






你好,我是leo。在上一篇文章分库分表的原理和实战【二】,我用ShardingSphere-JDBC的标准分片策略,分别用哈希取模和范围分片两种分片路由算法实现了在虚拟业务场景下的分库分表功能。本篇文章仍然用这个虚拟业务场景,演示如何用HINT分片策略实现分库分表功能。
首先把上一篇文章用到的业务场景和需求再重复一下:某个业务领域会生成一个有业务含义的单号,格式为:ABC20240101-000001,ABC为业务领域的标识,20240101为年月日,000001为流水号。数据增长速度为每月500w,即每年6000w,按单号哈希取模,分4库,再按单号时间范围分表,每库每6个月一张表,每张表1000w数据,每年可以存储8000w数据。
HINT分片
HINT分片表示强制分片路由,对于分片字段的值并非由 SQL 而是其他外置条件决定的场景,可以通过外部条件直接指定分片路由结果。例如:用户登录后,按用户所属的租户分片,租户信息不一定在SQL中存在。又如:某类业务有独立的库,按业务类别分片,而业务类别信息不一定在SQL中存在。
ShardingSphere提供了两种使用HINT分片的方法,一种是在Java中用HintManager类手动编程实现,另一种是在SQL中增加特定的注释,用ShardingSphere可以识别和解析的SQL注释实现。
leo建议尽量用Java编程的方式使用HINT,对分片的路由规则可以统一管理,如果用HINT SQL,则需要在每个SQL中硬编码注释信息,比较繁琐。
使用步骤
Hint分片策略的基本使用步骤是:
- 首先在YAML中配置表的分片策略为hint,并配置自定义的分片路由算法名称和实现类
(把下面的配置加上数据源)
spring:
shardingsphere:
# 参数配置,显示 sql
props:
sql-show: true
datasource:
# 数据源别名
names: db0, db1, db2, db3
db0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/leotest?useSSL=true&useUnicode=true&characterEncoding=utf8
username: root
password:
db1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/leotest1?useSSL=true&useUnicode=true&characterEncoding=utf8
username: root
password:
db2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/leotest2?useSSL=true&useUnicode=true&characterEncoding=utf8
username: root
password:
db3:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/leotest3?useSSL=true&useUnicode=true&characterEncoding=utf8
username: root
password:
rules:
sharding:
tables:
apply:
# 数据节点
actual-data-nodes: db$->{0..3}.apply_$->{2023..2028}$->{["01","02"]}
# 数据库分片策略
database-strategy:
hint:
sharding-algorithm-name: custom-db-algorithm
# 表分片策略
table-strategy:
hint:
sharding-algorithm-name: custom-table-algorithm
apply_ext2:
actual-data-nodes: db$->{0..3}.apply_ext2_$->{2023..2028}$->{["01","02"]}
database-strategy:
hint:
sharding-algorithm-name: custom-db-algorithm
table-strategy:
hint:
sharding-algorithm-name: custom-table-algorithm
# 绑定表
bindingTables:
- apply,apply_ext2
#分片算法
sharding-algorithms:
#自定义分片算法db_alg
custom-db-algorithm:
type: CLASS_BASED
props:
strategy: HINT
#分片算法的实现类
algorithmClassName: com.example.leodemo.shard.DbHintShard
#自定义分片算法 table_alg
custom-table-algorithm:
type: CLASS_BASED
props:
strategy: HINT
algorithmClassName: com.example.leodemo.shard.TableHintShard
- 然后分别在com.example.leodemo.shard.DbHintShard和com.example.leodemo.shard.TableHintShard两个算法类中实现HintShardingAlgorithm接口的doSharding方法,根据传入的HINT分片参数自由实现路由算法。
接口定义:
public interface HintShardingAlgorithm<T extends Comparable<?>> extends ShardingAlgorithm {
Collection<String> doSharding(Collection<String> var1, HintShardingValue<T> var2);
}
第一个参数Collection<String>表示分库路由算法的数据源名称,或分表路由算法的物理表名;第二个参数HintShardingValue<T>表示HINT分片值。
分库HINT路由算法:
public class DbHintShard implements HintShardingAlgorithm<String> {
private Properties props;
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<String> hintShardingValue) {
HashSet<String> result = new HashSet<>(hintShardingValue.getValues().size());
for (String each : availableTargetNames) {
for (String value : hintShardingValue.getValues()) {
if (each.endsWith(value)) {
result.add(each);
}
}
}
return result;
}
@Override
public Properties getProps() {
return this.props;
}
@Override
public void init(Properties properties) {
this.props=properties;
}
}
分表HINT路由算法
public class TableHintShard implements HintShardingAlgorithm<String> {
private Properties props;
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<String> hintShardingValue) {
HashSet<String> result = new HashSet<>(hintShardingValue.getValues().size());
for (String each : availableTargetNames) {
for (String value : hintShardingValue.getValues()) {
if (each.endsWith(value)) {
result.add(each);
}
}
}
return result;
}
@Override
public Properties getProps() {
return this.props;
}
@Override
public void init(Properties properties) {
this.props=properties;
}
}
- 最后在执行SQL前用HintManager传入HINT分片值
HintManager hintManager = HintManager.getInstance();
try {
//逻辑表名为apply,HINT分库算法的分片值为3
hintManager.addDatabaseShardingValue("apply","3");
//逻辑表名为apply,HINT分表算法的分片值为202402
hintManager.addTableShardingValue("apply","202402");
//业务逻辑
val result=applyExt2EntityMapper.queryApplyExt();
}finally {
hintManager.close();
}
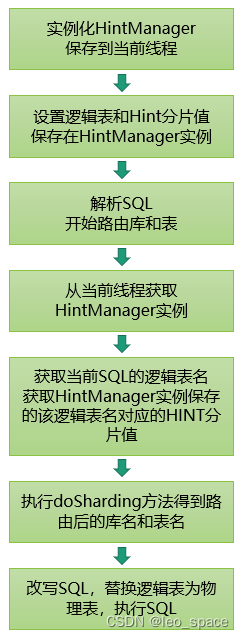
HintManager 中维护了一个本地线程变量HINT_MANAGER_HOLDER
private static final ThreadLocal<HintManager> HINT_MANAGER_HOLDER = new ThreadLocal();
HintManager.getInstance()在创建HintManager实例的同时,会把实例保存在当前线程的ThreadLocal对象中。
addDatabaseShardingValue和addTableShardingValue分别是添加逻辑表对应分库和分表的HINT分片值,在执行SQL前会从ThreadLocal获取HintManager实例,得到分库和分表的逻辑表名“apply”及对应的分片值“3”和“202402”,然后执行doSharding方法(执行2次,分库路由一次,分表路由一次),把分片值“3”和“202402”传入doSharding接口的第二个参数,再根据doSharding接口返回的库名后缀和表名后缀改写SQL,把逻辑表替换为物理表。
整体过程如下:
从上面的基本使用方法可以看出,HINT分片算法具有极高的自由度,分片路由所涉及到的信息几乎全部由我们自己提供:
- 对当前SQL中的哪个或哪些表做路由
addDatabaseShardingValue(“apply”,“3”)中的“apply”,和addTableShardingValue(“apply”,“202402”)中的“apply” - 按什么规则做路由
分库算法com.example.leodemo.shard.DbHintShard和分表算法com.example.leodemo.shard.TableHintShard - 路由规则中的参数是什么
addDatabaseShardingValue(“apply”,“3”)中的“3”,和addTableShardingValue(“apply”,“202402”)中的“202402”
为什么HINT分片算法要我们自己来指定逻辑表名呢?因为HINT分片算法本质上是在执行SQL前把逻辑表名转换为物理表名,再到数据库中执行SQL(同标准分片策略的思路一致),而ShardingSphere从SQL中提取出逻辑表之后,要检测这个逻辑表是否在hintManager中存在。如果存在,则执行路由方法,确定最终的物理表;如果不存在,则不执行路由方法,直接取YAML配置文件中该逻辑表对应的所有物理表。
HINT实战
下面来看看在实际项目中如何使用HINT分片算法。实际项目里,需要做HINT分片路由的SQL会很多,可以在mapper方法上加AOP拦截,把HintManager 相关的逻辑放到AOP中。如下:
@Aspect
@Component
public class MapperAspect {
@Around("execution(public * com.example.leodemo.mapper.*.*(..))")
public Object doCustomHint(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
HintManager hintManager = HintManager.getInstance();
try {
hintManager.addDatabaseShardingValue("逻辑表名","HINT分片值");
hintManager.addTableShardingValue("逻辑表名","HINT分片值");
return proceedingJoinPoint.proceed();
}finally {
hintManager.close();
}
}
}
上述的示例,HINT分片算法的逻辑表名有两种方式来处理:
- 注解添加静态值
在mapper方法上加一个自定义注解,注解的值指定为要查询的逻辑表。逻辑表名为SQL里要查询的表名。
public interface ApplyExt2EntityMapper {
@LogicTables(logicTableName = {"apply","apply_ext2"})
List<ApplyExt2Entity> queryApplyExt();
}
AOP方法则演变为:
@Aspect
@Component
public class MapperAspect {
@Around("execution(public * com.example.leodemo.mapper.*.*(..))")
public Object doCustomHint(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
HintManager hintManager = HintManager.getInstance();
try {
MethodSignature methodSignature = (MethodSignature)proceedingJoinPoint.getSignature();
LogicTables logicTables = methodSignature.getMethod().getAnnotation(LogicTables.class);
if(logicTables !=null){
for(String logicTableName: logicTables.logicTableName()){
hintManager.addDatabaseShardingValue(logicTableName,"HINT分片值");
hintManager.addTableShardingValue(logicTableName,"HINT分片值");
}
}
return proceedingJoinPoint.proceed();
}finally {
hintManager.close();
}
}
}
在注解上添加逻辑表的静态值,实质上相当于把逻辑表名硬编码后取出来传给HintManager,每个SQL都这么做,既很繁琐,又容易出错。只适合少量SQL需要HINT分片的情况。
- 从配置信息获取动态值
还有一种方法是从ShardingSphere的配置信息里取逻辑表名,在每个SQL执行前都把所有的逻辑表名传入HintManager,即使SQL中只查个别几张表。全量的逻辑表名肯定包含了SQL中写的逻辑表名,而且HintManager中多余的逻辑表名在ShardingSphere解析SQL,执行SQL时不会有副作用。
那么,AOP方法则演变为:
@Aspect
@Component
public class MapperAspect {
@Autowired
ApplicationContext applicationContext;
@Around("execution(public * com.example.leodemo.mapper.*.*(..))")
public Object doCustomHint(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
HintManager hintManager = HintManager.getInstance();
try {
AlgorithmProvidedShardingRuleConfiguration ruleConfig= applicationContext.getBean(AlgorithmProvidedShardingRuleConfiguration.class);
ruleConfig.getTables().forEach(tableConfig-> {
hintManager.addDatabaseShardingValue(tableConfig.getLogicTable(),"HINT分片值");
hintManager.addTableShardingValue(tableConfig.getLogicTable(), "HINT分片值");
});
return proceedingJoinPoint.proceed();
}finally {
hintManager.close();
}
}
}
再来看HINT分片值的动态化问题。既然是HINT分片,那么HINT分片值是和业务逻辑相关联的,可以用以下方法获取数据:
- 从注解中取数
静态参数可以写在注解中。 - 从mapper方法的传参中取数
方法传参要根据业务实际情况做规范化处理,比如约定好简单参数的名字,自定义类是否继承公共基类等,方便AOP中统一处理。 - 从ThreadLocal中取数
在业务请求处理过程中,提前在合适的时间根据业务数据计算好本次SQL的HINT分片值,写入当前请求的ThreadLocal。然后在AOP切面中从ThreadLocal取HINT分片值。
具体用哪种方法,要结合实际业务逻辑来决定,此处就不做代码演示了。
HINT强制指定库
HintManager还有一种特殊的用法,强制指定路由到某个库。
基本用法是
HintManager hintManager = HintManager.getInstance();
try {
//指定目标库
hintManager.setDatabaseShardingValue("1");
//业务逻辑
val result=applyExt2EntityMapper.queryApplyExt();
}finally {
hintManager.close();
}
setDatabaseShardingValue方法只需要指定分库的HINT分片值,然后在执行SQL前会进入分库的doSharding路由方法,计算分库路由后的目标库。
但要注意的一点是:setDatabaseShardingValue方法没有逻辑表名的参数,如果SQL中包含有YAML里配置的逻辑表,那么会查逻辑表对应的所有物理表。
在实际项目里,可以自定义注解,并结合上面代码的AOP方法来使用。
自定义InDataSource注解
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface InDataSource {
String dbName() default "";
}
Mapper接口:
@InDataSource(dbName="0")
List<ApplyExt2Entity> queryApplyExt(@Param("applyNo") String applyNo);
AOP
@Aspect
@Component
public class MapperAspect {
@Autowired
ApplicationContext applicationContext;
@Around("execution(public * com.example.leodemo.mapper.*.*(..))")
public Object doCustomHint(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
HintManager hintManager = HintManager.getInstance();
try {
//强制指定一个分片库
InDataSource inDataSource=methodSignature.getMethod().getAnnotation(InDataSource.class);
if(inDataSource!=null){
hintManager.setDataSourceName(inDataSource.dbName());
return proceedingJoinPoint.proceed();
}
AlgorithmProvidedShardingRuleConfiguration ruleConfig= applicationContext.getBean(AlgorithmProvidedShardingRuleConfiguration.class);
ruleConfig.getTables().forEach(tableConfig-> {
hintManager.addDatabaseShardingValue(tableConfig.getLogicTable(),"HINT分片值");
hintManager.addTableShardingValue(tableConfig.getLogicTable(), "HINT分片值");
});
return proceedingJoinPoint.proceed();
}finally {
hintManager.close();
}
}
}















 1499
1499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









