







字符串匹配又叫模式匹配。也就是说给一个字符串p,其长度为m;给出一个正文字符串s,其长度为n,通常情况下n的长度要大于m,在正文中找到这个字符串p就是模式匹配问题
1、字符串匹配的简单算法(BF算法)
C代码:
两种实现方式:
1.通过设置标志变量flag
例如:
#include<stdio.h>
#include<string.h>
int search(const char *src, const char *patn, int slen, int plen);
void main()
{
char *src = "ababacbac";
char *patn = "ac";
int pos=0, slen=0, plen=0;
slen = strlen(src);
plen = strlen(patn);
pos = search(src,patn,slen,plen);
printf("%d",pos);
}
int search(const char *src, const char *patn, int slen, int plen)
{
int i = 0, flag = 0, j = 0, k = 0;
while((i<slen)&&(flag != 1))
{
k = i;
j = 0;
while((j<plen)&&(src[k]==patn[j]))
{
++k;
++j;
}
if(j==plen)
flag = 1;
else
++i;
}
if(flag == 1)
return i;
else
return -1;
}
//设置flag,当完全匹配的时候flag==1,跳出循环,此时i的值就是模式串在住串中的位置。
2.通过回溯的方法
int search(const char *src, const char *patn, int slen, int plen)
{
int i = 0, j = 0;
while((i<slen)&&(j<plen))
{
if(src[i]==patn[j])
{
++i;
++j;
}
else
{
i = i-j+1;
j = 0;
}
}
if(j==plen)
return i-plen;
else
return -1;
}
//当发现失配时将i回退,再重新比较。
//返回的函数值为-1,说明查找失败;否则说明查找成功,且返回的函数值为模式p的第一个字符在s中的位置
该算法的缺点是:当比较过程中发现不匹配时,模式p沿着正文s向后移动一个位置。使得先前已经比较过的正文字符还需要进行比较,增加了比较次数,而且会引起反复存取正文字符串的操作。
2、KMP算法
基本思想是:找到一种模式p沿主串s向后移动的规则,以便使得主串s中失去匹配的字符以前的字符不再参与比较,即只从当前失去匹配的字符开始与模式p中的字符继续一次进行比较,并且又不能错过模式发现的机会。
KMP算法的关键是:当模式串p[j]和主串s[i]失配时,求得在失配字符之前模式串中字符前缀和后缀相同的最大长度k(即求"T0~Tk-1"=="Tj-k~Tj-1"),这个长度就是下回用来与s[i]进行比较的模式串字符中的下标,即p[k],这样就避免了主串的回溯,减小了时间复杂度。
现在问题是这个k如何求(也就是说对于模式串中不同字符的失配,这个k是多少)?
这里出现了next数组,next数组就是用来记录k值的。我们用next[j]=k来方便解释其含义,即当p[j]失配时,下一次比较用p[k]来替换p[j],继续与主串进行比较。next数组的值可以由下式表示
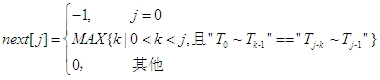
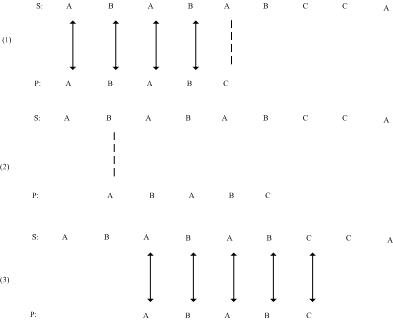
当j=0时,此时也就是说p[0]与主串失配,这个时候只能将主串向后移动一位
当j=1时,此时也就是说p[1]与主串失配,这个时候next[1]=0,主串不动,模式串右移也就是后移一位
当j>=2时,就要看k值了
至于为什么用p[k]来替换p[j],可以从下图看出来
S0,S1,S2,...,Si-j,Si-j+1...............,Si-1,Si, Si+1,....,Sn
T0,T1,.....Tj-k,........,Tj-1,Tj, ..........
T0, T1,..,Tk-1,Tk,..........
因为"T0~Tk-1"=="Tj-k~Tj-1",显然用Tk来与Si进行比较。
next数组可以用递推的方式求得
设next[j]=k,这表明模式串中存在下面的关系"T0~Tk-1"=="Tj-k~Tj-1",其中k为满足1<k<j的某个值,并且不可能存在k'>k满足上面的等式。此时的next[j+1]=?可能有两种情况:
(1)若Tk=Tj,则表明在模式串中有
"T0~Tk"=="Tj-k~Tj",所以
next[j+1]=k+1;
(2)若Tk!=Tj,此时我们的目的仍然是要求对于模式串"T0~Tj",使得该部分的前后缀相等的最大长度值。于是我们将模式串即当成主串,又当成模式串,也就是如下图所示:
主串 T0,T1,.....Tj-k,........,Tj-1,Tj, ..........
模式串 T0, T1,..,Tk-1,Tk,..........
当Tk!=Tj时,我们用Tnext[k]来代替Tk,如果Tnext[k]与Tj仍然不等,我们就让Tnext[next[k]]来代替Tnext[k]直到出现一个k'使得Tk'=Tj,此时next[j+1]=k'+1,所以写成递推的形式为:
next[j+1]=next[j]+1;
求next数组的C代码:
//plen是模式串的长度,
int *next_construction(const char *src, const char *patn, int plen, int *next)
{
int j=0, k=-1;
next[0] = -1;
while(j<plen-1) // j<plen-1的原因是在对next[j]赋值的时候先执行了++j
{
if(k==-1||patn[j]==patn[k]) //k==-1之后求得next[1]=0
{
++k;
++j;
if(patn[j]!=patn[k])
next[j]=k;
else
next[j]=next[k];
}
else
k=next[k];
}
return next;
}
求得next数组以后就可以写KMP算法了
int KMP_search(const char *src, const char *patn, int slen, int plen, int *next)
{
int i=0,j=0;
while((i<slen)&&(j<plen))
{
if(j==-1||src[i]==patn[j])
{
++i;
++j;
}
else
{
j=next[j];
}
}
if(j==plen)
return i-plen;
else
return -1;
}
//观察发现,KMP的代码与BF的代码很相似,只是在局部有细微差别
KMP算法的复杂度是O(strlen(S)+strlen(P))
BF算法的复杂度是O(strlen(S)*strlen(P))
KMP算法为什么是线性的需要用到有限自动机的理论,该理论还不是很清楚。需要继续学习















 9563
9563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









