含所有的顶点。
import heapq
class Graph:
def __init__(self, vertices):
self.vertices = vertices
self.adjacency_list = {v: [] for v in vertices}
def add_edge(self, u, v, weight):
self.adjacency_list[u].append((v, weight))
self.adjacency_list[v].append((u, weight))
def prim(self, start_vertex):
min_span_tree = []
visited = set()
candidates = [(0, start_vertex)] # 候选边集合,使用最小堆实现
while candidates:
weight, vertex = heapq.heappop(candidates)
if vertex not in visited:
visited.add(vertex)
min_span_tree.append((weight, vertex))
for neighbor, neighbor_weight in self.adjacency_list[vertex]:
if neighbor not in visited:
heapq.heappush(candidates, (neighbor_weight, neighbor))
return min_span_tree
# 测试
vertices = ['A', 'B', 'C', 'D', 'E', 'F']
graph = Graph(vertices)
graph.add_edge('A', 'B', 4)
graph.add_edge('A', 'C', 3)
graph.add_edge('B', 'C', 2)
graph.add_edge('B', 'D', 5)
graph.add_edge('C', 'D', 1)
graph.add_edge('C', 'E', 6)
graph.add_edge('D', 'E', 7)
graph.add_edge('D', 'F', 2)
graph.add_edge('E', 'F', 3)
start_vertex = 'A'
min_span_tree = graph.prim(start_vertex)
print("Prim算法最小生成树:", min_span_tree)
实现解析:
Graph 类表示图,使用邻接表来存储图的结构。
add_edge 方法用于添加边到图中。 prim方法是Prim算法的实现,使用了最小堆来存储候选边集合,并使用 heapq 模块提供的堆操作。
在每一轮循环中,从候选边集合中选择权重最小的边,并将其加入到最小生成树集合中,然后将新加入的顶点以及与之相连的边加入到候选边集合中。
最终返回最小生成树集合。
Kruskal算法:Kruskal算法是一种基于并查集的贪心算法,它首先将所有边按权重从小到大排序,然后依次考虑每条边,如果当前边连接的两个顶点不在同一个连通分量中,则将这条边加入最小生成树中,并将这两个顶点合并到同一个连通分量中,直到最小生成树的边数达到n-1为止。
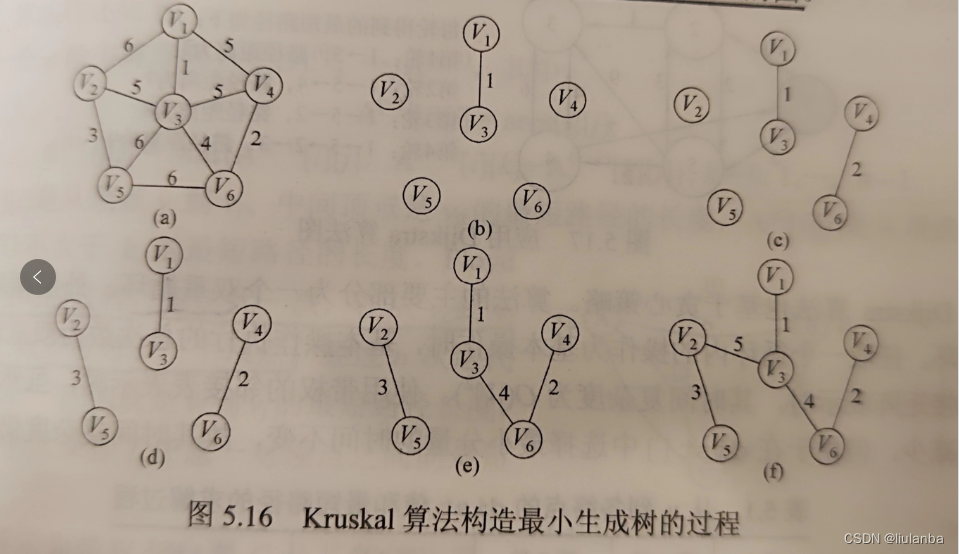
1.初始化:将图中的所有边按照权值从小到大进行排序。
2.创建并查集:使用并查集(Union Find)数据结构来管理顶点的连通性。
3.遍历边:按照排序后的顺序依次遍历所有边。
4.如果当前边的两个顶点不在同一个连通分量中,则选择该边,并将这两个顶点合并到同一个连通分量中。否则,舍弃该边。
5.重复步骤3,直到选出了n-1条边为止,此时构成了最小生成树。
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.rank = [0] * n
def find(self, x):
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return False
if self.rank[root_x] < self.rank[root_y]:
self.parent[root_x] = root_y
elif self.rank[root_x] > self.rank[root_y]:
self.parent[root_y] = root_x
else:
self.parent[root_y] = root_x
self.rank[root_x] += 1
return True
def kruskal(graph):
n = len(graph)
edges = []
# 将图中的边按照权值排序
for i in range(n):
for j in range(i + 1, n):
if graph[i][j] != float('inf'):
edges.append((i, j, graph[i][j]))
edges.sort(key=lambda x: x[2])
# 创建并查集
uf = UnionFind(n)
# 初始化最小生成树的边集合
result = []
for edge in edges:
u, v, weight = edge
if uf.union(u, v):
result.append(edge)
if len(result) == n - 1:
break
return result
# 测试
graph = [
[0, 2, 4, 0, 0, 0],
[2, 0, 1, 4, 2, 0],
[4, 1, 0, 0, 3, 0],
[0, 4, 0, 0, 3, 2],
[0, 2, 3, 3, 0, 2],
[0, 0, 0, 2, 2, 0]
]
minimum_spanning_tree = kruskal(graph)
print("Minimum Spanning Tree:")
for edge in minimum_spanning_tree:
print(edge)
这段代码首先定义了一个UnionFind类来实现并查集,其中包括find方法用于查找根节点和union方法用于合并两个连通分量。然后,定义了kruskal函数来实现Kruskal算法,其中对图中的边按照权值进行排序,并依次遍历每条边,根据并查集的操作来构建最小生成树。最后,打印出构建出的最小生成树的边集合。
最小生成树算法的选择:
如果图的边数量比较少,那么Kruskal算法通常更加简洁高效。
如果图的顶点数量比较少,那么Prim算法可能更容易实现和理解。
如果图是稠密图(边数量接近于完全图),那么Prim算法的时间复杂度可能更低,因为Prim算法在每一步都只需要考虑与当前最小生成树相邻的边。














 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









