






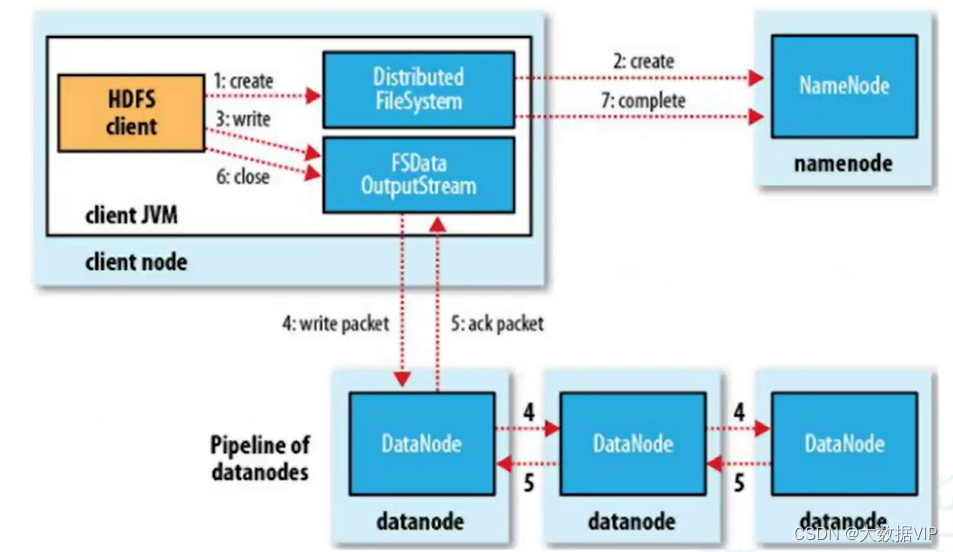
HDFS写数据流程(客户端如何把数据写入到HDFS集群中)
1.HDFS client客户端访问HDFS会先创建一个Distributed System(分布式文件系统)对象,向NameNode发出请求上传文件,NameNode会检查自己的目录树来判断是否有权限或者有改目录存在。
2.NameNode校验完成会把DataNode首地址信息回传给客户端。
3.客户端会创建一个FSDataOutputeStream数据流往刚才NameNode回传的首地址DataNode上面写入数据,因为它自身的克隆能力,会在同一个机架上面选择一个DataNode以包的形式传递,写好之后会以包的形式传递给相邻机架上的DataNode,所以一共会存储三份节点数据(存储的单位都是Block,默认的size时128M)。
4.写好之后,后面两个节点会把写入位置回传给主节点,主节点会将三份地址信息全部回传给客户端。
5.最后客户端会通知NameNode,将三个地址写入到目录索引里面。
6.注意点:存储文件的Block Szie默认设置128M,如果文件不大不满128M也是占128M的空间,如果文件大小超过了128M,会进行数据切割,随机存储在节点上面。
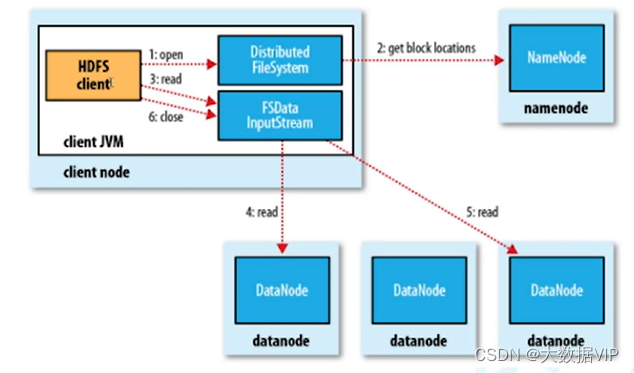
HDFS读数据流程(客户端如何从HDFS集群中读取数据)
1.HDFS client 客户端从DHFS读取数据,会先创建Distributed System对象,向NameNode提交搜索文件请求,NameNode会检查自己的目录树是否存在这个目录索引。
2.NameNode会把数据节点地址回传给客户端,客户端会创建FSDataInputStream对象去该数据节点上面读取数据。收到的地址信息时三份,会按照就近的DataNode上面读取数据,如果就近的数据节点负载过大(负载均衡原则),会从其他节点读取数据源。读取数据的原则是串行读取数据,不是并发读取的。
3.最后读取完毕,关闭流。
Block为什么不能设置太大也不能设置太小
1.HDFS的块如果设置太小的话,存储的数据会被切割的很碎存在各个数据节点上面,后面查询数据非常消耗时间。
2.HDFS的块如果设置太大的话,从磁盘传输数据的时间会明显大于定位这个块的开始位置所需的时间,导致成勋在处理这块数据的时候会发非常慢。
3.总结:HDFS的块大小设置主要取决于磁盘的传输效率,正常设置128M或者256M















 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









