






简介
Seleninm: 能控制你的浏览器, 有模有样地学人类”看”网页
安装 Selenium
因为 Selenium 需要操控你的浏览器, 所以安装起来比传统的 Python 模块要多几步. 先在 terminal 或者 cmd 用 pip 安装 selenium.
在pycharm中直接安装即可。
使用插件Katalon Recorder
有一个非常好用的插件——Katalon Recorder,但是它只支持火狐浏览器,因此要先下一个火狐浏览器,然后下载插件Katalon Recorder。
这个插件能让你记录你使用浏览器的操作,Katalon Recorder 插件 + Selenium 就和按键精灵是一个意思. 记录你的操作, 然后你可以让电脑重复上千遍.
安装好火狐上的这个插件后, 打开它.
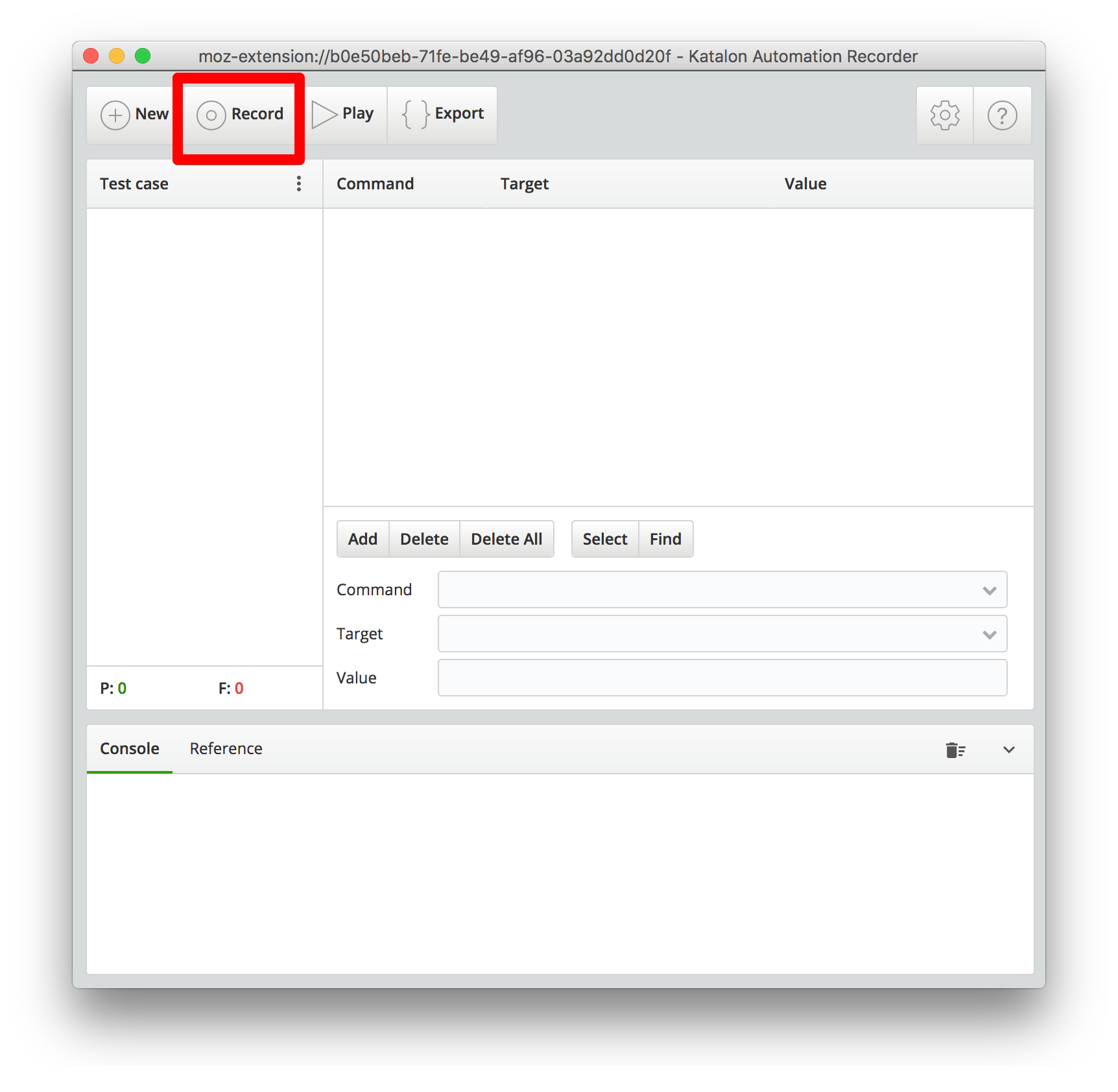
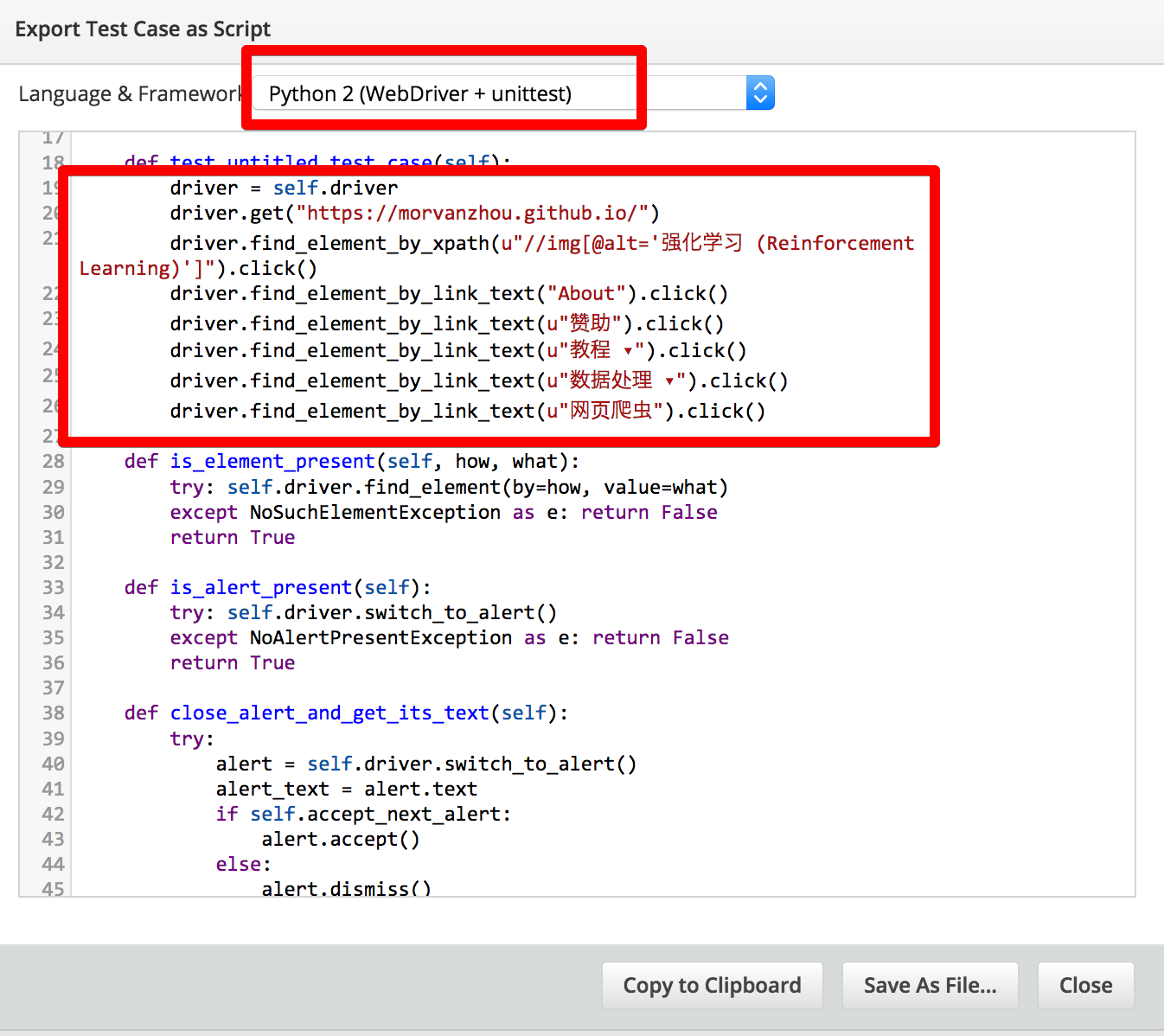
找到插件上的 record, 点它. 然后用火狐登录上 莫烦Python, 开始你的各种点击工作, 比如我的一连串操作是 (强化学习教程->About页面->赞助页面->教程->数据处理->网页爬虫)
每当你点击的时候, 插件就会记录下你这些点击, 形成一些log. 最后神奇的事情将要发生. 你可以点击 Export 按钮, 观看到帮你生成的浏览记录代码!
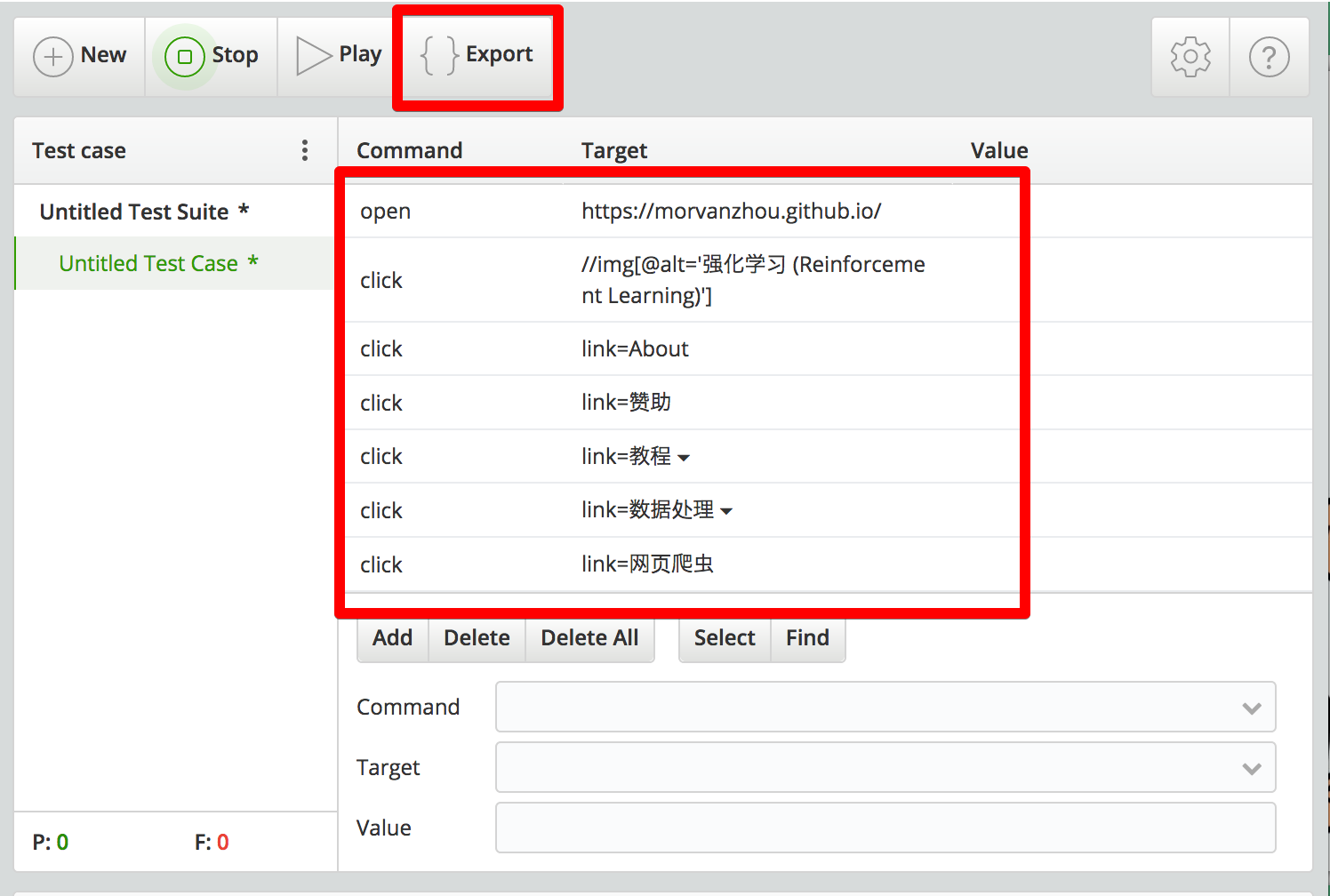
虽然这个代码输出只有 Python2 版本的, 不过不影响. 我们直接将这些圈起来的代码复制. 这将会是 python 帮你执行的行为代码.
Python 控制浏览器
好了, 有了这些代码, 我们就能回到 Python. 开始写 Python 的代码了. 这里十分简单! 我将 selenium 绑定到 Chrome 上 webdriver.Chrome(). 你可以绑其它的浏览器.
from selenium import webdriver
driver = webdriver.Chrome() # 打开 Chrome 浏览器
# 将刚刚复制的帖在这
driver.get("https://morvanzhou.github.io/")
driver.find_element_by_xpath(u"//img[@alt='强化学习 (Reinforcement Learning)']").click()
driver.find_element_by_link_text("About").click()
driver.find_element_by_link_text(u"赞助").click()
driver.find_element_by_link_text(u"教程 ▾").click()
driver.find_element_by_link_text(u"数据处理 ▾").click()
driver.find_element_by_link_text(u"网页爬虫").click()
# 得到网页 html, 还能截图
html = driver.page_source # get html
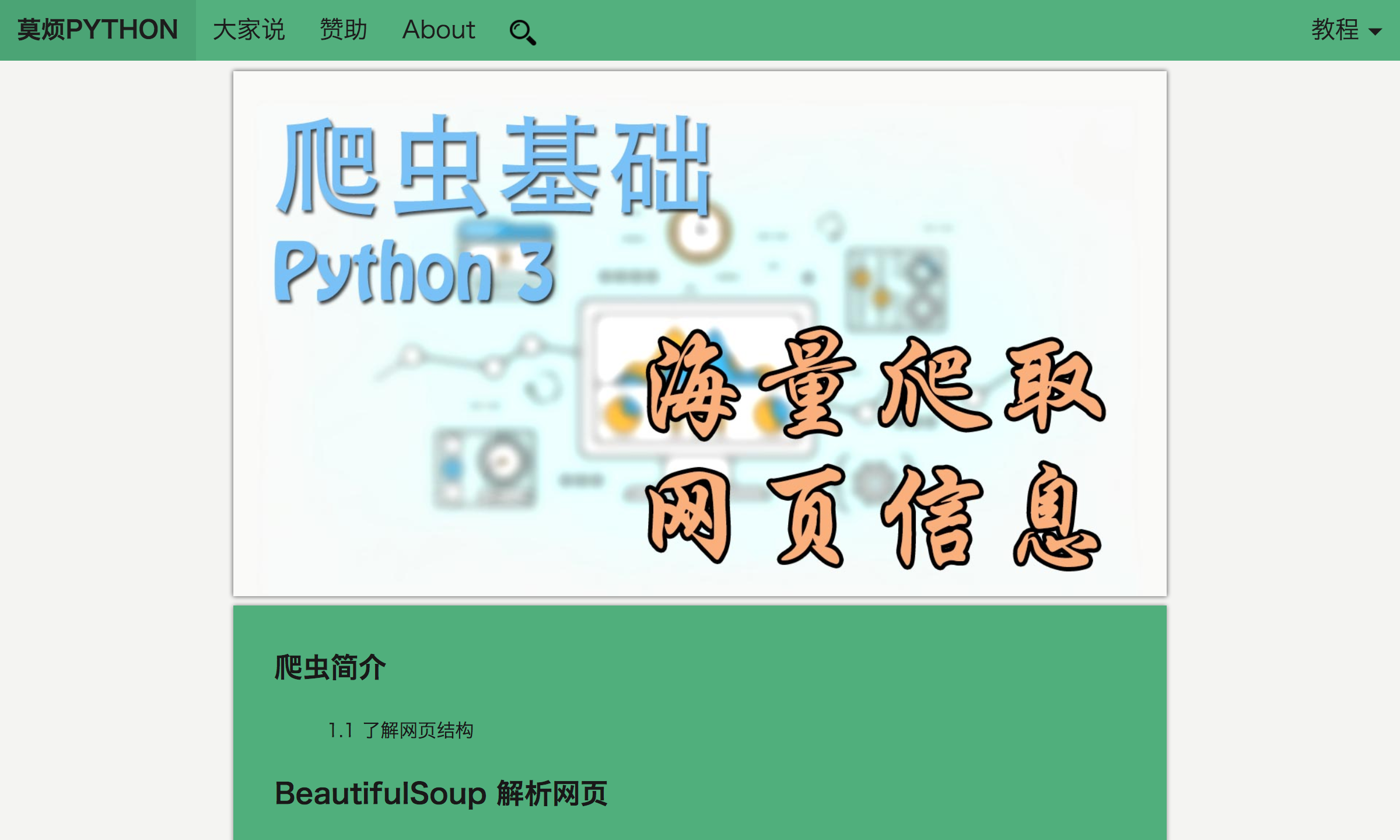
driver.get_screenshot_as_file("./img/sreenshot1.png")
driver.close()我们能得到页面的 html code (driver.page_source), 就能基于这个 code 来爬取数据了. 最后爬取的网页截图就是这样.
不过每次都要看着浏览器执行这些操作, 有时候有点不方便. 我们可以让 selenium 不弹出浏览器窗口, 让它”安静”地执行操作. 在创建 driver 之前定义几个参数就能摆脱浏览器的身体了.
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") # define headless
driver = webdriver.Chrome(chrome_options=chrome_options)
...最后同样再截一张图, 证明 driver 真的爬到了这个 “网页爬虫” 教程页面. 不过因为没有出现实体的浏览器, 这个页面大小和上面的图片还是有点差别的.

Selenium 能做的事还有很多, 比如填 Form 表单, 超控键盘等等. 这个教程不会细说了, 只是个入门, 如果你还想继续深入了解, 欢迎点进去他们的 Python 教学官网.
最后, Selenium 的优点我们都看出来了, 可以很方便的帮你模拟你的操作, 添加其它操作也是非常容易的, 但是也是有缺点的, 不是任何时候 selenium 都很好. 因为要打开浏览器, 加载更多东西, 它的执行速度肯定没有其它模块快. 所以如果你需要速度, 能不用 Selenium, 就不用吧.















 9266
9266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









