







森林和二叉树的转化
孩子兄弟表示法:
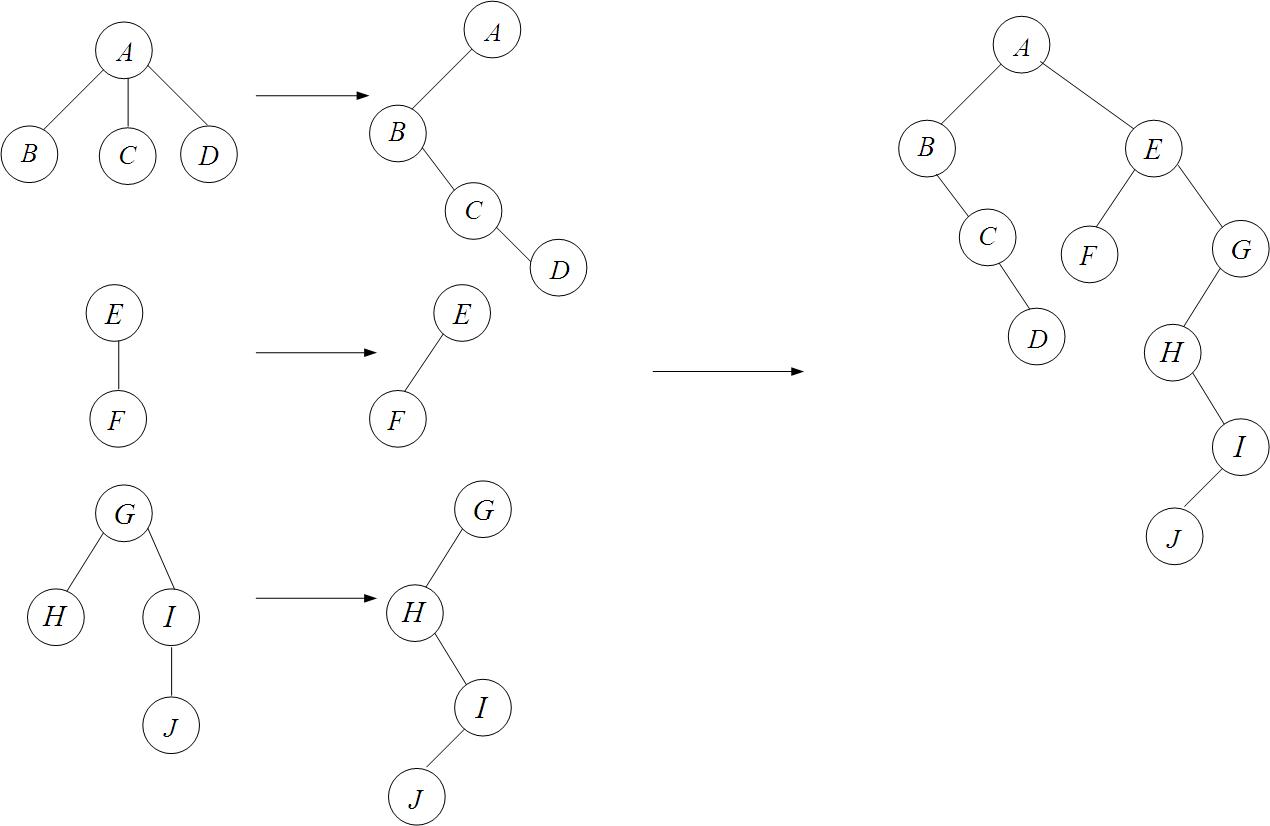
任何一棵和树对应的二叉树,其右子树必为空。森林中将第二棵树的兄弟,则可得到森林和二叉树的对应关系。
最优二叉树(赫夫曼树)
赫夫曼树:又称最优树,是一类带权路径长度最短的树。
树的路径长度:从树根到每一结点的路径长度(从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径,路径上的分支数目称作:路径长度)之和。
树的带权路径长度:树中所有叶子结点的带权路径长度(从该叶子结点到根之间的路径长度与结点上权的乘积)之和,通常记作:
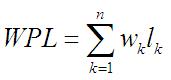
假设有n个权值{w1,w2,...,wn},构造一棵有n个叶子结点的二叉树,每个叶子结点带权为wi,则其中带权路径长度WPL最小的二叉树称做最优二叉树
赫夫曼算法:这篇文章中说的很详细链接
赫夫曼编码:也就是通过赫夫曼树产生的非定长前缀码(任何一个编码都不是另一个编码的前缀,这种编码叫前缀编码),其中每种字符在电文中出现的次数为wi,编码长度为Li,电文总长度为w1*L1+w2*L2+...+wn*Ln。
赫夫曼编码实现
赫夫曼树中没有度为1的结点(称为正则二叉树)则一棵有n个叶子结点的赫夫曼树共有2n-1个结点,因此可以存储在一个大小为2n-1的一维数组中。由于在构成赫夫曼树之后,为求编码需要从叶子结点出发走一条从叶子到根的路径(这里说的从叶子到根指的是在程序中进行赫夫曼编码时,是从parent域非零到parent域为零这个过程);而为译码需要从根出发走一条从根到叶子的路径。
赫夫曼编码的产生方式有两种,第一种是:从叶子到根逆向求每个字符的赫夫曼编码;第二种是:从根出发,遍历整棵赫夫曼树。不过不管是使用哪种方式来生成编码其赫夫曼树的存储方式都没有改变。
不过这里采用的方法与上面链接中所描述的方法略有不同。这里不对叶子结点按其权值进行排序,举个例子有8种字符,其概率分别是0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11。可以设权w={5,29,7,8,14,23,3,11}其编码过程如下图所示:
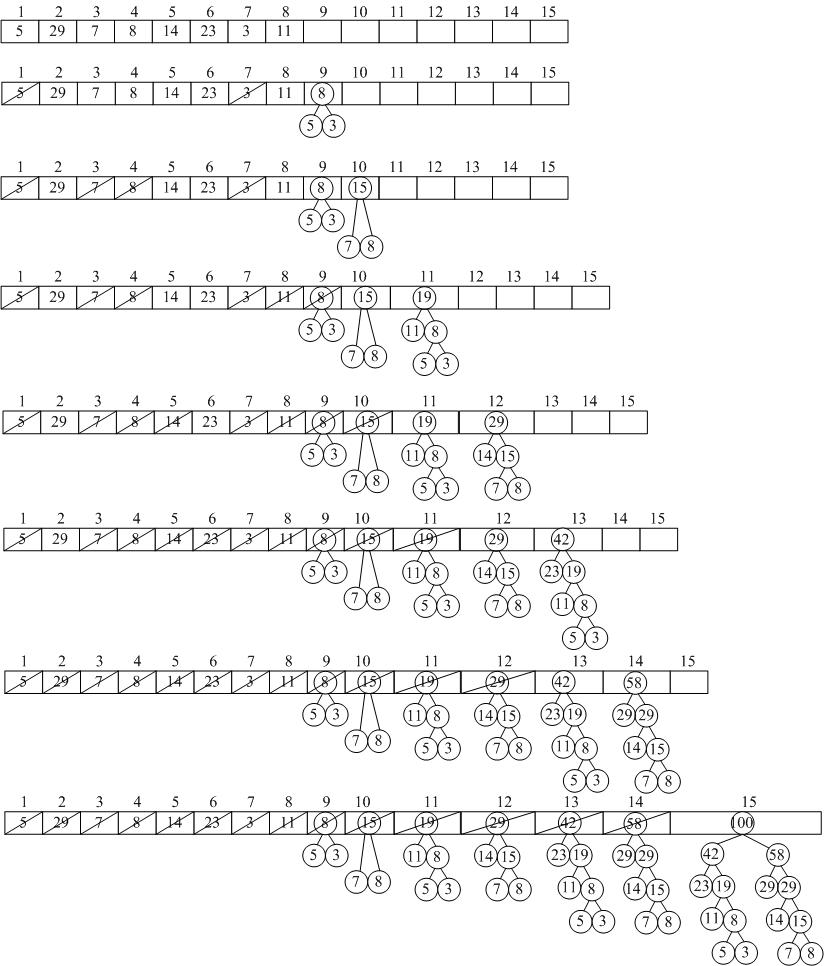
结点中的数字表示该结点的权值,至于哪个结点为左孩子,哪个结点为右孩子要看其在数组中的存储位置(即下标),下标小的作为左孩子,另外一个作为右孩子。
下面首先,给出程序中需要用到的结构体,定义的宏,函数声明
#define MAX 100;//假设所有字符的权值加起来是100
typedef struct
{
int weight;
int parent,lchild,rchild;
}HTNode,*HuffmanTree;
typedef char** HuffmanCode;
int min(HuffmanTree &HT,int i);
void select(HuffmanTree &HT,int i,int &s1,int &s2);
void HuffmanCoding(HuffmanTree &HT,HuffmanCode &HC,int *w,int n);
其次,赫夫曼编码的代码,及两个用到的子函数
int min(HuffmanTree &HT,int i)
{
int k = MAX;
int j,flag = 0;
for(j=1;j<=i;++j)
{
if(HT[j].weight
s2)
{
change = s1;
s1 = s2;
s2 = change;
}
}
void HuffmanCoding(HuffmanTree &HT,HuffmanCode &HC,int *w,int n)
{//HT赫夫曼树,HC存储字符指针的数组,因此HC的类型是指向字符指针的指针,w存储权值的数组,n符号个数
int m,i,c,f,s1,s2,start; //c,f用来在后面的编码中,表示孩子结点,父结点的下标
HTNode *p;
char *cd; //后面编码时需要用到的工作空间
if(n<=1) return; //想判断需要编码的字符个数
m = 2*n-1; //赫夫曼树中结点个数
HT = (HuffmanTree)malloc((m+1)*sizeof(HTNode));//分配m+1个连续空间,HT[0]不使用
if(NULL == HT)
{
printf("memory distribution error\n");
exit(-1);
}
for(i=1,p=HT+1;i<=n;++i,++p,++w) //对HT的前n+1个元素进行初始化
{
(*p).weight = *w;
(*p).parent = 0;
(*p).lchild = 0;
(*p).rchild = 0;
}
for(;i<=m;++i,++p) //对HT的剩余元素进行初始化,之所以不需要对i进行初值设定是因为上一个循环中最后i=n+1,
//p要自加,这个地方漏掉了
{
(*p).weight = 0;
(*p).parent = 0;
(*p).lchild = 0;
(*p).rchild = 0;
}
for(i=n+1;i<=m;++i) //这个地方是进行赫夫曼树的建树,此时初始的元素的下标是n+1
{
select(HT,i-1,s1,s2); //注意选择是从HT[1~i-1]中选
HT[s1].parent = i;
HT[s2].parent = i;
HT[i].lchild = s1;
HT[i].rchild = s2;
HT[i].weight = HT[s1].weight+HT[s2].weight;
}
HC = (HuffmanCode)malloc((n+1)*sizeof(char *)); //分配类型为char *类型的n+1个连续空间,因为HC[0]不使用
if(NULL == HC)
{
printf("memory distribution error\n");
exit(-1);
}
cd = (char*)malloc(n*sizeof(char)); //分配工作空间,用来存储与字符所对应的编码;对n个字符进行编码,编码长度
//最长为n-1,之所以分配n个空间是因为要在最后的空间中加入'\0'
cd[n-1] = '\0'; //cd是从cd[0~n-1]存储
for(i=1;i<=n;++i)
{
start = n-1;
for(c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent)
{
if(HT[f].lchild == c)
cd[--start] = '0';
else
cd[--start] = '1';
}
HC[i] = (char *)malloc((n-start)*sizeof(char));//start初值为n-1,存储i个0、1字符后,star = n-1-i,n-start = i+1,分配的
//空间比存储的字符个数多一个,原因是需要考虑'\0'
strcpy(HC[i],&cd[start]); //strcpy(str1,str2)将str2中的'\0'也复制到字符串str1中。
//另外如果str1=abcdefg,str2=hij;将str2复制到str1中会出现str1=hij\0efg
}
free(cd);
}
另外一种编码方式,是从根结点出发遍历整棵赫夫曼树
//另外一种方式,从根结点到叶子结点遍历赫夫曼树
c = m;
cdlen = 0;//前面要声明一下
for(i=1;i<=m;++i)
HT[i].weight = 0;//遍历赫夫曼树时用作结点状态标志
while(c)
{
if(HT[c].weight==0)
{//向左
HT[c].weight=1;
if(HT[c].lchild!=0)
{
c=HT[c].lchild;
cd[cdlen++]='0';
}
else
if(HT[c].rchild==0)
{//登记叶子结点的字符的编码
HC[c]=(char *)malloc((cdlen+1)*sizeof(char));
cd[cdlen]='\0';
strcpy(HC[c],cd);//复制编码(串)
}
}
else
{
if(HT[c].weight==1)
{//向右
HT[c].weight==2;
if(HT[c].rchild!=0)
{
c=HT[c].rchild;
cd[cdlen++]='1';
}
}
else
{//HT[c].weight==2,退回
HT[c].weight=0;//当前结点的权值为0,
c=HT[c].parent;//c指向当前结点的父节点
--cdlen;
}
}
free(cd);
}
/*整个过程:1.首先从根结点沿左子树一路向下,每个结点的权值用来标识该结点是否被访问过,weight初值为0,访问其左孩子则标记为1,
直到该结点的左孩子为0,这时考察该结点的右孩子是否也为0,为0说明该结点是叶子结点,此时可以将cd中的编码复制出来
2.如果该结点的右孩子不为0,则将c指向其右孩子,此时将该结点的weight值设为2,说明已访问该结点的右子树了。
3.如果该结点的标志位为2,则说明已经遍历该结点了,于是返回上一层。
4.这里工作空间cd存储编码的顺序是正向存储,通过cdlen=0的自增,自减操作实现
后面指针回退的时候感觉很像是二叉树的中序遍历
*/















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









