









1、什么是动态规划?
“你怎么给一个4岁的孩子讲清楚动态规划?”
“首先你在纸上写下这样一串加法运算:1+1+1+1+1+1+1”
“他们的和是多少?”
数完之后回答“等于7”
“继续在算式的左边加一个1”
“现在等于几?”
很快就能回答出来“等于8”
“为什么第二次能够回答这么快呢?”
“因为你只加了一个1”
“所以这一次你不用再一个一个的数一遍了,你已经知道前面的答案是7。”
“那么什么是动态规划呢?没错,它就是把一个大的问题拆解成一堆小问题,解析时记住前面小问题的答案,为后面的解答节省时间,这就是动态规划”
相信很多人之前看到这个概念就已经打退堂鼓了,现在你是否对它有了一个新的认识?
2、动态规划的核心思想
按照上面的解释,动态规划是把一个大问题拆解成一堆小问题,这个本身没啥问题,但是这个不是动态规划的核心思想,或者说,一个”大问题“之所以能用”动态规划“解决,并不是因为它能拆解成—堆小问题。
事实上任何大问题都能拆解成小问题,而它是否属于动态规划范畴,取决于用动态规划解决的这些”小问题“会不会被重复调用。
思想①:问题的答案依赖于问题的规模,也就是问题的所有答案构成了一个数列。
举个例子:
1个人有2条腿,2个人有4条腿,… n 个人有多少条腿?答案是2n条腿。这里的2n,是问题的答案,n则是问题的规模,显然问题的答案是依赖于问题的规模的。答案是因变量,问题规模是自变量。因此,问题在所有规模下的答案可以构成一个数列(f(1),f(2),…,f(n)),比如这个“数腿”的例子就构成了间隔为2的等差数列(0,2,4,… . ,2n)。
思想②:大规模问题的答案可以由小规模问题的答案递推得到,也就是f(n)的值可以由
{f(i)i<n}中的个别求得。还是刚刚“数腿”的例子,显然f(n)可以基于f(n -1)求得: f(n)= f(n -1)+2。
3、什么时候适合使用动态规划呢?
能用动态规划解决,不代表什么时候都适合用。比如刚刚的“数腿”例子,你可以写成f(n) = 2n的显式表达式形式,那么杀鸡就不必用牛刀了。但是,在许多场景,f(n)的显式式子是不易得到的,大多数情况下甚至无法得到,动态规划的魅力就出来了。
4、应用动态规划——将动态规划拆分成三个子目标
当要应用动态规划来解决问题时,归根结底就是想办法完成以下三个关键目标:
-
建立状态转移方程
这一步是最难的,大部分人都被卡在这里。这一步没太多的规律可说,只需抓住一个思维:当做已经知道f(1)~ f(n -1)的值,然后想办法利用它们求得f(n)。在“数腿”的例子中,状态转移方程即为f(n) = f(n —1)+f(1),即f(n) = f(n —1)+2。
-
缓存并复用以往结果
这一步不难,但是很重要。如果没有合适地处理,很有可能就是指数和线性时间复杂度的区别。假设在“数腿”的例子中,我们不能用显式方程,只能用状态转移方程来解。如果现在
f(100)未知,但是刚刚求解过一次f(99)。如果不将其缓存起来,那么求f(100)时,我们就必须花100次加法运算重新获取。但是如果刚刚缓存过,只需复用这个子结果,那么将只需一次加法运算即可。 -
按顺序从小往大算
这里的“小”和“大”对应的是问题的规模,在这里也就是我们要从f(0). f(1) ,…到f(n)依次顺序计算。这一点在“数腿”的例子来看,似乎显而易见,因为状态方程基本限制了你只能从小到大一步步递推出最终的结果(假设我们仍然不能用显式方程)。然而当问题复杂起来的时候,你又可能乱了套,所以必须记住这也是目标之一。
5、案例解析
动态规划实际上就是要我们在推导出状态转移万程后,根据状态转移方程用计算机暴力求解出答案。请切记一点:想用显式表达式?在动态规划中是不存在的!
因为要暴力计算,所以上面说的目标有两个是涉及到代码层面的:
- 缓存中间结果:也就是搞个数组之类的存储空间记录中间结果。
- 按顺序从小往大计算:也就是搞个for循环依次计算。
俗话说的好:talk is cheap, show me the code. 下面我们将用3个例子来给大家详细分析一下动态规划,案例的难度是从简单到困难递升的,保证合你们的胃口。
案例一(简单):
斐波那契数列:0,1,1,2,3,5,8,13,21,34,55,89,144,233......
它遵循这样的规律:当前值为前两个值的和。
那么第n个值为多少?
我们很快就能根据上面的解释,分析出这个案例的状态转移方程:f(n) = f(n-1)+ f(n-2)。接下来我们用两种代码方式来完成它,让大家清澈的认识一下动态规划的魅力。
-
递归
public int fib(n){ if(n<2) return n; else return fib(n-1) + fib(n-2) }代码简单易懂,然而这代码却极其低效。先不说这种递归的方式造成栈空间的极大浪费,就仅仅是该算法的时间复杂度已经是O(2^n)了。“指数级别时间复杂度”的算法和“不能用”没啥区别!
为什么是指数时间复杂度?上面的代码通过展示求解f(4)的过程如下:随着递归的深入,计算任务不断地翻倍!
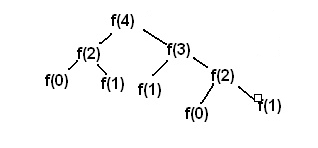
-
动态规划
public class Fib { //用于缓存以往结果,以便复用(目标2) private static List<Integer> list = new ArrayList(); public static int fib(int n){ //按顺序从小打大算(目标3) for (int i = 0; i < n; i++) { if (i<2) list.add(i); else //使用状态转移方程(目标1) list.add(list.get(list.size()-1)+list.get(list.size()-2)); } return list.get(list.size()-1); } public static void main(String[] args) { System.out.println("用户输入"); System.out.println(fib(new Scanner(System.in).nextInt())); } } //输出 用户输入 7 输出 8使用动态规划的方式,我们只需要进行一下圈起来的地方进行计算即可:
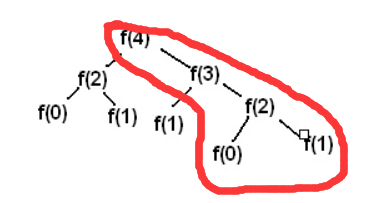
时间复杂度瞬间降为O(n)。
案例二(中等):
一个机器人位于一个m x n网格的左上角 (起始点在下图中标记为“Start”)。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
问总共有多少条不同的路径?
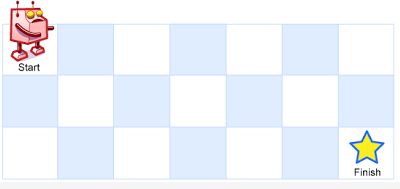
输入:m = 3, n = 7(上图)
输出:28
先自己思考 1 min…再看答案。
解这题,如前所述,我们需要完成三个子目标:
-
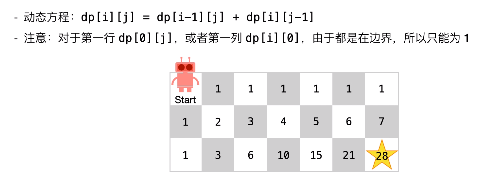
建立状态转移方程。该题就难在这里,这一步搞不定基本上GG了。实际上,如上图所示,第i行第j列的格子的路径数,是等于它左边格子和上面格子的路径数之和:
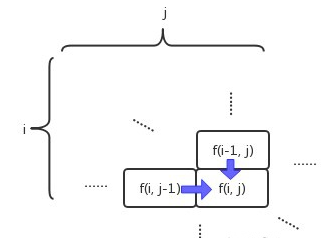
-
缓存并复用以往结果。与之前说的一维数列不同,这里的中间结果可以构成一个二维数列(如上图所示),所以需要用二维的数组或者列表来存储。
-
按顺序从小往大算。这次有两个维度,所以需两个循环,分别逐行和逐列让问题从小规模到大规模计算。
//m是行数,n是列数 public int uniquePaths(int m, int n) { int[][] f = new int[m][n]; for (int i = 0; i < m; ++i) { f[i][0] = 1;//左边界 } for (int j = 0; j < n; ++j) { f[0][j] = 1;//上边界 } for (int i = 1; i < m; ++i) { for (int j = 1; j < n; ++j) { f[i][j] = f[i - 1][j] + f[i][j - 1]; } } return f[m - 1][n - 1]; }时间复杂度:O(m n)。
空间复杂度:O(m n),即为存储所有状态需要的空间。注意到 f(i, j) 仅与第 i 行和第 i-1行的状态有关,因此我们可以使用滚动数组代替代码中的二维数组,使空间复杂度降低为 O(n)。
此外,由于我们交换行列的值并不会对答案产生影响,因此我们总可以通过交换m和n使得m ≤n,这样空间复杂度降低至 O(min(m, n))。
案例三(困难):
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
'.' 匹配任意单个字符
'*' 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s 的,而不是部分字符串。
示例 1:
输入:s = "aa" p = "a"
输出:false
解释:"a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:s = "aa" p = "a*"
输出:true
解释:因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3:
输入:s = "ab" p = ".*"
输出:true
解释:".*" 表示可匹配零个或多个('*')任意字符('.')。
示例 4:
输入:s = "aab" p = "c*a*b"
输出:true
解释:因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
示例 5:
输入:s = "mississippi" p = "mis*is*p*."
输出:false
提示:
0 <= s.length <= 20
0 <= p.length <= 30
s 可能为空,且只包含从 a-z 的小写字母。
p 可能为空,且只包含从 a-z 的小写字母,以及字符 . 和 *。
保证每次出现字符 * 时,前面都匹配到有效的字符。
看到这个题目的时候,人已经晕了,先花3分钟看懂题目…好了,我们一起来分析答案吧。
老样子,我们需要完成三个目标:
-
建立状态转移方程。这里的状态转移方程有些复杂,我折腾了一段时间才总结出来的,如果看不懂就跳过不用纠结,毕竟文章的重点不在此。
首先我们进行如下定义:
f(i,j) : pattern的第0~i个字符与string的第0~j个字符的匹配结果。结果只取True(匹配成功),或者False (匹配失败)。 P.i: pattern的第i个字符。 S.j : string的第j个字符。 m(i,j):单个字符P.i;和S.j的匹配结果。结果只取True(匹配成功),或者False (匹配失败)。那么参考下面的图片,可得下面的状态转移方程。具体地说有两种情况:
(1)如果P.i为星号外的任意字符,用“x”表示。这种情况显而易见, f(i,j)是基于f(i-1,j-1)的结果(可能成功或者失败的)继续配对。 (2).如果P.i为星号“*”。如下图右边,分三种子情况。①箭头1描述了 P.i-1 匹配成功了0次的情况,所以继承前面匹配的结果f(i-2,j);②箭头2描述了 P.i-1 成功匹配了1次的情况,所以继承这1次的结果f(i-1,j);③箭头3表示 P.i-1 成功匹配超过1次,所以基于左边的结果继续匹配f(i,j - 1)& m(i - 1,j)。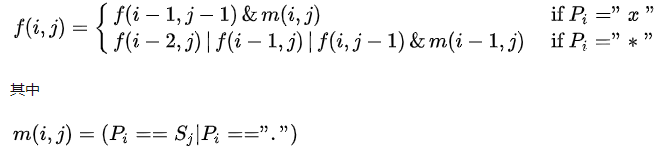
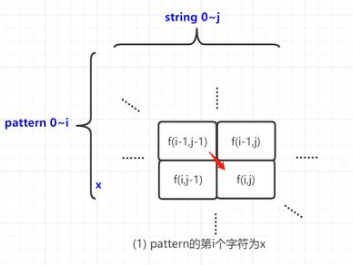
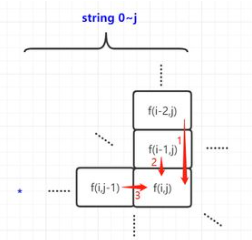
(2)pattern的第i个字符为"*"
- 缓存并复用以往结果。如下图仍然用二维数组,存的是布尔型。
- 按顺序从小往大算,参考代码。
代码实现如下,里面提到的哨兵是用于处理临界问题的,自己跑跑代码就懂了:
public boolean isMatch(String s, String p) { int m = s.length(); int n = p.length(); boolean[][] f = new boolean[m + 1][n + 1]; f[0][0] = true; for (int i = 0; i <= m; ++i) { for (int j = 1; j <= n; ++j) { if (p.charAt(j - 1) == '*') { f[i][j] = f[i][j - 2]; if (matches(s, p, i, j - 1)) { f[i][j] = f[i][j] || f[i - 1][j]; } } else { if (matches(s, p, i, j)) { f[i][j] = f[i - 1][j - 1]; } } } } return f[m][n]; } public boolean matches(String s, String p, int i, int j) { if (i == 0) { return false; } if (p.charAt(j - 1) == '.') { return true; } return s.charAt(i - 1) == p.charAt(j - 1); }时间复杂度:O(m n),其中m和n分别是字符串s和p的长度。我们需要计算出所有的状态,并且每个状态在进行转移时的时间复杂度为O(1)。
空间复杂度:O(m n),即为存储所有状态使用的空间。
6、动态规划问题类别
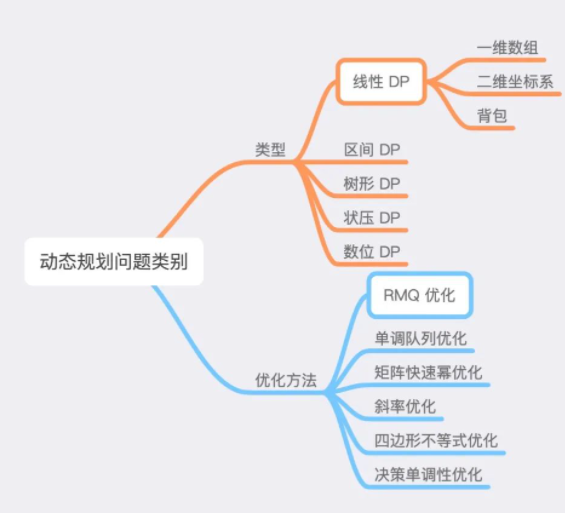
其中在DP类型部分,面试中最常考察的就是「线性DP」,而在优化方法部分,最常见的是「RMQ优化」,即使用线段树或其它数据结构查询区间最小值,来优化DP的转移过程,这个就暂时不解释了,难度过高。
7、总结
动态规划与其说是一个算法,不如说是一种方法论。该方法论主要致力于将合适的问题拆分成三个子目标——击破:
- 建立状态转移方程
- 缓存并复用以往结果
- 按顺序从小往大算
完成这三个目标,你将所向披靡。















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











