







Introduction
检索技术入门
Content
这里主要参照了一个检索的专栏, 11 ,方便我对检索有个初步的认知。
1. 基本认知
1.1 为什么检索难学?
一方面,经典教材大都太过理论化,和实际工作结合不紧密,学习难度太大。比如,《现代信息检索》和《信息检索导论》就是两本非常经典的书籍,但是大部分人都反馈读起它们来比较吃力,书中的内容组织和例子都和我们的实际工作有比较大的差距。
另一方面,和实际工作结合的教材,往往都是从某一行业的视角出发,全面介绍这个行业方方面面的所有技术,而不是专注于某一个基础技术。 比如数据库方面重点介绍模型, sql, 事务处理。 搜索引擎教材会介绍爬虫, 文本挖掘, 自然语言处理, 网页连接分析。
因此门槛比较高, 对于检索技术, 有理论有应用, 但是综合的比较少。
1.2 如何学习?
首先了解检索的基本数据结构等知识,之后理解一些工业界的解决方案, 最后系统的理解一些存储系统、搜索引擎、广告系统、推荐系统中如何应用到检索技术。
1.3 搜索的整体框架
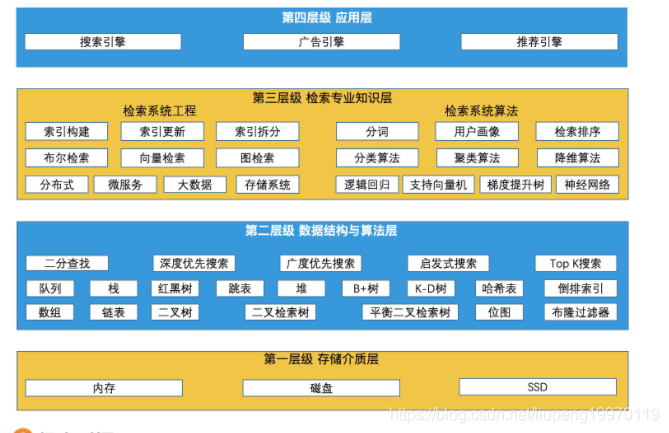
检索可以分为四层,硬件, 数据结构和算法, 检索专业知识成, 业务应用层。
2. 基础技术
- 对于无序数组,我们可以遍历检索。对于有序数组,我们可以用二分查找。链表具有灵活调整能力,适合用在数据频繁修改的场合, 此外还可以解决数据连续空间占用过多的问题。 因此可以通过多个链表将多组有序数组连接起来。 这样算一个高效的检索数据结构。
- 关于非线性结构、且数据频繁变化的检索, 例如文件目录, 使用二叉检索树或者跳表来做, 会比数组等好。
- 以上的检索方式是logn的, 那么如何更快呢? 显然哈希检索可以, 时间复杂度为1。但是这种方式只要被 Hash 的元素个数大于数组上限,就一定会产生冲突。如何利用开放寻址法解决 Hash 冲突?“线性探查” , 但是这样对后面插入的十分不利, 为了解决这个问题,我们可以使用“二次探查”(Quadratic Probing),改变i的长度为二次方。此外双散列也可以。 此外链式法也行。 尽管哈希表使用 Hash 值直接进行下标访问,带来了 O(1) 级别的查询能力,但是也失去了“有序存储”这个特点。
- 对于状态检索, 使用位图这种方式效果较好, 而且节省空间。通过位运算去做判断。 如果还想进行压缩, 就压缩数组长度, 但是这样容易产生哈希冲突, 这里我们使用布隆过滤器, 也就是通过多个哈希函数去降低冲突, **布隆过滤器不再使用一位来表示一个对象,而是使用 k 位来表示一个对象。这样两个对象的 k 位都相同的概率就会大大降低,从而能够解决哈希冲突的问题了。但是布隆过滤器存在覆盖产生的错误率问题, 但是这种可能存在的情况概率较小, 已经可以交给磁盘去做真正的判断了。 **虽然位图和布隆过滤器的原理和实现都非常简单,但是在许多复杂的大型系统中都可以见到它们的身影。
- 之前我们学习的都是正排索引, 倒排索引的核心其实并不复杂,它的具体实现其实是哈希表,只是它不是将文档 ID 或者题目作为 key,而是反过来,通过将内容或者属性作为 key 来存储对应的文档列表,使得我们能在 O(1) 的时间代价内完成查询。
3. 进阶实战
之前都是内存上的检索,接下来讨论一下借助磁盘完成存储和检索。我们熟悉的关系型数据库,比如 MySQL 和 Oracle,就是这样的典型系统。
- 关系数据库检索 : B+树的原理。 非关系数据库: LSM 树就是根据这个思路设计了这样一个机制:当数据写入时,延迟写磁盘,将数据先存放在内存中的树里,进行常规的存储和查询。当内存中的树持续变大达到阈值时,再批量地以块为单位写入磁盘的树中。
- 搜索引擎对万亿级别网页的索引,就是使用倒排索引实现的。,它会对万亿级别的网站进行索引,生成的倒排索引会非常庞大,根本无法存储在内存中。我们在前面加词典, 如果词典也很大, 加B+树管理词典。
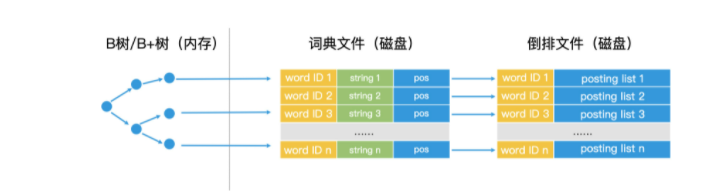
3. 分布式在搜索中的应用: 利用分布式技术,我们可以将倒排索引进行索引拆分。索引拆分的好处是:一方面是能将更多的索引数据加载到内存中,降低磁盘访问次数,使得检索效率能得到大幅度的提升;另一方面是基于文档的拆分,能将一个查询请求复制成多份,由多台索引服务器并行完成,单次检索的时间也能得到缩短。
4. 精准Top K 检索 : 在当前的主流搜索引擎中,用来打分的主要因子已经有几百种了。如果我们要将这么多的相关因子都考虑进来,再加入更多的参数,那 BM25 算法是无法满足我们的需求的。这个时候,机器学习就可以派上用场了。利用机器学习打分是近些年来比较热门的研究领域,也是许多搜索引擎目前正在使用的打分机制。并且,随着深度学习的发展,也演化出了越来越多的复杂打分算法,比如,使用深度神经网络模型(DNN)和相关的变种等。完成打分阶段之后,排序阶段我们要重视排序的效率。对于精准 Top K 检索,我们可以使用堆排序来代替全排序,只返回我们认为最重要的 k 个结果。这样,时间代价就是 O(n) + O(k log n) ,在数据量级非常大的情况下,它比 O(n log n) 的检索性能会高得多。
5. 非精准的 Top K 检索:高质量的检索结果并不一定要非常精准,我们只需要保证质量足够高的结果,被包含在最终的 Top K 个结果中就够了。非精准 Top K 检索实现加速的方法主要有三种,分别是根据静态质量得分排序截断,以及使用胜者表,利用词频进行相关性判断进行截断,还有使用分层索引,对一次查询请求进行两层检索。这三种方法的核心思路都是,尽可能地将计算从在线环节转移到离线环节,让我们在在线环节中,也就是在倒排检索的时候,只需要进行少量的判断,就能快速截断 Top K 个结果,从而大幅提升检索引擎的检索效率。
6. 最近邻检索:如果在搜索结果或者推荐结果中,我们将这些文章不加过滤就全部展现出来,那用户可能在第一页看到的都是几乎相同的内容。这样的话,用户的使用体验就会非常糟糕。因此,在搜索引擎和推荐引擎中,对相似文章去重是一个非常重要的环节。
3. 系统案例
搜索引擎:
- 搜索引擎你应该非常熟悉,它是我们学习和工作中非常重要的一个工具。它的特点是能在万亿级别的网页中,快速寻找出我们需要的信息。可以说,以搜索引擎为代表的检索技术,是所有基于文本和关键词的检索系统都可以学习和参考的。
- 搜索引擎的核心系统分为三部分,分别是爬虫系统、索引系统和检索系统。
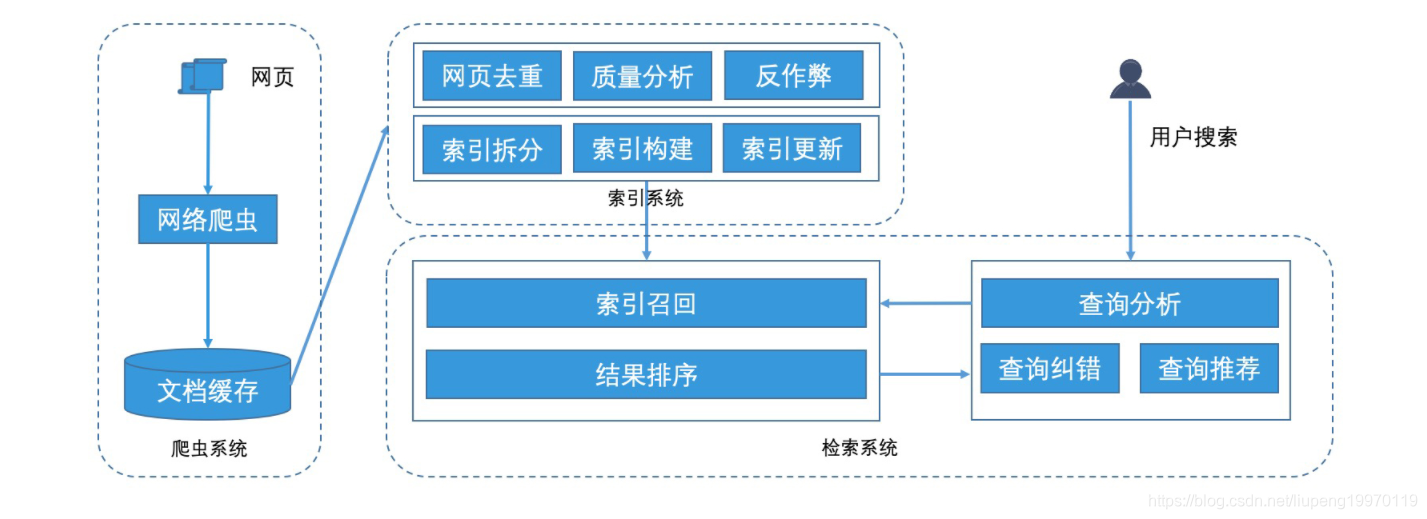
爬虫系统: 通过高性能的爬虫系统来完成持续的网页抓取,并且将抓取到的网页存入存储平台中。一般来说,我们可以将抓取到的网页存放在基于 LSM 树的 HBase 中,以便支持数据的高效读写。
索引系统 : 在爬虫系统抓取到网页之后,我们需要对这些网页进行一系列的处理,它们才可以变成可用的索引。处理可以分为两个阶段,首先是对网页进行预处理,主要的手段包括相似网页去重、网页质量分析、分词处理等工作,处理好网页之后,我们就要为搜索引擎生成索引,索引的生成过程主要可以分为三步。 1 对索引进行拆分(文档和网页分层两个方面) 2. 索引构建: 生成相应的倒排索引文件,每个倒排索引文件代表一个索引分片,它们都可以加载到线上的服务器中,来提供检索服务。 索引更新 : (不怎么了解)。 有了这样创建出来的索引之后,搜索引擎就可以为万亿级别的网页提供高效的检索服务了。
检索系统 : 用户搜索了一个关键词,检索系统 首先需要做查询分析,也就是通过分析查询词本身以及用户行为特征,找出用户的真实查询意图。如果发现查询词有误或者结果很少,搜索引擎还会进行拼写纠正或相关查询推荐,然后再以改写后的查询词去检索服务中查询结果。在检索服务中,搜索引擎会将查询词发送给相应的索引分片,索引分片通过倒排索引的检索机制,将自己所负责的分片结果返回。对于返回的结果,搜索引擎再根据相关性分析和质量分析,使用机器学习进行打分(离线式),选出 Top K 个结果(第 11 讲)来完成检索。搜索引擎最大的特点就是用户有明显的意图。 这和广告、推荐还不一样。
读后感
- 从这里面收获很多, 知道了索引的关键点, 之前学习mysql并不知道索引的具体发展, 从数组,链表, 哈希表, 二叉树, 红黑树, B+树, 倒排索引(根据value找key) 。 根据这个我知道了mysql的地位。
- 从指导性的理论知识,可以看出作者的总结广而深。 这才一个一直专攻一个技术点的转移性人才的水平, 到了这个地步, 怎么会怕内卷?这个领域涉及算法, 估计学历都不低。如果读博的话, 这种领域很合适。
- 如何从零开始搭建搜索呢? 期初我们可以用mysql的全文检索, 用户量几十万的时候可以上业界已经成熟的(大家都在用的)es, 基本上可以解决大多数问题了。 但是如果数据量太过庞大而且要定义功能, 肯定就要走上自研的路了。 例如用C++做一套服务。
- 这也是我第一次接触到深度学习应用广泛的领域,之前做的也是分类任务,但是这个是文本的分类工作。 之前没搞过, 但是特征的提取还是相似的。 希望以前学到的再这里面有用吧。 不过算法和工程好像没什么关系, 工程只需要排序的特征参数。
- 通过这个专栏, 我理解了检索的工作原理, 对搜索这个领域不是完全不知道。 下面就可以去再结合一门专门做搜索的书, 深入阅读搜索引擎的细节,理解业内的专业词汇。 中间可以通过es去练习。















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









